 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineDeb: A Debiasing Framework for Language Models
Feb 05, 2023As language models are increasingly included in human-facing machine learning tools, bias against demographic subgroups has gained attention. We propose FineDeb, a two-phase debiasing framework for language models that starts with contextual debiasing of embeddings learned by pretrained language models. The model is then fine-tuned on a language modeling objective. Our results show that FineDeb offers stronger debiasing in comparison to other methods which often result in models as biased as the original language model. Our framework is generalizable for demographics with multiple classes, and we demonstrate its effectiveness through extensive experiments and comparisons with state of the art techniques. We release our code and data on GitHub.
Feature Based Task Recommendation in Crowdsourcing with Implicit Observations
Sep 07, 2016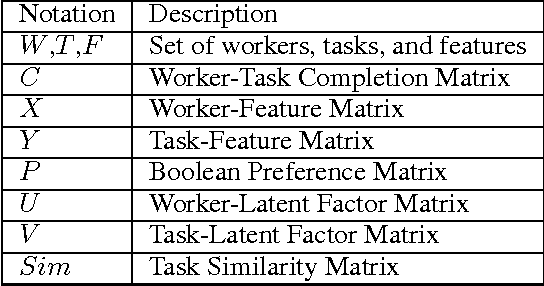
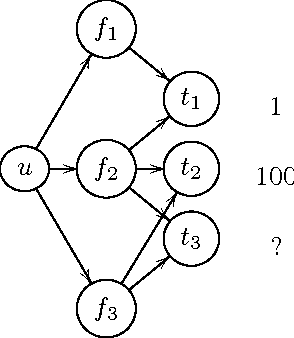
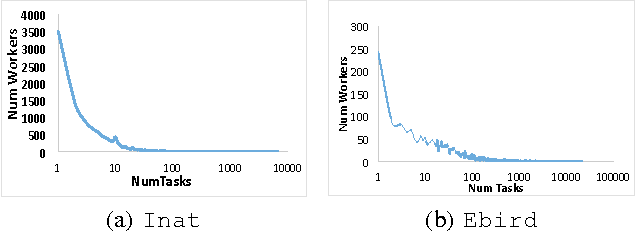
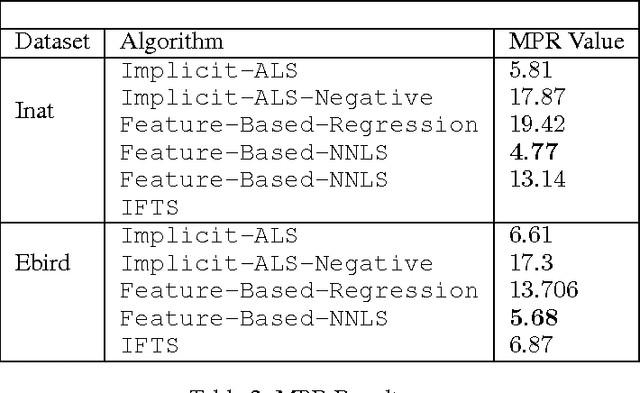
Existing research in crowdsourcing has investigated how to recommend tasks to workers based on which task the workers have already completed, referred to as {\em implicit feedback}. We, on the other hand, investigate the task recommendation problem, where we leverage both implicit feedback and explicit features of the task. We assume that we are given a set of workers, a set of tasks, interactions (such as the number of times a worker has completed a particular task), and the presence of explicit features of each task (such as, task location). We intend to recommend tasks to the workers by exploiting the implicit interactions, and the presence or absence of explicit features in the tasks. We formalize the problem as an optimization problem, propose two alternative problem formulations and respective solutions that exploit implicit feedback, explicit features, as well as similarity between the tasks. We compare the efficacy of our proposed solutions against multiple state-of-the-art techniques using two large scale real world datasets.