 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScript Gap: Evaluating LLM Triage on Indian Languages in Native vs Roman Scripts in a Real World Setting
Dec 11, 2025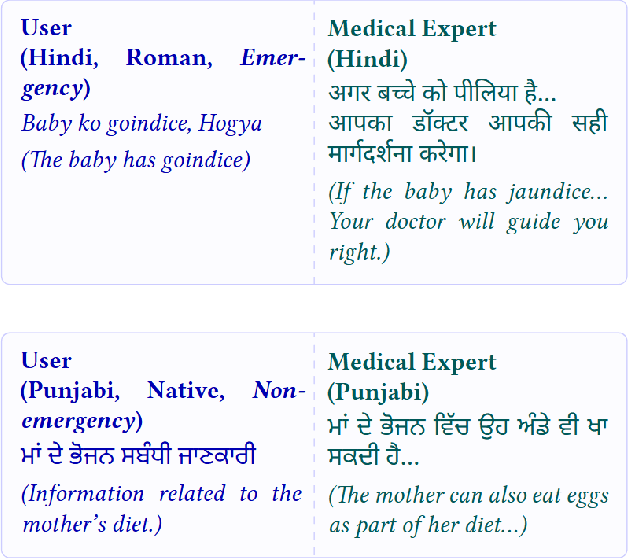
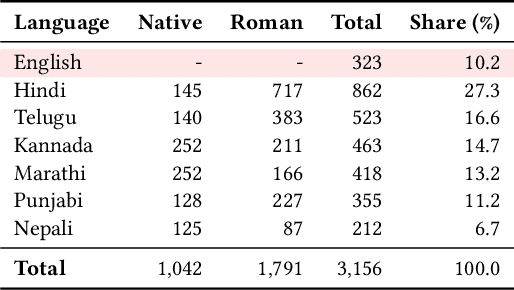


Large Language Models (LLMs) are increasingly deployed in high-stakes clinical applications in India. In many such settings, speakers of Indian languages frequently communicate using romanized text rather than native scripts, yet existing research rarely evaluates this orthographic variation using real-world data. We investigate how romanization impacts the reliability of LLMs in a critical domain: maternal and newborn healthcare triage. We benchmark leading LLMs on a real-world dataset of user-generated queries spanning five Indian languages and Nepali. Our results reveal consistent degradation in performance for romanized messages, with F1 scores trailing those of native scripts by 5-12 points. At our partner maternal health organization in India, this gap could cause nearly 2 million excess errors in triage. Crucially, this performance gap by scripts is not due to a failure in clinical reasoning. We demonstrate that LLMs often correctly infer the semantic intent of romanized queries. Nevertheless, their final classification outputs remain brittle in the presence of orthographic noise in romanized inputs. Our findings highlight a critical safety blind spot in LLM-based health systems: models that appear to understand romanized input may still fail to act on it reliably.
RescueLens: LLM-Powered Triage and Action on Volunteer Feedback for Food Rescue
Nov 19, 2025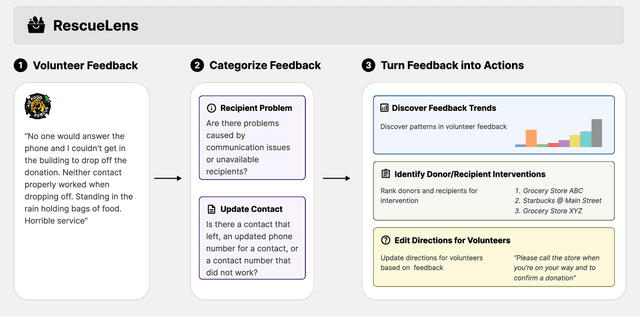
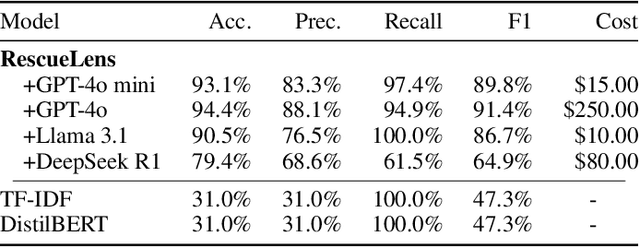
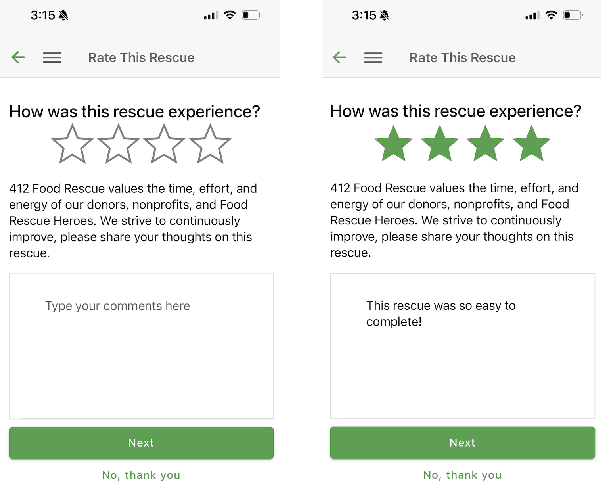
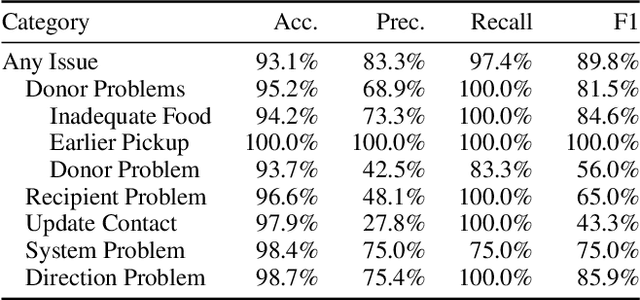
Food rescue organizations simultaneously tackle food insecurity and waste by working with volunteers to redistribute food from donors who have excess to recipients who need it. Volunteer feedback allows food rescue organizations to identify issues early and ensure volunteer satisfaction. However, food rescue organizations monitor feedback manually, which can be cumbersome and labor-intensive, making it difficult to prioritize which issues are most important. In this work, we investigate how large language models (LLMs) assist food rescue organizers in understanding and taking action based on volunteer experiences. We work with 412 Food Rescue, a large food rescue organization based in Pittsburgh, Pennsylvania, to design RescueLens, an LLM-powered tool that automatically categorizes volunteer feedback, suggests donors and recipients to follow up with, and updates volunteer directions based on feedback. We evaluate the performance of RescueLens on an annotated dataset, and show that it can recover 96% of volunteer issues at 71% precision. Moreover, by ranking donors and recipients according to their rates of volunteer issues, RescueLens allows organizers to focus on 0.5% of donors responsible for more than 30% of volunteer issues. RescueLens is now deployed at 412 Food Rescue and through semi-structured interviews with organizers, we find that RescueLens streamlines the feedback process so organizers better allocate their time.
Towards Automated Scoping of AI for Social Good Projects
Apr 28, 2025Artificial Intelligence for Social Good (AI4SG) is an emerging effort that aims to address complex societal challenges with the powerful capabilities of AI systems. These challenges range from local issues with transit networks to global wildlife preservation. However, regardless of scale, a critical bottleneck for many AI4SG initiatives is the laborious process of problem scoping -- a complex and resource-intensive task -- due to a scarcity of professionals with both technical and domain expertise. Given the remarkable applications of large language models (LLM), we propose a Problem Scoping Agent (PSA) that uses an LLM to generate comprehensive project proposals grounded in scientific literature and real-world knowledge. We demonstrate that our PSA framework generates proposals comparable to those written by experts through a blind review and AI evaluations. Finally, we document the challenges of real-world problem scoping and note several areas for future work.
Resolving UnderEdit & OverEdit with Iterative & Neighbor-Assisted Model Editing
Mar 14, 2025Large Language Models (LLMs) are used in various downstream language tasks, making it crucial to keep their knowledge up-to-date, but both retraining and fine-tuning the model can be costly. Model editing offers an efficient and effective alternative by a single update to only a key subset of model parameters. While being efficient, these methods are not perfect. Sometimes knowledge edits are unsuccessful, i.e., UnderEdit, or the edit contaminated neighboring knowledge that should remain unchanged, i.e., OverEdit. To address these limitations, we propose iterative model editing, based on our hypothesis that a single parameter update is often insufficient, to mitigate UnderEdit, and neighbor-assisted model editing, which incorporates neighboring knowledge during editing to minimize OverEdit. Extensive experiments demonstrate that our methods effectively reduce UnderEdit up to 38 percentage points and OverEdit up to 6 percentage points across multiple model editing algorithms, LLMs, and benchmark datasets.
Where It Really Matters: Few-Shot Environmental Conservation Media Monitoring for Low-Resource Languages
Feb 19, 2024



Environmental conservation organizations routinely monitor news content on conservation in protected areas to maintain situational awareness of developments that can have an environmental impact. Existing automated media monitoring systems require large amounts of data labeled by domain experts, which is only feasible at scale for high-resource languages like English. However, such tools are most needed in the global south where news of interest is mainly in local low-resource languages, and far fewer experts are available to annotate datasets sustainably. In this paper, we propose NewsSerow, a method to automatically recognize environmental conservation content in low-resource languages. NewsSerow is a pipeline of summarization, in-context few-shot classification, and self-reflection using large language models (LLMs). Using at most 10 demonstration example news articles in Nepali, NewsSerow significantly outperforms other few-shot methods and achieves comparable performance with models fully fine-tuned using thousands of examples. The World Wide Fund for Nature (WWF) has deployed NewsSerow for media monitoring in Nepal, significantly reducing their operational burden, and ensuring that AI tools for conservation actually reach the communities that need them the most. NewsSerow has also been deployed for countries with other languages like Colombia.
NewsPanda: Media Monitoring for Timely Conservation Action
Apr 30, 2023Non-governmental organizations for environmental conservation have a significant interest in monitoring conservation-related media and getting timely updates about infrastructure construction projects as they may cause massive impact to key conservation areas. Such monitoring, however, is difficult and time-consuming. We introduce NewsPanda, a toolkit which automatically detects and analyzes online articles related to environmental conservation and infrastructure construction. We fine-tune a BERT-based model using active learning methods and noise correction algorithms to identify articles that are relevant to conservation and infrastructure construction. For the identified articles, we perform further analysis, extracting keywords and finding potentially related sources. NewsPanda has been successfully deployed by the World Wide Fund for Nature teams in the UK, India, and Nepal since February 2022. It currently monitors over 80,000 websites and 1,074 conservation sites across India and Nepal, saving more than 30 hours of human efforts weekly. We have now scaled it up to cover 60,000 conservation sites globally.
MAVIPER: Learning Decision Tree Policies for Interpretable Multi-Agent Reinforcement Learning
May 25, 2022
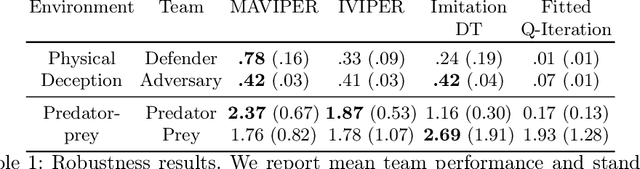

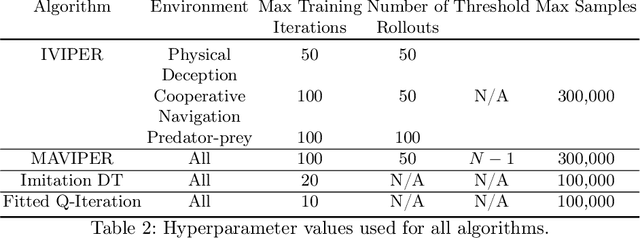
Many recent breakthroughs in multi-agent reinforcement learning (MARL) require the use of deep neural networks, which are challenging for human experts to interpret and understand. On the other hand, existing work on interpretable RL has shown promise in extracting more interpretable decision tree-based policies, but only in the single-agent setting. To fill this gap, we propose the first set of interpretable MARL algorithms that extract decision-tree policies from neural networks trained with MARL. The first algorithm, IVIPER, extends VIPER, a recent method for single-agent interpretable RL, to the multi-agent setting. We demonstrate that IVIPER can learn high-quality decision-tree policies for each agent. To better capture coordination between agents, we propose a novel centralized decision-tree training algorithm, MAVIPER. MAVIPER jointly grows the trees of each agent by predicting the behavior of the other agents using their anticipated trees, and uses resampling to focus on states that are critical for its interactions with other agents. We show that both algorithms generally outperform the baselines and that MAVIPER-trained agents achieve better-coordinated performance than IVIPER-trained agents on three different multi-agent particle-world environments.
Bandit Data-driven Optimization: AI for Social Good and Beyond
Aug 26, 2020
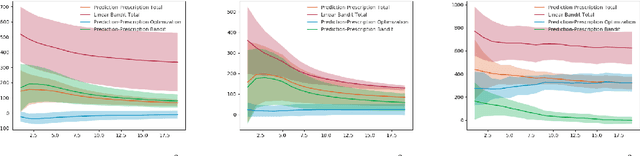
The use of machine learning (ML) systems in real-world applications entails more than just a prediction algorithm. AI for social good applications, and many real-world ML tasks in general, feature an iterative process which joins prediction, optimization, and data acquisition happen in a loop. We introduce bandit data-driven optimization, the first iterative prediction-prescription framework to formally analyze this practical routine. Bandit data-driven optimization combines the advantages of online bandit learning and offline predictive analytics in an integrated framework. It offers a flexible setup to reason about unmodeled policy objectives and unforeseen consequences. We propose PROOF, the first algorithm for this framework and show that it achieves no-regret. Using numerical simulations, we show that PROOF achieves superior performance over existing baseline.
Artificial Intelligence for Social Good: A Survey
Jan 07, 2020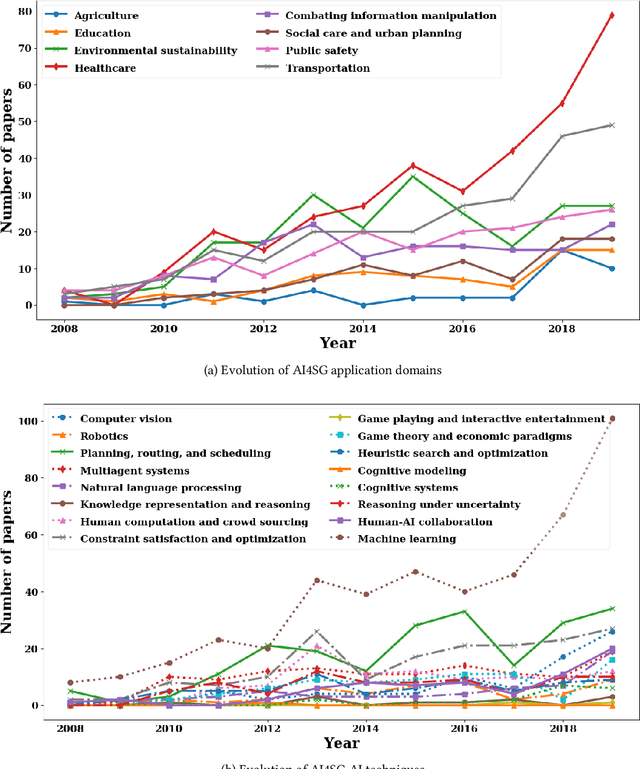

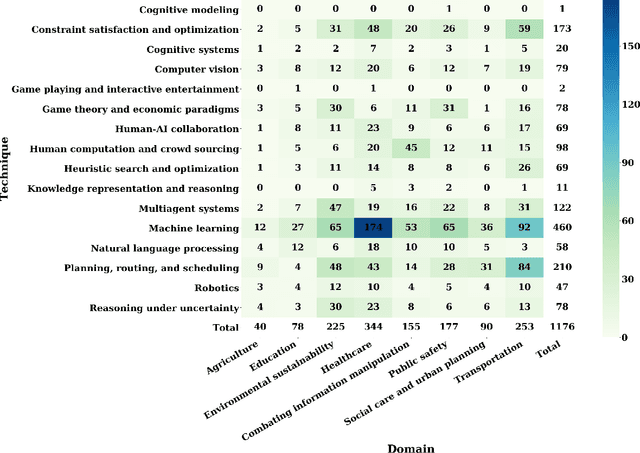
Artificial intelligence for social good (AI4SG) is a research theme that aims to use and advance artificial intelligence to address societal issues and improve the well-being of the world. AI4SG has received lots of attention from the research community in the past decade with several successful applications. Building on the most comprehensive collection of the AI4SG literature to date with over 1000 contributed papers, we provide a detailed account and analysis of the work under the theme in the following ways. (1) We quantitatively analyze the distribution and trend of the AI4SG literature in terms of application domains and AI techniques used. (2) We propose three conceptual methods to systematically group the existing literature and analyze the eight AI4SG application domains in a unified framework. (3) We distill five research topics that represent the common challenges in AI4SG across various application domains. (4) We discuss five issues that, we hope, can shed light on the future development of the AI4SG research.
Learning and Planning in Feature Deception Games
May 13, 2019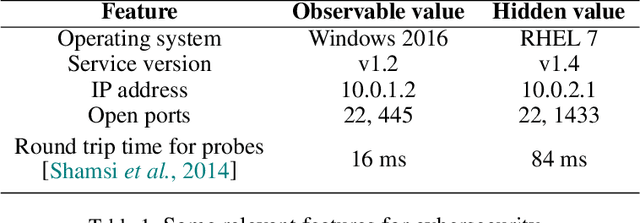
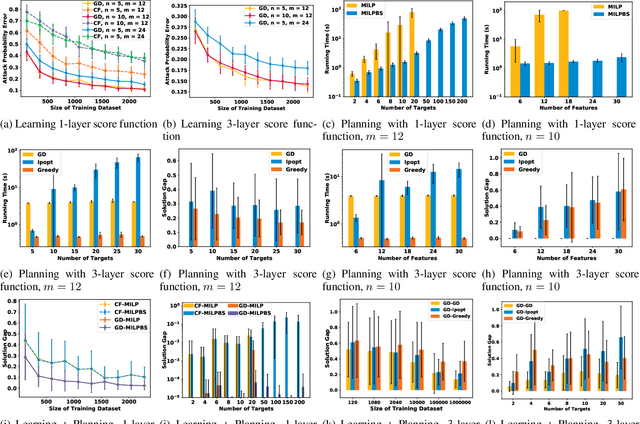
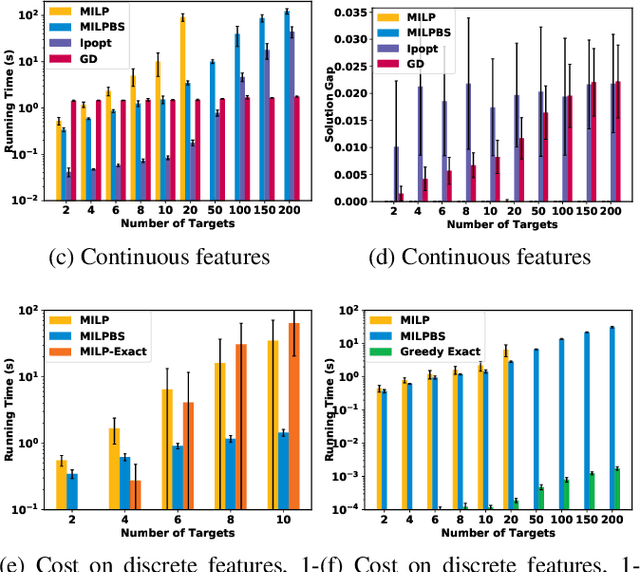

Today's high-stakes adversarial interactions feature attackers who constantly breach the ever-improving security measures. Deception mitigates the defender's loss by misleading the attacker to make suboptimal decisions. In order to formally reason about deception, we introduce the feature deception game (FDG), a domain-independent game-theoretic model and present a learning and planning framework. We make the following contributions. (1) We show that we can uniformly learn the adversary's preferences using data from a modest number of deception strategies. (2) We propose an approximation algorithm for finding the optimal deception strategy and show that the problem is NP-hard. (3) We perform extensive experiments to empirically validate our methods and results.