 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating User Perception of Speech Recognition System Quality with Semantic Distance Metric
Oct 11, 2021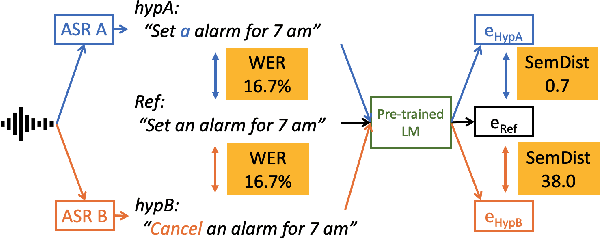
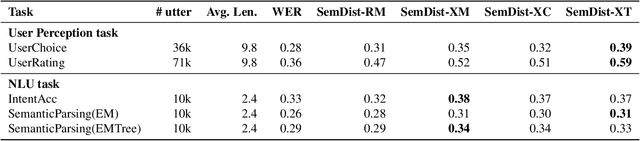
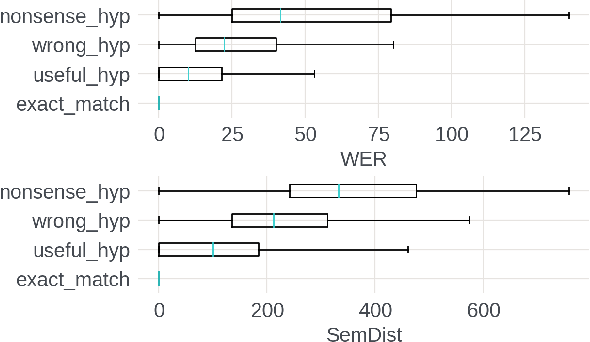
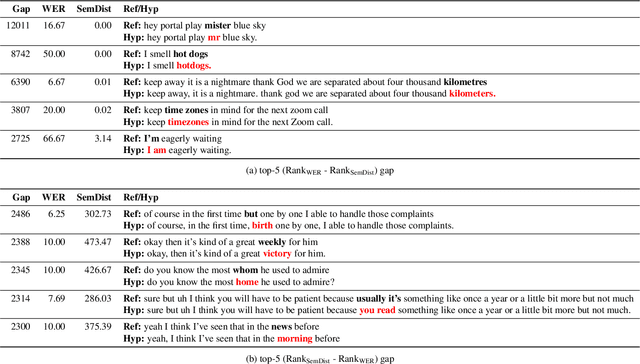
Measuring automatic speech recognition (ASR) system quality is critical for creating user-satisfying voice-driven applications. Word Error Rate (WER) has been traditionally used to evaluate ASR system quality; however, it sometimes correlates poorly with user perception of transcription quality. This is because WER weighs every word equally and does not consider semantic correctness which has a higher impact on user perception. In this work, we propose evaluating ASR output hypotheses quality with SemDist that can measure semantic correctness by using the distance between the semantic vectors of the reference and hypothesis extracted from a pre-trained language model. Our experimental results of 71K and 36K user annotated ASR output quality show that SemDist achieves higher correlation with user perception than WER. We also show that SemDist has higher correlation with downstream NLU tasks than WER.
Span Pointer Networks for Non-Autoregressive Task-Oriented Semantic Parsing
Apr 16, 2021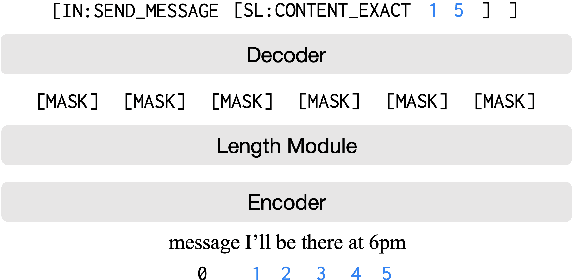

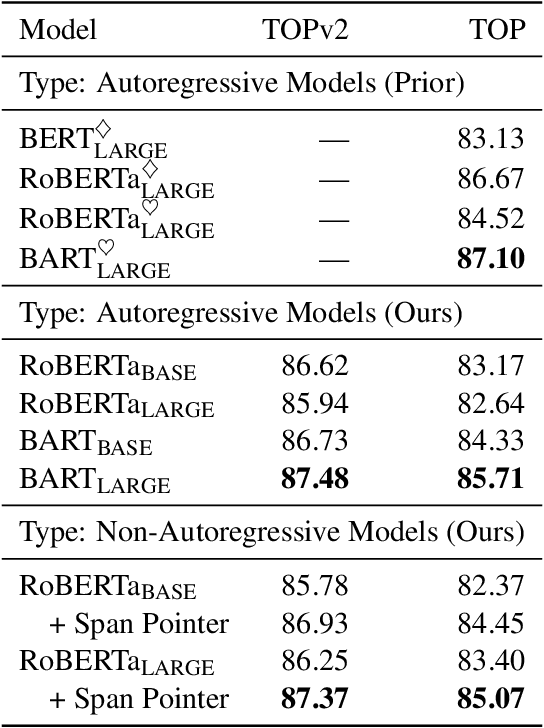
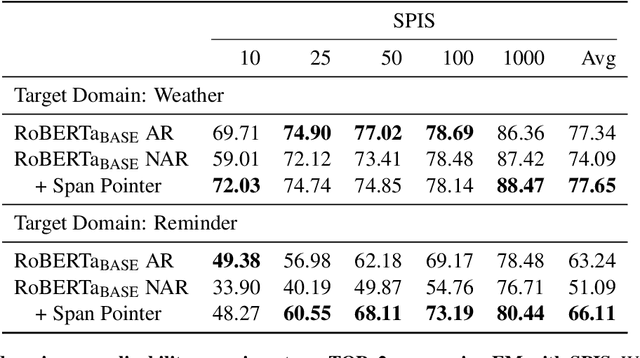
An effective recipe for building seq2seq, non-autoregressive, task-oriented parsers to map utterances to semantic frames proceeds in three steps: encoding an utterance $x$, predicting a frame's length |y|, and decoding a |y|-sized frame with utterance and ontology tokens. Though empirically strong, these models are typically bottlenecked by length prediction, as even small inaccuracies change the syntactic and semantic characteristics of resulting frames. In our work, we propose span pointer networks, non-autoregressive parsers which shift the decoding task from text generation to span prediction; that is, when imputing utterance spans into frame slots, our model produces endpoints (e.g., [i, j]) as opposed to text (e.g., "6pm"). This natural quantization of the output space reduces the variability of gold frames, therefore improving length prediction and, ultimately, exact match. Furthermore, length prediction is now responsible for frame syntax and the decoder is responsible for frame semantics, resulting in a coarse-to-fine model. We evaluate our approach on several task-oriented semantic parsing datasets. Notably, we bridge the quality gap between non-autogressive and autoregressive parsers, achieving 87 EM on TOPv2 (Chen et al. 2020). Furthermore, due to our more consistent gold frames, we show strong improvements in model generalization in both cross-domain and cross-lingual transfer in low-resource settings. Finally, due to our diminished output vocabulary, we observe 70% reduction in latency and 83% reduction in memory at beam size 5 compared to prior non-autoregressive parsers.
Semantic Distance: A New Metric for ASR Performance Analysis Towards Spoken Language Understanding
Apr 05, 2021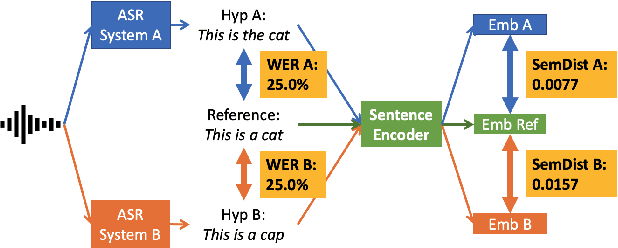

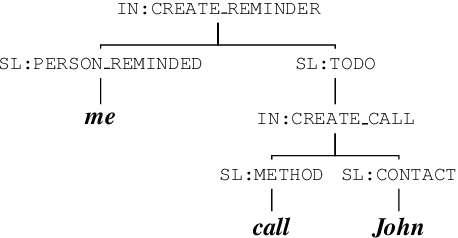

Word Error Rate (WER) has been the predominant metric used to evaluate the performance of automatic speech recognition (ASR) systems. However, WER is sometimes not a good indicator for downstream Natural Language Understanding (NLU) tasks, such as intent recognition, slot filling, and semantic parsing in task-oriented dialog systems. This is because WER takes into consideration only literal correctness instead of semantic correctness, the latter of which is typically more important for these downstream tasks. In this study, we propose a novel Semantic Distance (SemDist) measure as an alternative evaluation metric for ASR systems to address this issue. We define SemDist as the distance between a reference and hypothesis pair in a sentence-level embedding space. To represent the reference and hypothesis as a sentence embedding, we exploit RoBERTa, a state-of-the-art pre-trained deep contextualized language model based on the transformer architecture. We demonstrate the effectiveness of our proposed metric on various downstream tasks, including intent recognition, semantic parsing, and named entity recognition.
El Volumen Louder Por Favor: Code-switching in Task-oriented Semantic Parsing
Jan 28, 2021
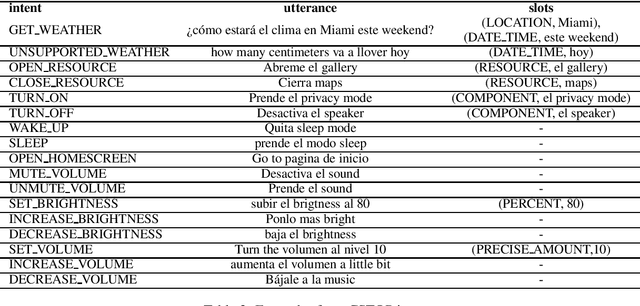
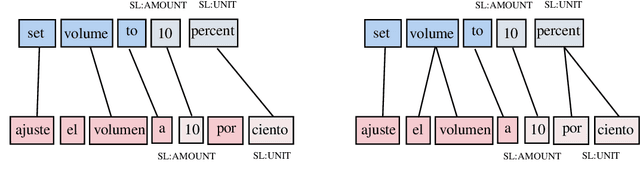
Being able to parse code-switched (CS) utterances, such as Spanish+English or Hindi+English, is essential to democratize task-oriented semantic parsing systems for certain locales. In this work, we focus on Spanglish (Spanish+English) and release a dataset, CSTOP, containing 5800 CS utterances alongside their semantic parses. We examine the CS generalizability of various Cross-lingual (XL) models and exhibit the advantage of pre-trained XL language models when data for only one language is present. As such, we focus on improving the pre-trained models for the case when only English corpus alongside either zero or a few CS training instances are available. We propose two data augmentation methods for the zero-shot and the few-shot settings: fine-tune using translate-and-align and augment using a generation model followed by match-and-filter. Combining the few-shot setting with the above improvements decreases the initial 30-point accuracy gap between the zero-shot and the full-data settings by two thirds.
MTOP: A Comprehensive Multilingual Task-Oriented Semantic Parsing Benchmark
Aug 21, 2020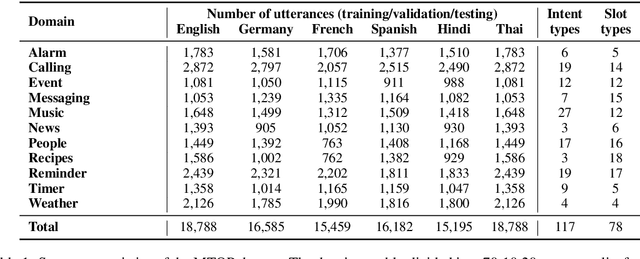
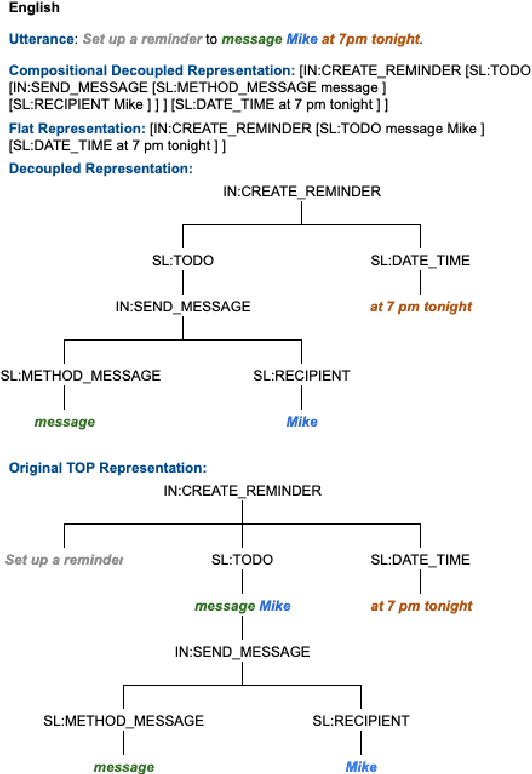
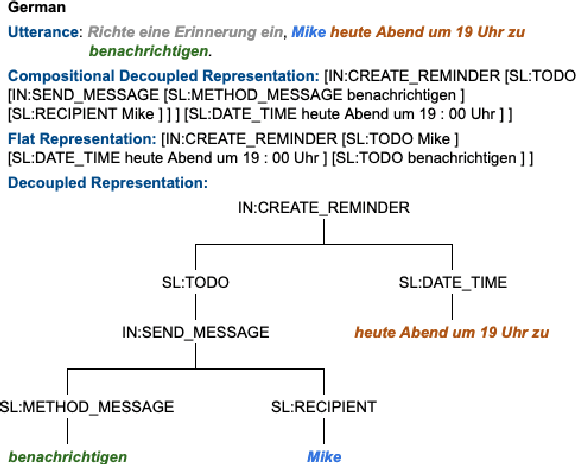
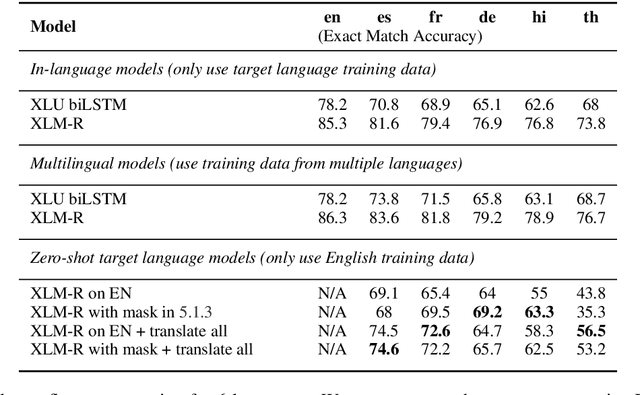
Scaling semantic parsing models for task-oriented dialog systems to new languages is often expensive and time-consuming due to the lack of available datasets. Even though few datasets are available, they suffer from many shortcomings: a) they contain few languages and small amounts of labeled data for other languages b) they are based on the simple intent and slot detection paradigm for non-compositional queries. In this paper, we present a new multilingual dataset, called MTOP, comprising of 100k annotated utterances in 6 languages across 11 domains. We use this dataset and other publicly available datasets to conduct a comprehensive benchmarking study on using various state-of-the-art multilingual pre-trained models for task-oriented semantic parsing. We achieve an average improvement of +6.3\% on Slot F1 for the two existing multilingual datasets, over best results reported in their experiments. Furthermore, we also demonstrate strong zero-shot performance using pre-trained models combined with automatic translation and alignment, and a proposed distant supervision method to reduce the noise in slot label projection.
Likelihood Ratios and Generative Classifiers for Unsupervised Out-of-Domain Detection In Task Oriented Dialog
Dec 30, 2019


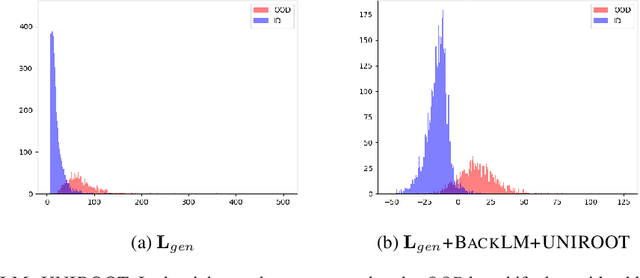
The task of identifying out-of-domain (OOD) input examples directly at test-time has seen renewed interest recently due to increased real world deployment of models. In this work, we focus on OOD detection for natural language sentence inputs to task-based dialog systems. Our findings are three-fold: First, we curate and release ROSTD (Real Out-of-Domain Sentences From Task-oriented Dialog) - a dataset of 4K OOD examples for the publicly available dataset from (Schuster et al. 2019). In contrast to existing settings which synthesize OOD examples by holding out a subset of classes, our examples were authored by annotators with apriori instructions to be out-of-domain with respect to the sentences in an existing dataset. Second, we explore likelihood ratio based approaches as an alternative to currently prevalent paradigms. Specifically, we reformulate and apply these approaches to natural language inputs. We find that they match or outperform the latter on all datasets, with larger improvements on non-artificial OOD benchmarks such as our dataset. Our ablations validate that specifically using likelihood ratios rather than plain likelihood is necessary to discriminate well between OOD and in-domain data. Third, we propose learning a generative classifier and computing a marginal likelihood (ratio) for OOD detection. This allows us to use a principled likelihood while at the same time exploiting training-time labels. We find that this approach outperforms both simple likelihood (ratio) based and other prior approaches. We are hitherto the first to investigate the use of generative classifiers for OOD detection at test-time.
Design and Development of Underwater Vehicle: ANAHITA
Mar 01, 2019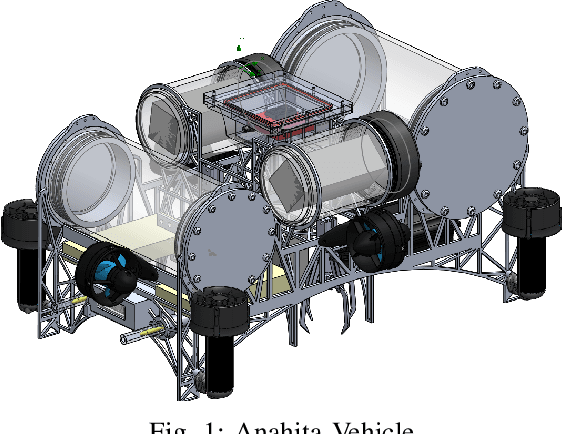
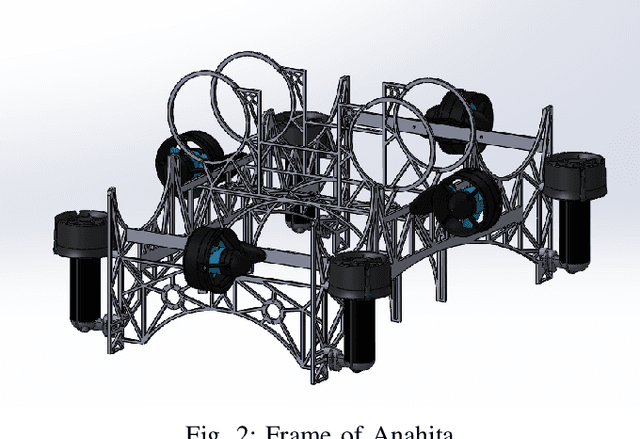

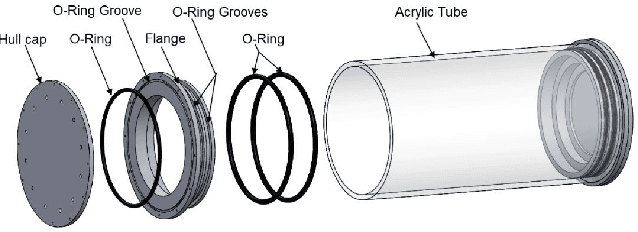
Anahita is an autonomous underwater vehicle which is currently being developed by interdisciplinary team of students at Indian Institute of Technology(IIT) Kanpur with aim to provide a platform for research in AUV to undergraduate students. This is the second vehicle which is being designed by AUV-IITK team to participate in 6th NIOT-SAVe competition organized by the National Institute of Ocean Technology, Chennai. The Vehicle has been completely redesigned with the major improvements in modularity and ease of access of all the components, keeping the design very compact and efficient. New advancements in the vehicle include, power distribution system and monitoring system. The sensors include the inertial measurement units (IMU), hydrophone array, a depth sensor, and two RGB cameras. The current vehicle features hot swappable battery pods giving a huge advantage over the previous vehicle, for longer runtime.
PyText: A Seamless Path from NLP research to production
Dec 12, 2018



We introduce PyText - a deep learning based NLP modeling framework built on PyTorch. PyText addresses the often-conflicting requirements of enabling rapid experimentation and of serving models at scale. It achieves this by providing simple and extensible interfaces for model components, and by using PyTorch's capabilities of exporting models for inference via the optimized Caffe2 execution engine. We report our own experience of migrating experimentation and production workflows to PyText, which enabled us to iterate faster on novel modeling ideas and then seamlessly ship them at industrial scale.