 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere It Really Matters: Few-Shot Environmental Conservation Media Monitoring for Low-Resource Languages
Feb 19, 2024



Environmental conservation organizations routinely monitor news content on conservation in protected areas to maintain situational awareness of developments that can have an environmental impact. Existing automated media monitoring systems require large amounts of data labeled by domain experts, which is only feasible at scale for high-resource languages like English. However, such tools are most needed in the global south where news of interest is mainly in local low-resource languages, and far fewer experts are available to annotate datasets sustainably. In this paper, we propose NewsSerow, a method to automatically recognize environmental conservation content in low-resource languages. NewsSerow is a pipeline of summarization, in-context few-shot classification, and self-reflection using large language models (LLMs). Using at most 10 demonstration example news articles in Nepali, NewsSerow significantly outperforms other few-shot methods and achieves comparable performance with models fully fine-tuned using thousands of examples. The World Wide Fund for Nature (WWF) has deployed NewsSerow for media monitoring in Nepal, significantly reducing their operational burden, and ensuring that AI tools for conservation actually reach the communities that need them the most. NewsSerow has also been deployed for countries with other languages like Colombia.
NewsPanda: Media Monitoring for Timely Conservation Action
Apr 30, 2023Non-governmental organizations for environmental conservation have a significant interest in monitoring conservation-related media and getting timely updates about infrastructure construction projects as they may cause massive impact to key conservation areas. Such monitoring, however, is difficult and time-consuming. We introduce NewsPanda, a toolkit which automatically detects and analyzes online articles related to environmental conservation and infrastructure construction. We fine-tune a BERT-based model using active learning methods and noise correction algorithms to identify articles that are relevant to conservation and infrastructure construction. For the identified articles, we perform further analysis, extracting keywords and finding potentially related sources. NewsPanda has been successfully deployed by the World Wide Fund for Nature teams in the UK, India, and Nepal since February 2022. It currently monitors over 80,000 websites and 1,074 conservation sites across India and Nepal, saving more than 30 hours of human efforts weekly. We have now scaled it up to cover 60,000 conservation sites globally.
Hashtag-Guided Low-Resource Tweet Classification
Feb 20, 2023
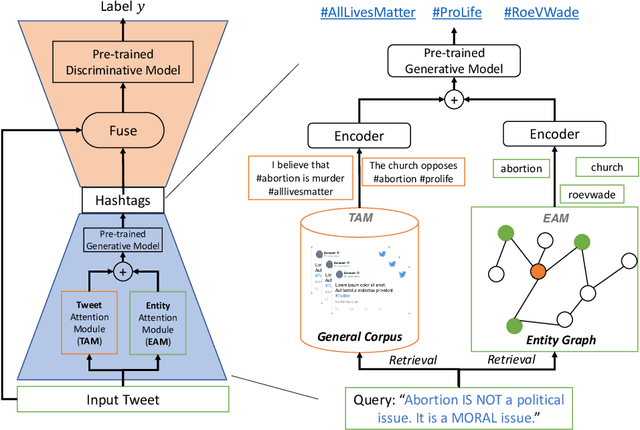

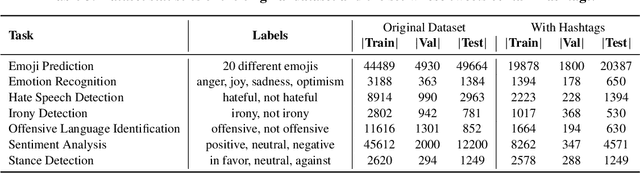
Social media classification tasks (e.g., tweet sentiment analysis, tweet stance detection) are challenging because social media posts are typically short, informal, and ambiguous. Thus, training on tweets is challenging and demands large-scale human-annotated labels, which are time-consuming and costly to obtain. In this paper, we find that providing hashtags to social media tweets can help alleviate this issue because hashtags can enrich short and ambiguous tweets in terms of various information, such as topic, sentiment, and stance. This motivates us to propose a novel Hashtag-guided Tweet Classification model (HashTation), which automatically generates meaningful hashtags for the input tweet to provide useful auxiliary signals for tweet classification. To generate high-quality and insightful hashtags, our hashtag generation model retrieves and encodes the post-level and entity-level information across the whole corpus. Experiments show that HashTation achieves significant improvements on seven low-resource tweet classification tasks, in which only a limited amount of training data is provided, showing that automatically enriching tweets with model-generated hashtags could significantly reduce the demand for large-scale human-labeled data. Further analysis demonstrates that HashTation is able to generate high-quality hashtags that are consistent with the tweets and their labels. The code is available at https://github.com/shizhediao/HashTation.
Exploring Euphemism Detection in Few-Shot and Zero-Shot Settings
Oct 24, 2022

This work builds upon the Euphemism Detection Shared Task proposed in the EMNLP 2022 FigLang Workshop, and extends it to few-shot and zero-shot settings. We demonstrate a few-shot and zero-shot formulation using the dataset from the shared task, and we conduct experiments in these settings using RoBERTa and GPT-3. Our results show that language models are able to classify euphemistic terms relatively well even on new terms unseen during training, indicating that it is able to capture higher-level concepts related to euphemisms.
EUREKA: EUphemism Recognition Enhanced through Knn-based methods and Augmentation
Oct 23, 2022



We introduce EUREKA, an ensemble-based approach for performing automatic euphemism detection. We (1) identify and correct potentially mislabelled rows in the dataset, (2) curate an expanded corpus called EuphAug, (3) leverage model representations of Potentially Euphemistic Terms (PETs), and (4) explore using representations of semantically close sentences to aid in classification. Using our augmented dataset and kNN-based methods, EUREKA was able to achieve state-of-the-art results on the public leaderboard of the Euphemism Detection Shared Task, ranking first with a macro F1 score of 0.881. Our code is available at https://github.com/sedrickkeh/EUREKA.
PINEAPPLE: Personifying INanimate Entities by Acquiring Parallel Personification data for Learning Enhanced generation
Sep 16, 2022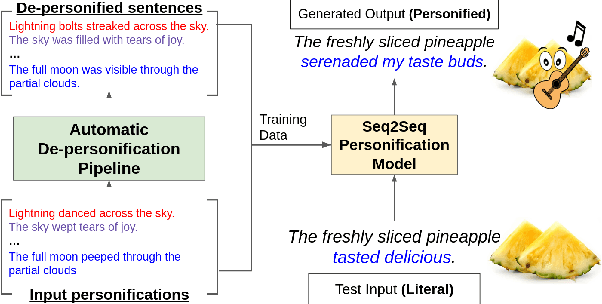
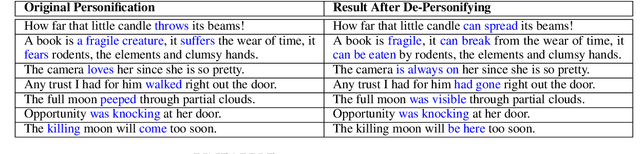
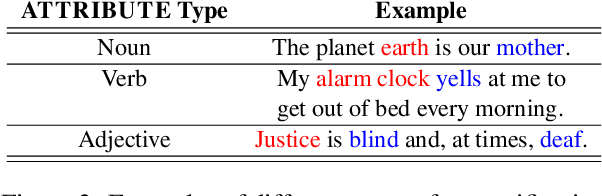
A personification is a figure of speech that endows inanimate entities with properties and actions typically seen as requiring animacy. In this paper, we explore the task of personification generation. To this end, we propose PINEAPPLE: Personifying INanimate Entities by Acquiring Parallel Personification data for Learning Enhanced generation. We curate a corpus of personifications called PersonifCorp, together with automatically generated de-personified literalizations of these personifications. We demonstrate the usefulness of this parallel corpus by training a seq2seq model to personify a given literal input. Both automatic and human evaluations show that fine-tuning with PersonifCorp leads to significant gains in personification-related qualities such as animacy and interestingness. A detailed qualitative analysis also highlights key strengths and imperfections of PINEAPPLE over baselines, demonstrating a strong ability to generate diverse and creative personifications that enhance the overall appeal of a sentence.
PANCETTA: Phoneme Aware Neural Completion to Elicit Tongue Twisters Automatically
Sep 13, 2022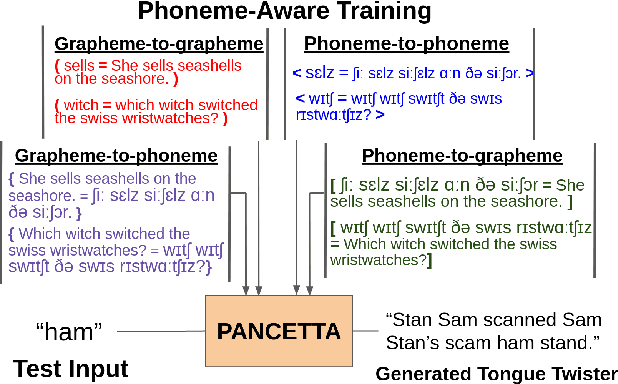

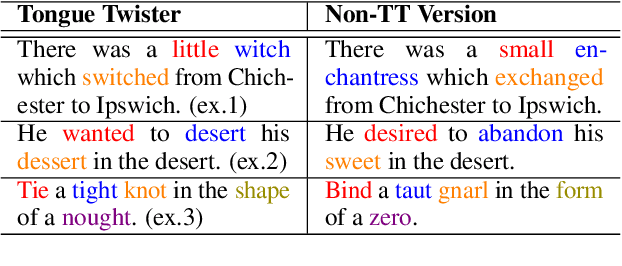
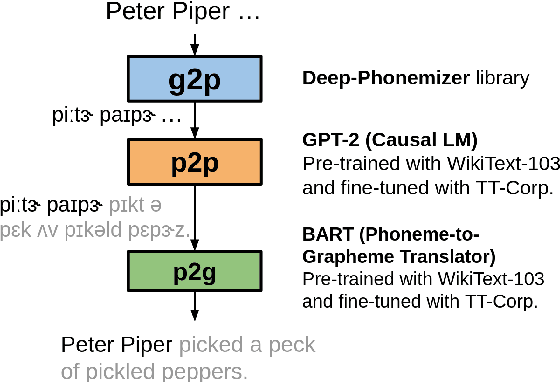
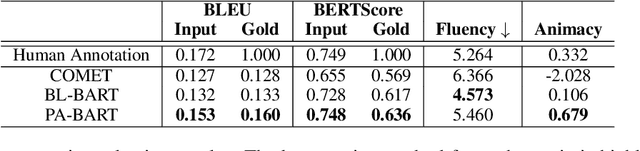
Tongue twisters are meaningful sentences that are difficult to pronounce. The process of automatically generating tongue twisters is challenging since the generated utterance must satisfy two conditions at once: phonetic difficulty and semantic meaning. Furthermore, phonetic difficulty is itself hard to characterize and is expressed in natural tongue twisters through a heterogeneous mix of phenomena such as alliteration and homophony. In this paper, we propose PANCETTA: Phoneme Aware Neural Completion to Elicit Tongue Twisters Automatically. We leverage phoneme representations to capture the notion of phonetic difficulty, and we train language models to generate original tongue twisters on two proposed task settings. To do this, we curate a dataset called PANCETTA, consisting of existing English tongue twisters. Through automatic and human evaluation, as well as qualitative analysis, we show that PANCETTA generates novel, phonetically difficult, fluent, and semantically meaningful tongue twisters.
Semi-Supervised Noisy Student Pre-training on EfficientNet Architectures for Plant Pathology Classification
Dec 01, 2020
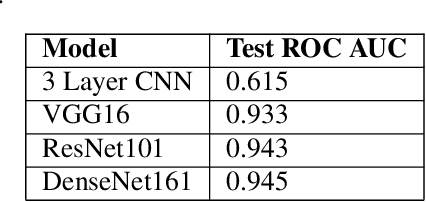

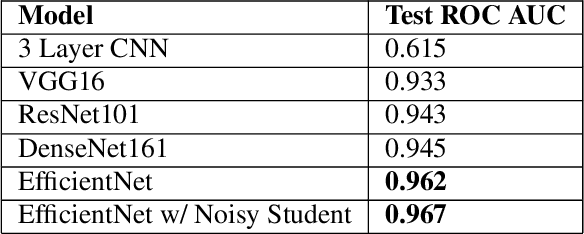
In recent years, deep learning has vastly improved the identification and diagnosis of various diseases in plants. In this report, we investigate the problem of pathology classification using images of a single leaf. We explore the use of standard benchmark models such as VGG16, ResNet101, and DenseNet 161 to achieve a 0.945 score on the task. Furthermore, we explore the use of the newer EfficientNet model, improving the accuracy to 0.962. Finally, we introduce the state-of-the-art idea of semi-supervised Noisy Student training to the EfficientNet, resulting in significant improvements in both accuracy and convergence rate. The final ensembled Noisy Student model performs very well on the task, achieving a test score of 0.982.
Myers-Briggs Personality Classification and Personality-Specific Language Generation Using Pre-trained Language Models
Jul 15, 2019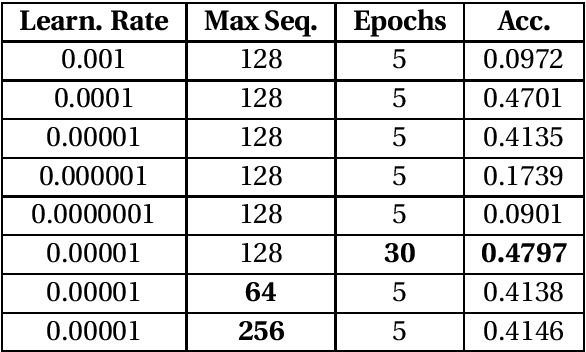
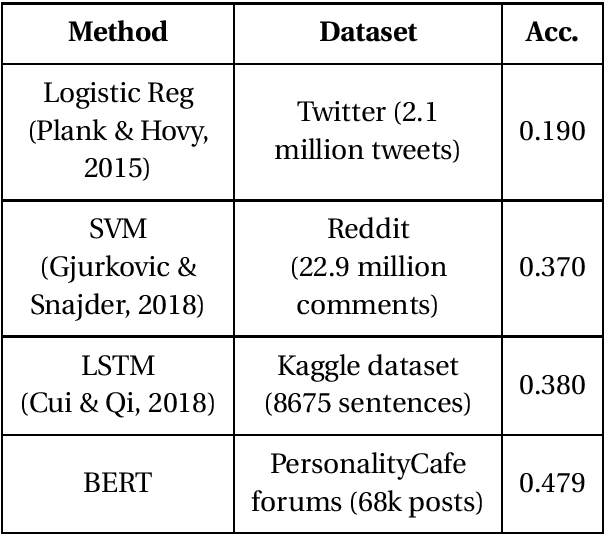


The Myers-Briggs Type Indicator (MBTI) is a popular personality metric that uses four dichotomies as indicators of personality traits. This paper examines the use of pre-trained language models to predict MBTI personality types based on scraped labeled texts. The proposed model reaches an accuracy of $0.47$ for correctly predicting all 4 types and $0.86$ for correctly predicting at least 2 types. Furthermore, we investigate the possible uses of a fine-tuned BERT model for personality-specific language generation. This is a task essential for both modern psychology and for intelligent empathetic systems.