 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Green Security Games with Real-Time Information
Nov 06, 2018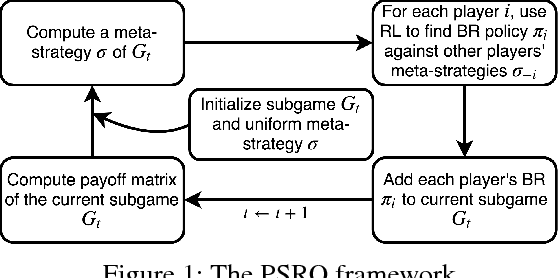
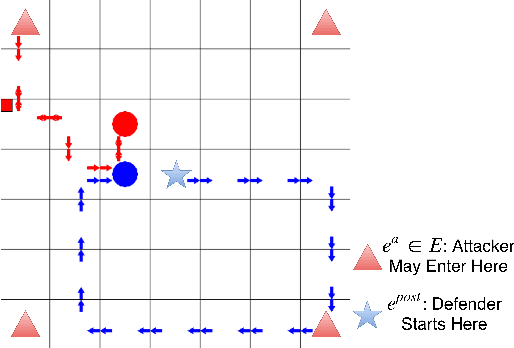

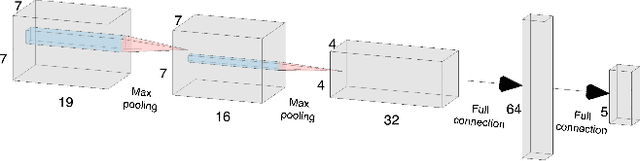
Green Security Games (GSGs) have been proposed and applied to optimize patrols conducted by law enforcement agencies in green security domains such as combating poaching, illegal logging and overfishing. However, real-time information such as footprints and agents' subsequent actions upon receiving the information, e.g., rangers following the footprints to chase the poacher, have been neglected in previous work. To fill the gap, we first propose a new game model GSG-I which augments GSGs with sequential movement and the vital element of real-time information. Second, we design a novel deep reinforcement learning-based algorithm, DeDOL, to compute a patrolling strategy that adapts to the real-time information against a best-responding attacker. DeDOL is built upon the double oracle framework and the policy-space response oracle, solving a restricted game and iteratively adding best response strategies to it through training deep Q-networks. Exploring the game structure, DeDOL uses domain-specific heuristic strategies as initial strategies and constructs several local modes for efficient and parallelized training. To our knowledge, this is the first attempt to use Deep Q-Learning for security games.
Feature Based Task Recommendation in Crowdsourcing with Implicit Observations
Sep 07, 2016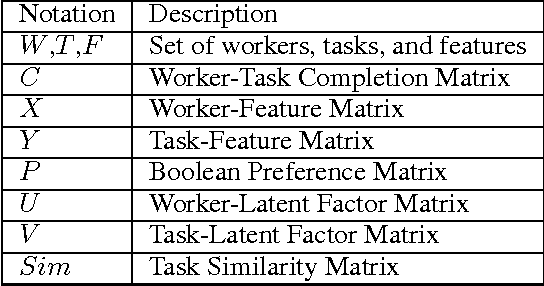
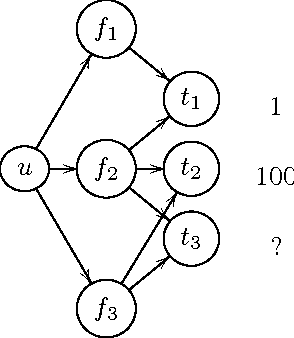
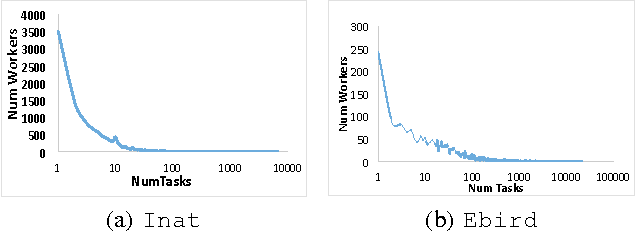
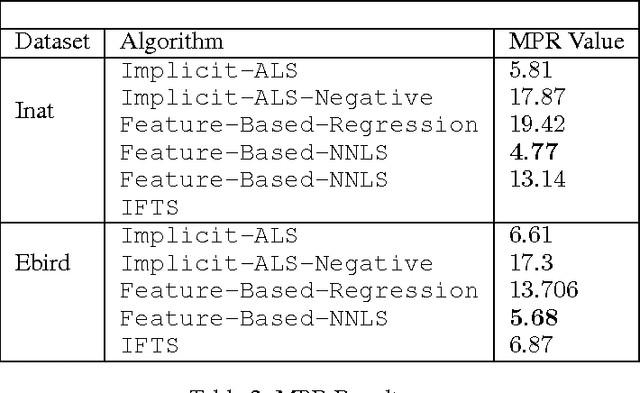
Existing research in crowdsourcing has investigated how to recommend tasks to workers based on which task the workers have already completed, referred to as {\em implicit feedback}. We, on the other hand, investigate the task recommendation problem, where we leverage both implicit feedback and explicit features of the task. We assume that we are given a set of workers, a set of tasks, interactions (such as the number of times a worker has completed a particular task), and the presence of explicit features of each task (such as, task location). We intend to recommend tasks to the workers by exploiting the implicit interactions, and the presence or absence of explicit features in the tasks. We formalize the problem as an optimization problem, propose two alternative problem formulations and respective solutions that exploit implicit feedback, explicit features, as well as similarity between the tasks. We compare the efficacy of our proposed solutions against multiple state-of-the-art techniques using two large scale real world datasets.