 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Handling Coreference Resolution in Aspect Level Sentiment Classification by Fine-Tuning Language Models
Jul 11, 2023Customer feedback is invaluable to companies as they refine their products. Monitoring customer feedback can be automated with Aspect Level Sentiment Classification (ALSC) which allows us to analyse specific aspects of the products in reviews. Large Language Models (LLMs) are the heart of many state-of-the-art ALSC solutions, but they perform poorly in some scenarios requiring Coreference Resolution (CR). In this work, we propose a framework to improve an LLM's performance on CR-containing reviews by fine tuning on highly inferential tasks. We show that the performance improvement is likely attributed to the improved model CR ability. We also release a new dataset that focuses on CR in ALSC.
FineDeb: A Debiasing Framework for Language Models
Feb 05, 2023As language models are increasingly included in human-facing machine learning tools, bias against demographic subgroups has gained attention. We propose FineDeb, a two-phase debiasing framework for language models that starts with contextual debiasing of embeddings learned by pretrained language models. The model is then fine-tuned on a language modeling objective. Our results show that FineDeb offers stronger debiasing in comparison to other methods which often result in models as biased as the original language model. Our framework is generalizable for demographics with multiple classes, and we demonstrate its effectiveness through extensive experiments and comparisons with state of the art techniques. We release our code and data on GitHub.
Discriminative Models Can Still Outperform Generative Models in Aspect Based Sentiment Analysis
Jun 06, 2022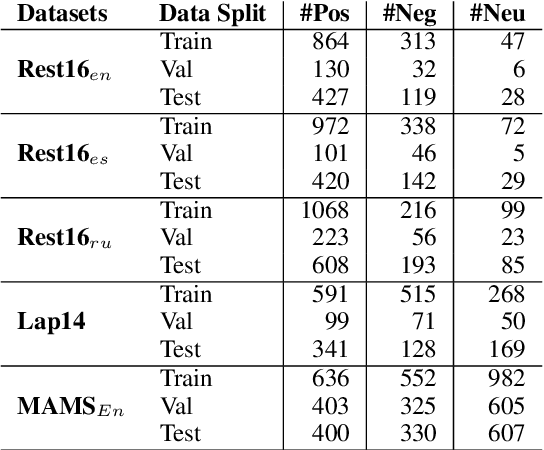
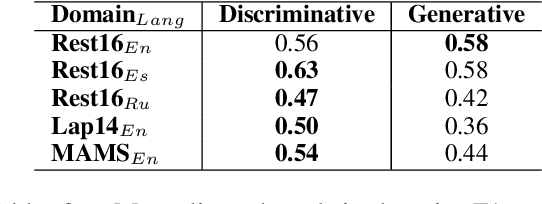
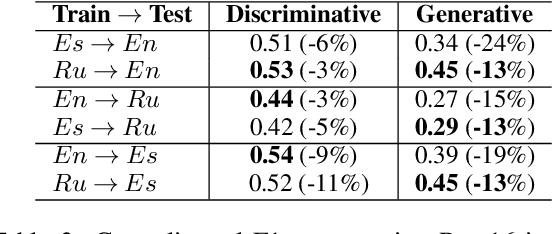
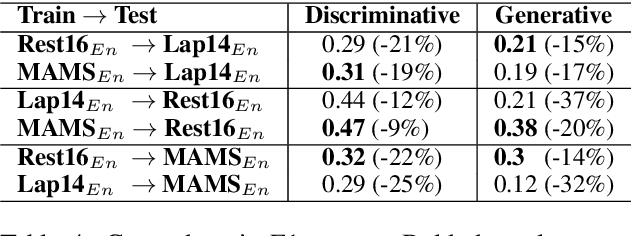
Aspect-based Sentiment Analysis (ABSA) helps to explain customers' opinions towards products and services. In the past, ABSA models were discriminative, but more recently generative models have been used to generate aspects and polarities directly from text. In contrast, discriminative models commonly first select aspects from the text, and then classify the aspect's polarity. Previous results showed that generative models outperform discriminative models on several English ABSA datasets. Here, we evaluate and contrast two state-of-the-art discriminative and generative models in several settings: cross-lingual, cross-domain, and cross-lingual and domain, to understand generalizability in settings other than English mono-lingual in-domain. Our more thorough evaluation shows that, contrary to previous studies, discriminative models can still outperform generative models in almost all settings.