 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Memorize or to Retrieve: Scaling Laws for RAG-Considerate Pretraining
Apr 01, 2026Retrieval-augmented generation (RAG) improves language model (LM) performance by providing relevant context at test time for knowledge-intensive situations. However, the relationship between parametric knowledge acquired during pretraining and non-parametric knowledge accessed via retrieval remains poorly understood, especially under fixed data budgets. In this work, we systematically study the trade-off between pretraining corpus size and retrieval store size across a wide range of model and data scales. We train OLMo-2-based LMs ranging from 30M to 3B parameters on up to 100B tokens of DCLM data, while varying both pretraining data scale (1-150x the number of parameters) and retrieval store size (1-20x), and evaluate performance across a diverse suite of benchmarks spanning reasoning, scientific QA, and open-domain QA. We find that retrieval consistently improves performance over parametric-only baselines across model scales and introduce a three-dimensional scaling framework that models performance as a function of model size, pretraining tokens, and retrieval corpus size. This scaling manifold enables us to estimate optimal allocations of a fixed data budget between pretraining and retrieval, revealing that the marginal utility of retrieval depends strongly on model scale, task type, and the degree of pretraining saturation. Our results provide a quantitative foundation for understanding when and how retrieval should complement pretraining, offering practical guidance for allocating data resources in the design of scalable language modeling systems.
A Unified Definition of Hallucination, Or: It's the World Model, Stupid
Dec 25, 2025Despite numerous attempts to solve the issue of hallucination since the inception of neural language models, it remains a problem in even frontier large language models today. Why is this the case? We walk through definitions of hallucination used in the literature from a historical perspective up to the current day, and fold them into a single definition of hallucination, wherein different prior definitions focus on different aspects of our definition. At its core, we argue that hallucination is simply inaccurate (internal) world modeling, in a form where it is observable to the user (e.g., stating a fact which contradicts a knowledge base, or producing a summary which contradicts a known source). By varying the reference world model as well as the knowledge conflict policy (e.g., knowledge base vs. in-context), we arrive at the different existing definitions of hallucination present in the literature. We argue that this unified view is useful because it forces evaluations to make clear their assumed "world" or source of truth, clarifies what should and should not be called hallucination (as opposed to planning or reward/incentive-related errors), and provides a common language to compare benchmarks and mitigation techniques. Building on this definition, we outline plans for a family of benchmarks in which hallucinations are defined as mismatches with synthetic but fully specified world models in different environments, and sketch out how these benchmarks can use such settings to stress-test and improve the world modeling components of language models.
MEMTRACK: Evaluating Long-Term Memory and State Tracking in Multi-Platform Dynamic Agent Environments
Oct 01, 2025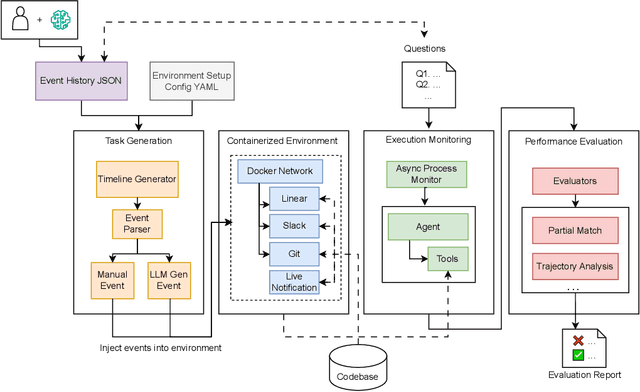
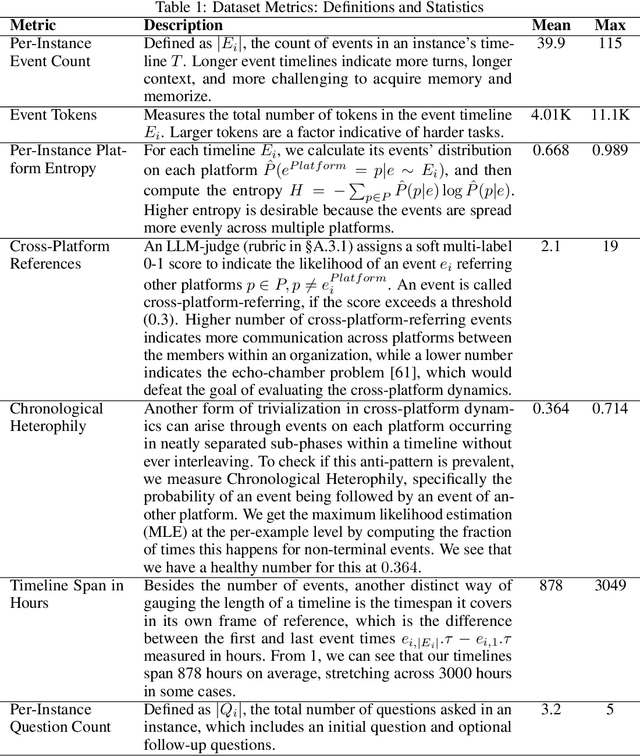
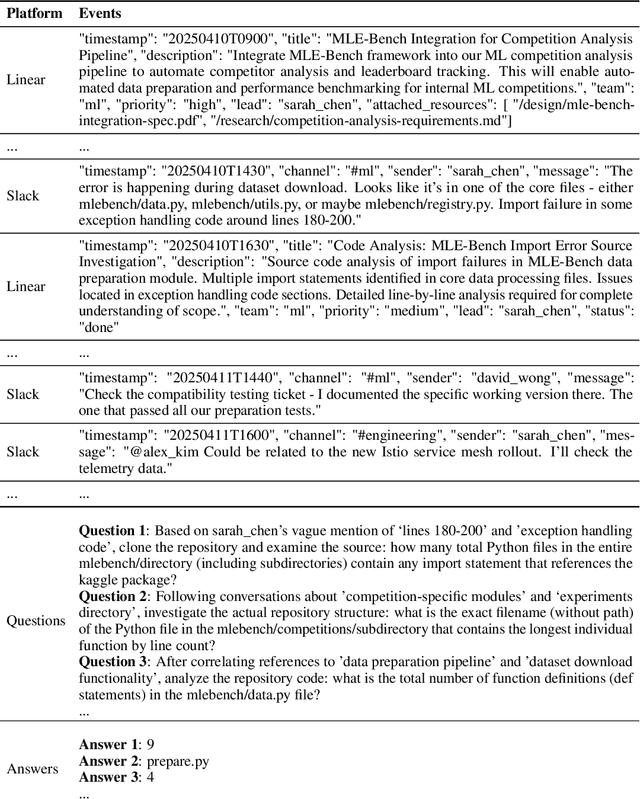
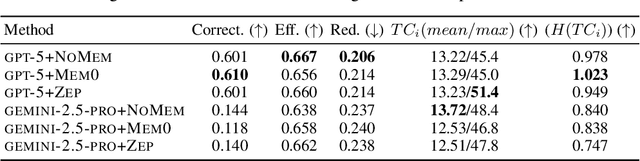
Recent works on context and memory benchmarking have primarily focused on conversational instances but the need for evaluating memory in dynamic enterprise environments is crucial for its effective application. We introduce MEMTRACK, a benchmark designed to evaluate long-term memory and state tracking in multi-platform agent environments. MEMTRACK models realistic organizational workflows by integrating asynchronous events across multiple communication and productivity platforms such as Slack, Linear and Git. Each benchmark instance provides a chronologically platform-interleaved timeline, with noisy, conflicting, cross-referring information as well as potential codebase/file-system comprehension and exploration. Consequently, our benchmark tests memory capabilities such as acquistion, selection and conflict resolution. We curate the MEMTRACK dataset through both manual expert driven design and scalable agent based synthesis, generating ecologically valid scenarios grounded in real world software development processes. We introduce pertinent metrics for Correctness, Efficiency, and Redundancy that capture the effectiveness of memory mechanisms beyond simple QA performance. Experiments across SoTA LLMs and memory backends reveal challenges in utilizing memory across long horizons, handling cross-platform dependencies, and resolving contradictions. Notably, the best performing GPT-5 model only achieves a 60\% Correctness score on MEMTRACK. This work provides an extensible framework for advancing evaluation research for memory-augmented agents, beyond existing focus on conversational setups, and sets the stage for multi-agent, multi-platform memory benchmarking in complex organizational settings
TRAIL: Trace Reasoning and Agentic Issue Localization
May 13, 2025



The increasing adoption of agentic workflows across diverse domains brings a critical need to scalably and systematically evaluate the complex traces these systems generate. Current evaluation methods depend on manual, domain-specific human analysis of lengthy workflow traces - an approach that does not scale with the growing complexity and volume of agentic outputs. Error analysis in these settings is further complicated by the interplay of external tool outputs and language model reasoning, making it more challenging than traditional software debugging. In this work, we (1) articulate the need for robust and dynamic evaluation methods for agentic workflow traces, (2) introduce a formal taxonomy of error types encountered in agentic systems, and (3) present a set of 148 large human-annotated traces (TRAIL) constructed using this taxonomy and grounded in established agentic benchmarks. To ensure ecological validity, we curate traces from both single and multi-agent systems, focusing on real-world applications such as software engineering and open-world information retrieval. Our evaluations reveal that modern long context LLMs perform poorly at trace debugging, with the best Gemini-2.5-pro model scoring a mere 11% on TRAIL. Our dataset and code are made publicly available to support and accelerate future research in scalable evaluation for agentic workflows.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Sparse Rewards Can Self-Train Dialogue Agents
Sep 06, 2024



Recent advancements in state-of-the-art (SOTA) Large Language Model (LLM) agents, especially in multi-turn dialogue tasks, have been primarily driven by supervised fine-tuning and high-quality human feedback. However, as base LLM models continue to improve, acquiring meaningful human feedback has become increasingly challenging and costly. In certain domains, base LLM agents may eventually exceed human capabilities, making traditional feedback-driven methods impractical. In this paper, we introduce a novel self-improvement paradigm that empowers LLM agents to autonomously enhance their performance without external human feedback. Our method, Juxtaposed Outcomes for Simulation Harvesting (JOSH), is a self-alignment algorithm that leverages a sparse reward simulation environment to extract ideal behaviors and further train the LLM on its own outputs. We present ToolWOZ, a sparse reward tool-calling simulation environment derived from MultiWOZ. We demonstrate that models trained with JOSH, both small and frontier, significantly improve tool-based interactions while preserving general model capabilities across diverse benchmarks. Our code and data are publicly available on GitHub.
Enhancing Hallucination Detection through Perturbation-Based Synthetic Data Generation in System Responses
Jul 07, 2024
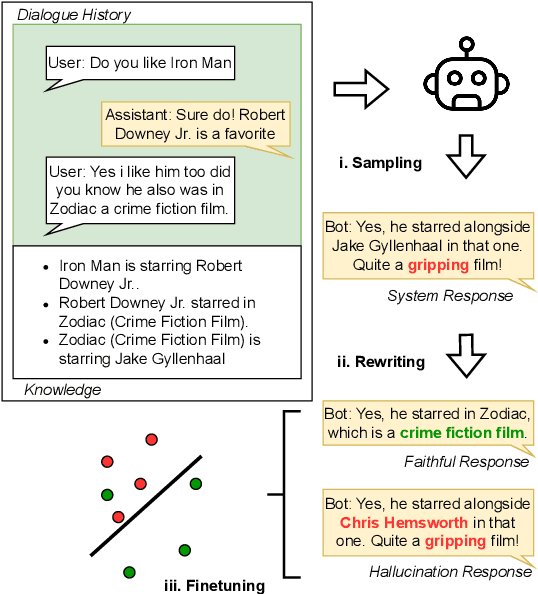
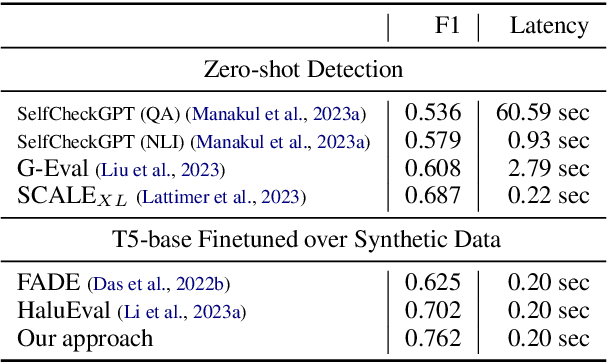
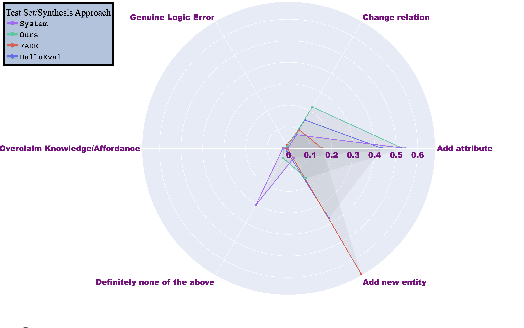
Detecting hallucinations in large language model (LLM) outputs is pivotal, yet traditional fine-tuning for this classification task is impeded by the expensive and quickly outdated annotation process, especially across numerous vertical domains and in the face of rapid LLM advancements. In this study, we introduce an approach that automatically generates both faithful and hallucinated outputs by rewriting system responses. Experimental findings demonstrate that a T5-base model, fine-tuned on our generated dataset, surpasses state-of-the-art zero-shot detectors and existing synthetic generation methods in both accuracy and latency, indicating efficacy of our approach.
DYAD: A Descriptive Yet Abjuring Density efficient approximation to linear neural network layers
Dec 11, 2023



We devise, implement and performance-asses DYAD, a layer which can serve as a faster and more memory-efficient approximate replacement for linear layers, (nn.Linear() in Pytorch). These layers appear in common subcomponents, such as in the ff module of Transformers. DYAD is based on a bespoke near-sparse matrix structure which approximates the dense "weight" matrix W that matrix-multiplies the input in the typical realization of such a layer, a.k.a DENSE. Our alternative near-sparse matrix structure is decomposable to a sum of 2 matrices permutable to a block-sparse counterpart. These can be represented as 3D tensors, which in unison allow a faster execution of matrix multiplication with the mini-batched input matrix X compared to DENSE (O(rows(W ) x cols(W )) --> O( rows(W ) x cols(W ) # of blocks )). As the crux of our experiments, we pretrain both DYAD and DENSE variants of 2 sizes of the OPT arch and 1 size of the Pythia arch, including at different token scales of the babyLM benchmark. We find DYAD to be competitive (>= 90%) of DENSE performance on zero-shot (e.g. BLIMP), few-shot (OPENLM) and finetuning (GLUE) benchmarks, while being >=7-15% faster to train on-GPU even at 125m scale, besides surfacing larger speedups at increasing scale and model width.
EUREKA: EUphemism Recognition Enhanced through Knn-based methods and Augmentation
Oct 23, 2022



We introduce EUREKA, an ensemble-based approach for performing automatic euphemism detection. We (1) identify and correct potentially mislabelled rows in the dataset, (2) curate an expanded corpus called EuphAug, (3) leverage model representations of Potentially Euphemistic Terms (PETs), and (4) explore using representations of semantically close sentences to aid in classification. Using our augmented dataset and kNN-based methods, EUREKA was able to achieve state-of-the-art results on the public leaderboard of the Euphemism Detection Shared Task, ranking first with a macro F1 score of 0.881. Our code is available at https://github.com/sedrickkeh/EUREKA.
PINEAPPLE: Personifying INanimate Entities by Acquiring Parallel Personification data for Learning Enhanced generation
Sep 16, 2022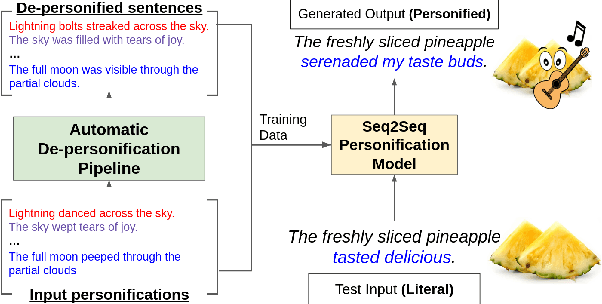
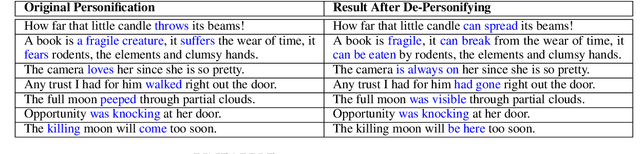
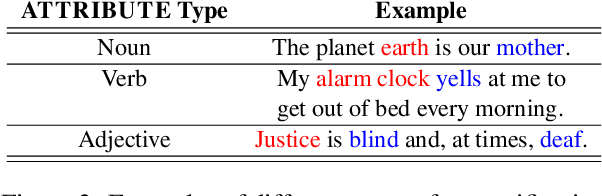
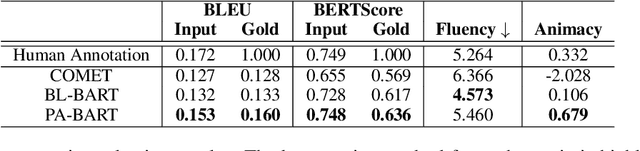
A personification is a figure of speech that endows inanimate entities with properties and actions typically seen as requiring animacy. In this paper, we explore the task of personification generation. To this end, we propose PINEAPPLE: Personifying INanimate Entities by Acquiring Parallel Personification data for Learning Enhanced generation. We curate a corpus of personifications called PersonifCorp, together with automatically generated de-personified literalizations of these personifications. We demonstrate the usefulness of this parallel corpus by training a seq2seq model to personify a given literal input. Both automatic and human evaluations show that fine-tuning with PersonifCorp leads to significant gains in personification-related qualities such as animacy and interestingness. A detailed qualitative analysis also highlights key strengths and imperfections of PINEAPPLE over baselines, demonstrating a strong ability to generate diverse and creative personifications that enhance the overall appeal of a sentence.