 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere It Really Matters: Few-Shot Environmental Conservation Media Monitoring for Low-Resource Languages
Feb 19, 2024



Environmental conservation organizations routinely monitor news content on conservation in protected areas to maintain situational awareness of developments that can have an environmental impact. Existing automated media monitoring systems require large amounts of data labeled by domain experts, which is only feasible at scale for high-resource languages like English. However, such tools are most needed in the global south where news of interest is mainly in local low-resource languages, and far fewer experts are available to annotate datasets sustainably. In this paper, we propose NewsSerow, a method to automatically recognize environmental conservation content in low-resource languages. NewsSerow is a pipeline of summarization, in-context few-shot classification, and self-reflection using large language models (LLMs). Using at most 10 demonstration example news articles in Nepali, NewsSerow significantly outperforms other few-shot methods and achieves comparable performance with models fully fine-tuned using thousands of examples. The World Wide Fund for Nature (WWF) has deployed NewsSerow for media monitoring in Nepal, significantly reducing their operational burden, and ensuring that AI tools for conservation actually reach the communities that need them the most. NewsSerow has also been deployed for countries with other languages like Colombia.
Multi-Dimensional Evaluation of Text Summarization with In-Context Learning
Jun 01, 2023

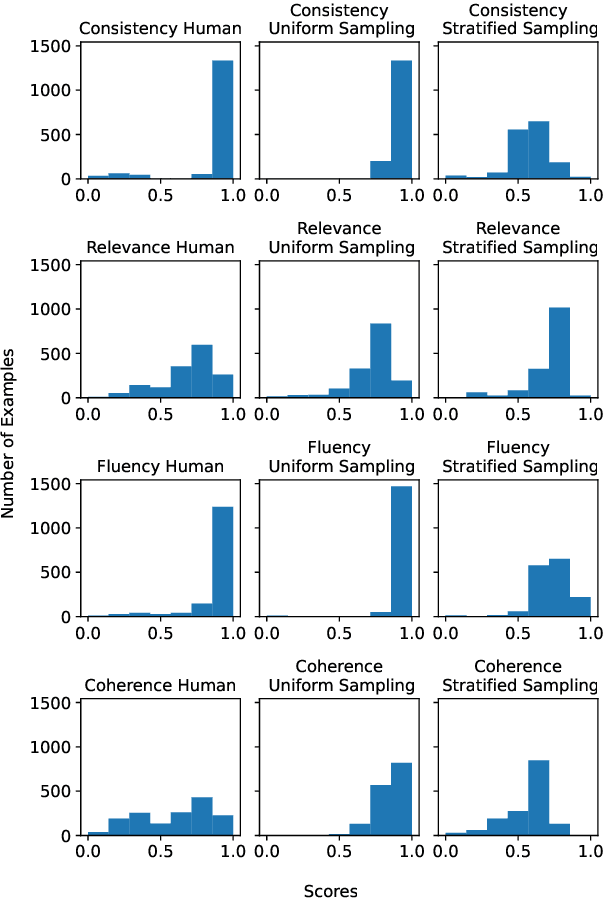

Evaluation of natural language generation (NLG) is complex and multi-dimensional. Generated text can be evaluated for fluency, coherence, factuality, or any other dimensions of interest. Most frameworks that perform such multi-dimensional evaluation require training on large manually or synthetically generated datasets. In this paper, we study the efficacy of large language models as multi-dimensional evaluators using in-context learning, obviating the need for large training datasets. Our experiments show that in-context learning-based evaluators are competitive with learned evaluation frameworks for the task of text summarization, establishing state-of-the-art on dimensions such as relevance and factual consistency. We then analyze the effects of factors such as the selection and number of in-context examples on performance. Finally, we study the efficacy of in-context learning based evaluators in evaluating zero-shot summaries written by large language models such as GPT-3.