 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustDebias: Debiasing Language Models using Distributionally Robust Optimization
Jan 30, 2026Pretrained language models have been shown to exhibit biases and social stereotypes. Prior work on debiasing these models has largely focused on modifying embedding spaces during pretraining, which is not scalable for large models. Fine-tuning pretrained models on task-specific datasets can both degrade model performance and amplify biases present in the fine-tuning data. We address bias amplification during fine-tuning rather than costly pretraining, focusing on BERT models due to their widespread use in language understanding tasks. While Empirical Risk Minimization effectively optimizes downstream performance, it often amplifies social biases during fine-tuning. To counter this, we propose \textit{RobustDebias}, a novel mechanism which adapts Distributionally Robust Optimization (DRO) to debias language models during fine-tuning. Our approach debiases models across multiple demographics during MLM fine-tuning and generalizes to any dataset or task. Extensive experiments on various language models show significant bias mitigation with minimal performance impact.
Connecting Thompson Sampling and UCB: Towards More Efficient Trade-offs Between Privacy and Regret
May 05, 2025



We address differentially private stochastic bandit problems from the angles of exploring the deep connections among Thompson Sampling with Gaussian priors, Gaussian mechanisms, and Gaussian differential privacy (GDP). We propose DP-TS-UCB, a novel parametrized private bandit algorithm that enables to trade off privacy and regret. DP-TS-UCB satisfies $ \tilde{O} \left(T^{0.25(1-\alpha)}\right)$-GDP and enjoys an $O \left(K\ln^{\alpha+1}(T)/\Delta \right)$ regret bound, where $\alpha \in [0,1]$ controls the trade-off between privacy and regret. Theoretically, our DP-TS-UCB relies on anti-concentration bounds of Gaussian distributions and links exploration mechanisms in Thompson Sampling-based algorithms and Upper Confidence Bound-based algorithms, which may be of independent interest.
Mixture of Nested Experts: Adaptive Processing of Visual Tokens
Jul 29, 2024

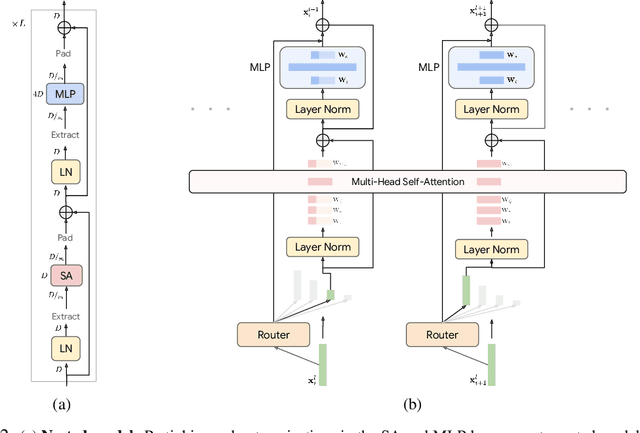
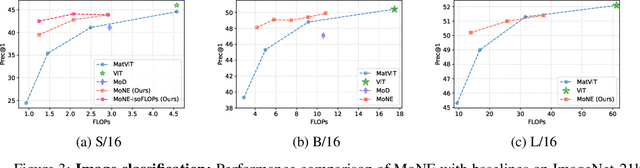
The visual medium (images and videos) naturally contains a large amount of information redundancy, thereby providing a great opportunity for leveraging efficiency in processing. While Vision Transformer (ViT) based models scale effectively to large data regimes, they fail to capitalize on this inherent redundancy, leading to higher computational costs. Mixture of Experts (MoE) networks demonstrate scalability while maintaining same inference-time costs, but they come with a larger parameter footprint. We present Mixture of Nested Experts (MoNE), which utilizes a nested structure for experts, wherein individual experts fall on an increasing compute-accuracy curve. Given a compute budget, MoNE learns to dynamically choose tokens in a priority order, and thus redundant tokens are processed through cheaper nested experts. Using this framework, we achieve equivalent performance as the baseline models, while reducing inference time compute by over two-fold. We validate our approach on standard image and video datasets - ImageNet-21K, Kinetics400, and Something-Something-v2. We further highlight MoNE$'$s adaptability by showcasing its ability to maintain strong performance across different inference-time compute budgets on videos, using only a single trained model.
Efficient and Adaptive Posterior Sampling Algorithms for Bandits
May 02, 2024


We study Thompson Sampling-based algorithms for stochastic bandits with bounded rewards. As the existing problem-dependent regret bound for Thompson Sampling with Gaussian priors [Agrawal and Goyal, 2017] is vacuous when $T \le 288 e^{64}$, we derive a more practical bound that tightens the coefficient of the leading term %from $288 e^{64}$ to $1270$. Additionally, motivated by large-scale real-world applications that require scalability, adaptive computational resource allocation, and a balance in utility and computation, we propose two parameterized Thompson Sampling-based algorithms: Thompson Sampling with Model Aggregation (TS-MA-$\alpha$) and Thompson Sampling with Timestamp Duelling (TS-TD-$\alpha$), where $\alpha \in [0,1]$ controls the trade-off between utility and computation. Both algorithms achieve $O \left(K\ln^{\alpha+1}(T)/\Delta \right)$ regret bound, where $K$ is the number of arms, $T$ is the finite learning horizon, and $\Delta$ denotes the single round performance loss when pulling a sub-optimal arm.
Analyzing the Efficacy of an LLM-Only Approach for Image-based Document Question Answering
Sep 25, 2023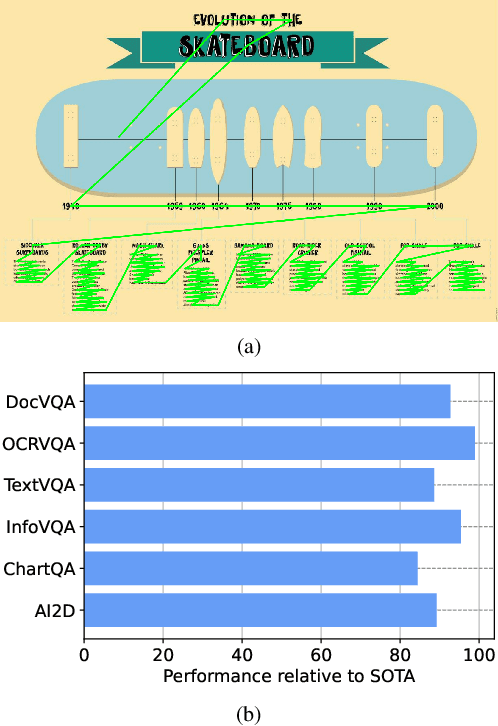
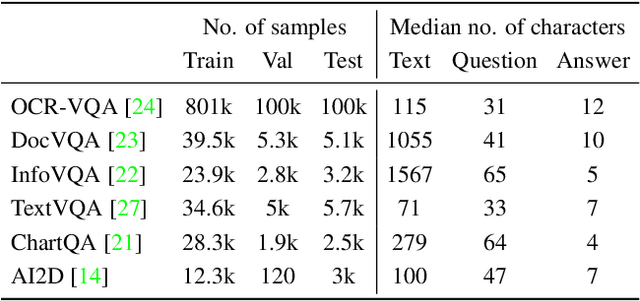
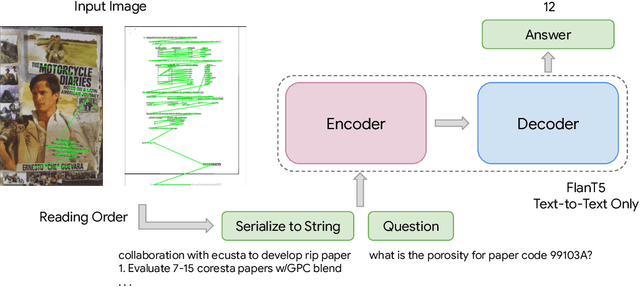

Recent document question answering models consist of two key components: the vision encoder, which captures layout and visual elements in images, and a Large Language Model (LLM) that helps contextualize questions to the image and supplements them with external world knowledge to generate accurate answers. However, the relative contributions of the vision encoder and the language model in these tasks remain unclear. This is especially interesting given the effectiveness of instruction-tuned LLMs, which exhibit remarkable adaptability to new tasks. To this end, we explore the following aspects in this work: (1) The efficacy of an LLM-only approach on document question answering tasks (2) strategies for serializing textual information within document images and feeding it directly to an instruction-tuned LLM, thus bypassing the need for an explicit vision encoder (3) thorough quantitative analysis on the feasibility of such an approach. Our comprehensive analysis encompasses six diverse benchmark datasets, utilizing LLMs of varying scales. Our findings reveal that a strategy exclusively reliant on the LLM yields results that are on par with or closely approach state-of-the-art performance across a range of datasets. We posit that this evaluation framework will serve as a guiding resource for selecting appropriate datasets for future research endeavors that emphasize the fundamental importance of layout and image content information.
FineDeb: A Debiasing Framework for Language Models
Feb 05, 2023As language models are increasingly included in human-facing machine learning tools, bias against demographic subgroups has gained attention. We propose FineDeb, a two-phase debiasing framework for language models that starts with contextual debiasing of embeddings learned by pretrained language models. The model is then fine-tuned on a language modeling objective. Our results show that FineDeb offers stronger debiasing in comparison to other methods which often result in models as biased as the original language model. Our framework is generalizable for demographics with multiple classes, and we demonstrate its effectiveness through extensive experiments and comparisons with state of the art techniques. We release our code and data on GitHub.
Long Term Fairness for Minority Groups via Performative Distributionally Robust Optimization
Jul 12, 2022
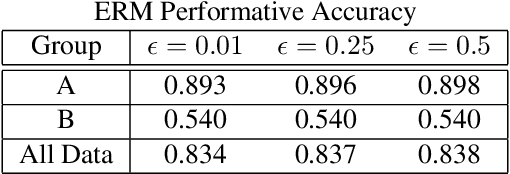

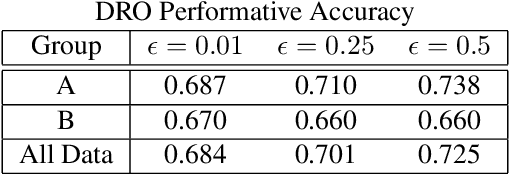
Fairness researchers in machine learning (ML) have coalesced around several fairness criteria which provide formal definitions of what it means for an ML model to be fair. However, these criteria have some serious limitations. We identify four key shortcomings of these formal fairness criteria, and aim to help to address them by extending performative prediction to include a distributionally robust objective.
Resonance in Weight Space: Covariate Shift Can Drive Divergence of SGD with Momentum
Mar 22, 2022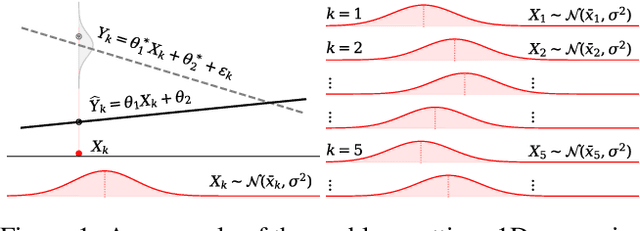
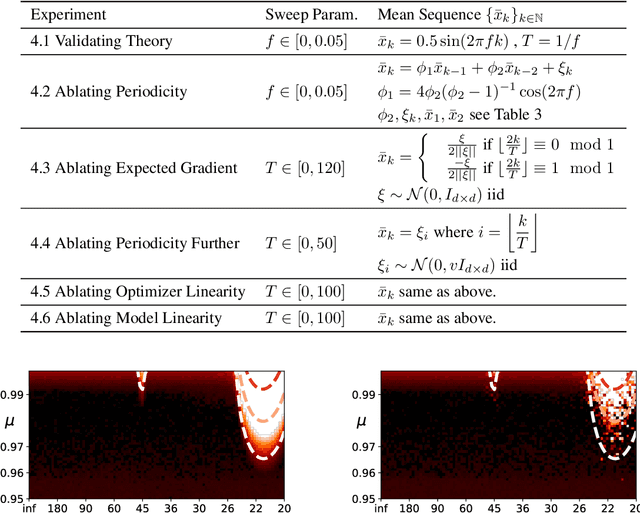
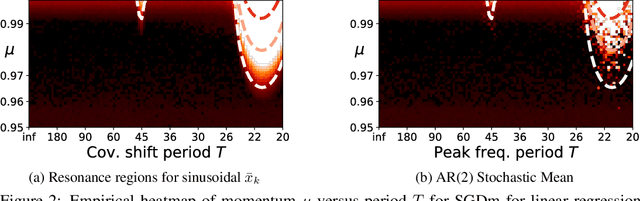

Most convergence guarantees for stochastic gradient descent with momentum (SGDm) rely on iid sampling. Yet, SGDm is often used outside this regime, in settings with temporally correlated input samples such as continual learning and reinforcement learning. Existing work has shown that SGDm with a decaying step-size can converge under Markovian temporal correlation. In this work, we show that SGDm under covariate shift with a fixed step-size can be unstable and diverge. In particular, we show SGDm under covariate shift is a parametric oscillator, and so can suffer from a phenomenon known as resonance. We approximate the learning system as a time varying system of ordinary differential equations, and leverage existing theory to characterize the system's divergence/convergence as resonant/nonresonant modes. The theoretical result is limited to the linear setting with periodic covariate shift, so we empirically supplement this result to show that resonance phenomena persist even under non-periodic covariate shift, nonlinear dynamics with neural networks, and optimizers other than SGDm.
Multi Type Mean Field Reinforcement Learning
Mar 09, 2020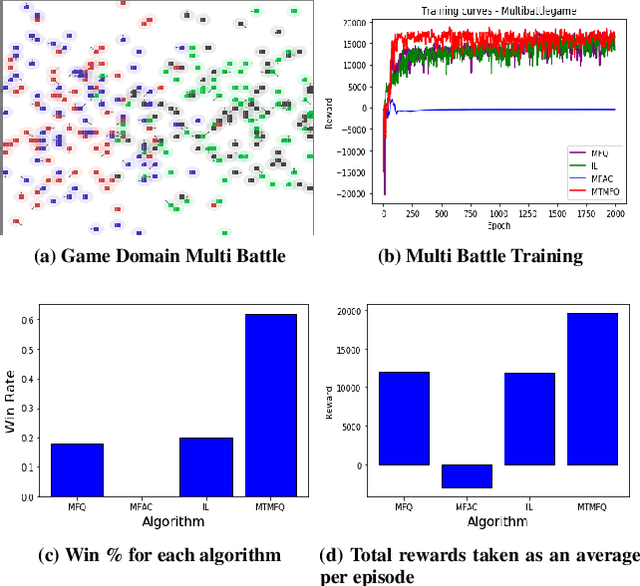
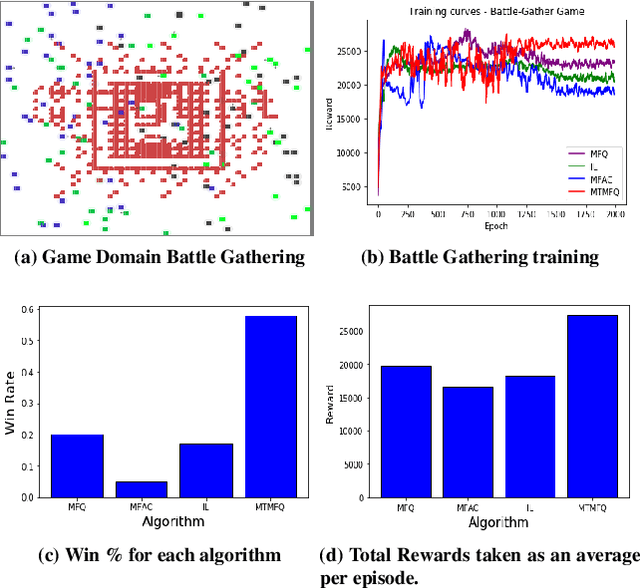
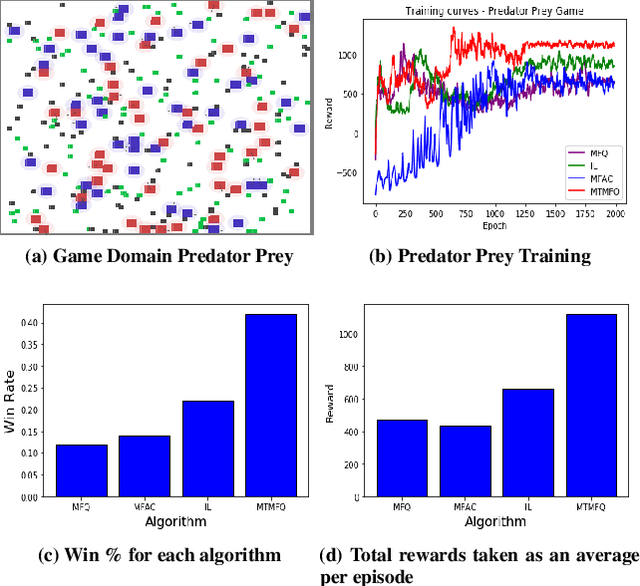
Mean field theory provides an effective way of scaling multiagent reinforcement learning algorithms to environments with many agents that can be abstracted by a virtual mean agent. In this paper, we extend mean field multiagent algorithms to multiple types. The types enable the relaxation of a core assumption in mean field games, which is that all agents in the environment are playing almost similar strategies and have the same goal. We conduct experiments on three different testbeds for the field of many agent reinforcement learning, based on the standard MAgents framework. We consider two different kinds of mean field games: a) Games where agents belong to predefined types that are known a priori and b) Games where the type of each agent is unknown and therefore must be learned based on observations. We introduce new algorithms for each type of game and demonstrate their superior performance over state of the art algorithms that assume that all agents belong to the same type and other baseline algorithms in the MAgent framework.
Private Q-Learning with Functional Noise in Continuous Spaces
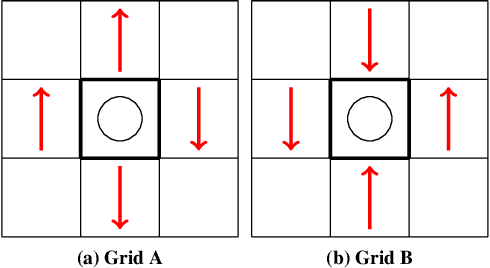
Jan 30, 2019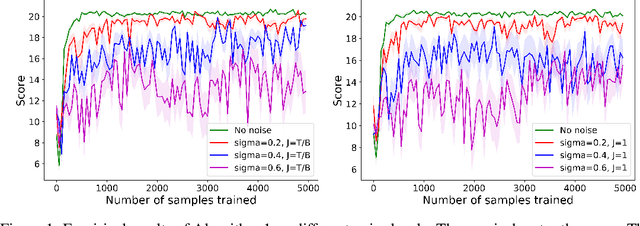
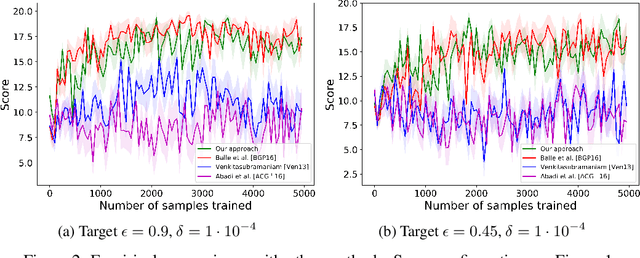
We consider privacy-preserving algorithms for deep reinforcement learning. State-of-the-art methods that guarantee differential privacy are not extendable to very large state spaces because the noise level necessary to ensure privacy would scale to infinity. We address the problem of providing differential privacy in Q-learning where a function approximation through a neural network is used for parametrization. We develop a rigorous and efficient algorithm by inspecting the reproducing kernel Hilbert space in which the neural network is embedded. Our approach uses functional noise to guarantee privacy, while the noise level scales linearly with the complexity of the neural network architecture. There are no known theoretical guarantees on the performance of deep reinforcement learning, but we gain some insight by providing a utility analysis under the discrete space setting.