 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWater-Filling is Universally Minimax Optimal
Mar 27, 2026Allocation of dynamically-arriving (i.e., online) divisible resources among a set of offline agents is a fundamental problem, with applications to online marketplaces, scheduling, portfolio selection, signal processing, and many other areas. The water-filling algorithm, which allocates an incoming resource to maximize the minimum load of compatible agents, is ubiquitous in many of these applications whenever the underlying objectives prefer more balanced solutions; however, the analysis and guarantees differ across settings. We provide a justification for the widespread use of water-filling by showing that it is a universally minimax optimal policy in a strong sense. Formally, our main result implies that water-filling is minimax optimal for a large class of objectives -- including both Schur-concave maximization and Schur-convex minimization -- under $α$-regret and competitive ratio measures. This optimality holds for every fixed tuple of agents and resource counts. Remarkably, water-filling achieves these guarantees as a myopic policy, remaining entirely agnostic to the objective function, agent count, and resource availability. Our techniques notably depart from the popular primal-dual analysis of online algorithms, and instead develop a novel way to apply the theory of majorization in online settings to achieve universality guarantees.
Online Fair Allocation of Perishable Resources
Jun 04, 2024We consider a practically motivated variant of the canonical online fair allocation problem: a decision-maker has a budget of perishable resources to allocate over a fixed number of rounds. Each round sees a random number of arrivals, and the decision-maker must commit to an allocation for these individuals before moving on to the next round. The goal is to construct a sequence of allocations that is envy-free and efficient. Our work makes two important contributions toward this problem: we first derive strong lower bounds on the optimal envy-efficiency trade-off that demonstrate that a decision-maker is fundamentally limited in what she can hope to achieve relative to the no-perishing setting; we then design an algorithm achieving these lower bounds which takes as input $(i)$ a prediction of the perishing order, and $(ii)$ a desired bound on envy. Given the remaining budget in each period, the algorithm uses forecasts of future demand and perishing to adaptively choose one of two carefully constructed guardrail quantities. We demonstrate our algorithm's strong numerical performance - and state-of-the-art, perishing-agnostic algorithms' inefficacy - on simulations calibrated to a real-world dataset.
The SMART approach to instance-optimal online learning
Feb 27, 2024
We devise an online learning algorithm -- titled Switching via Monotone Adapted Regret Traces (SMART) -- that adapts to the data and achieves regret that is instance optimal, i.e., simultaneously competitive on every input sequence compared to the performance of the follow-the-leader (FTL) policy and the worst case guarantee of any other input policy. We show that the regret of the SMART policy on any input sequence is within a multiplicative factor $e/(e-1) \approx 1.58$ of the smaller of: 1) the regret obtained by FTL on the sequence, and 2) the upper bound on regret guaranteed by the given worst-case policy. This implies a strictly stronger guarantee than typical `best-of-both-worlds' bounds as the guarantee holds for every input sequence regardless of how it is generated. SMART is simple to implement as it begins by playing FTL and switches at most once during the time horizon to the worst-case algorithm. Our approach and results follow from an operational reduction of instance optimal online learning to competitive analysis for the ski-rental problem. We complement our competitive ratio upper bounds with a fundamental lower bound showing that over all input sequences, no algorithm can get better than a $1.43$-fraction of the minimum regret achieved by FTL and the minimax-optimal policy. We also present a modification of SMART that combines FTL with a ``small-loss" algorithm to achieve instance optimality between the regret of FTL and the small loss regret bound.
Artificial Replay: A Meta-Algorithm for Harnessing Historical Data in Bandits
Sep 30, 2022

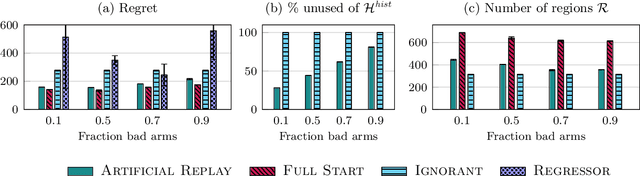
While standard bandit algorithms sometimes incur high regret, their performance can be greatly improved by "warm starting" with historical data. Unfortunately, how best to incorporate historical data is unclear: naively initializing reward estimates using all historical samples can suffer from spurious data and imbalanced data coverage, leading to computational and storage issues - particularly in continuous action spaces. We address these two challenges by proposing Artificial Replay, a meta-algorithm for incorporating historical data into any arbitrary base bandit algorithm. Artificial Replay uses only a subset of the historical data as needed to reduce computation and storage. We show that for a broad class of base algorithms that satisfy independence of irrelevant data (IIData), a novel property that we introduce, our method achieves equal regret as a full warm-start approach while potentially using only a fraction of the historical data. We complement these theoretical results with a case study of $K$-armed and continuous combinatorial bandit algorithms, including on a green security domain using real poaching data, to show the practical benefits of Artificial Replay in achieving optimal regret alongside low computational and storage costs.
Adaptive Discretization in Online Reinforcement Learning
Oct 29, 2021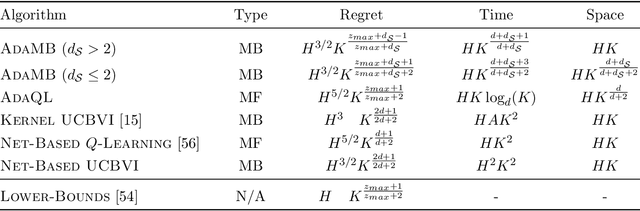

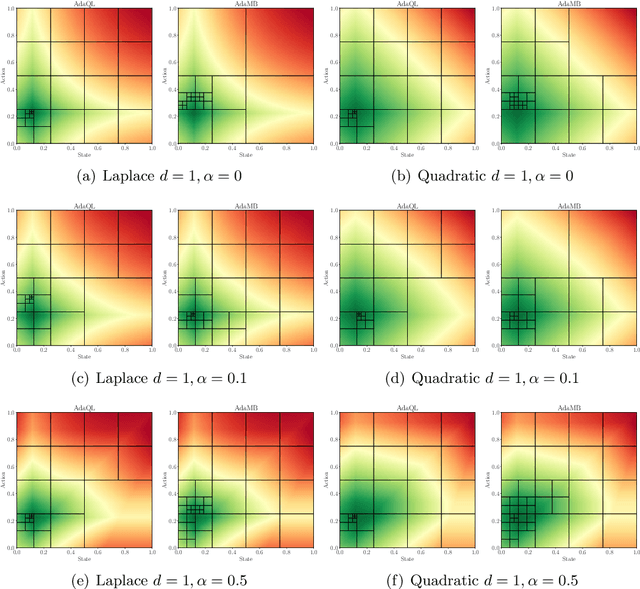
Discretization based approaches to solving online reinforcement learning problems have been studied extensively in practice on applications ranging from resource allocation to cache management. Two major questions in designing discretization-based algorithms are how to create the discretization and when to refine it. While there have been several experimental results investigating heuristic solutions to these questions, there has been little theoretical treatment. In this paper we provide a unified theoretical analysis of tree-based hierarchical partitioning methods for online reinforcement learning, providing model-free and model-based algorithms. We show how our algorithms are able to take advantage of inherent structure of the problem by providing guarantees that scale with respect to the 'zooming dimension' instead of the ambient dimension, an instance-dependent quantity measuring the benignness of the optimal $Q_h^\star$ function. Many applications in computing systems and operations research requires algorithms that compete on three facets: low sample complexity, mild storage requirements, and low computational burden. Our algorithms are easily adapted to operating constraints, and our theory provides explicit bounds across each of the three facets. This motivates its use in practical applications as our approach automatically adapts to underlying problem structure even when very little is known a priori about the system.
Explainable AI for Robot Failures: Generating Explanations that Improve User Assistance in Fault Recovery
Jan 05, 2021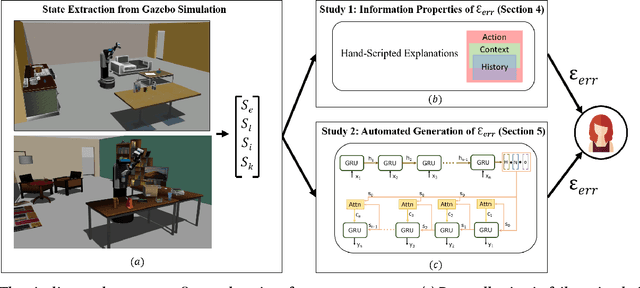

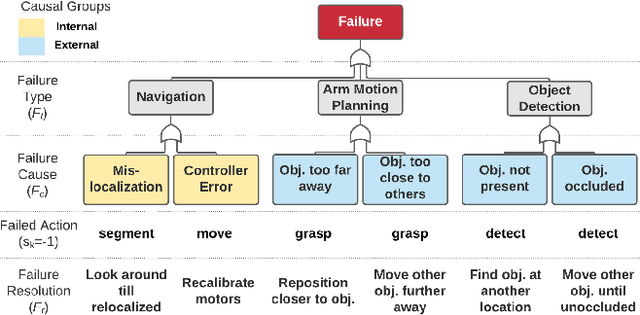
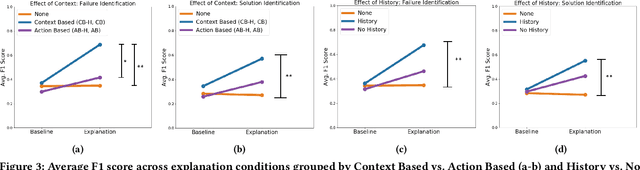
With the growing capabilities of intelligent systems, the integration of robots in our everyday life is increasing. However, when interacting in such complex human environments, the occasional failure of robotic systems is inevitable. The field of explainable AI has sought to make complex-decision making systems more interpretable but most existing techniques target domain experts. On the contrary, in many failure cases, robots will require recovery assistance from non-expert users. In this work, we introduce a new type of explanation, that explains the cause of an unexpected failure during an agent's plan execution to non-experts. In order for error explanations to be meaningful, we investigate what types of information within a set of hand-scripted explanations are most helpful to non-experts for failure and solution identification. Additionally, we investigate how such explanations can be autonomously generated, extending an existing encoder-decoder model, and generalized across environments. We investigate such questions in the context of a robot performing a pick-and-place manipulation task in the home environment. Our results show that explanations capturing the context of a failure and history of past actions, are the most effective for failure and solution identification among non-experts. Furthermore, through a second user evaluation, we verify that our model-generated explanations can generalize to an unseen office environment, and are just as effective as the hand-scripted explanations.
Explainable AI for System Failures: Generating Explanations that Improve Human Assistance in Fault Recovery
Nov 19, 2020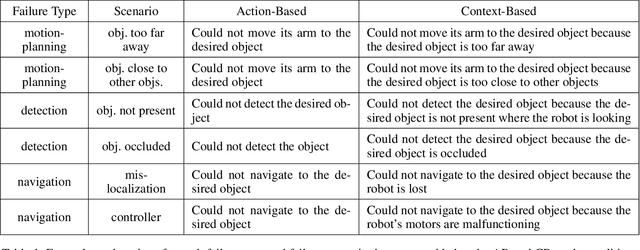

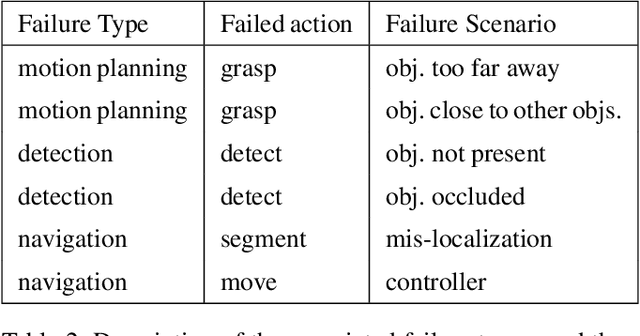
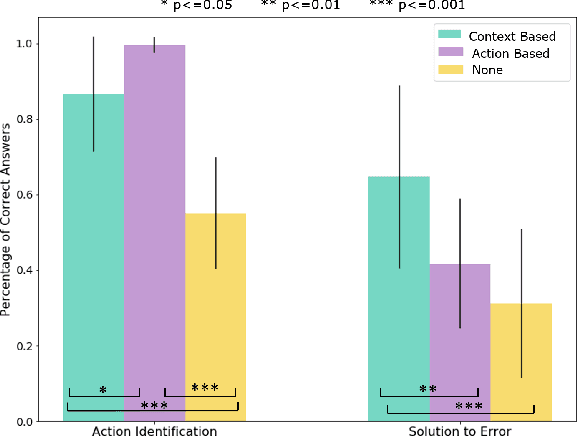
With the growing capabilities of intelligent systems, the integration of artificial intelligence (AI) and robots in everyday life is increasing. However, when interacting in such complex human environments, the failure of intelligent systems, such as robots, can be inevitable, requiring recovery assistance from users. In this work, we develop automated, natural language explanations for failures encountered during an AI agents' plan execution. These explanations are developed with a focus of helping non-expert users understand different point of failures to better provide recovery assistance. Specifically, we introduce a context-based information type for explanations that can both help non-expert users understand the underlying cause of a system failure, and select proper failure recoveries. Additionally, we extend an existing sequence-to-sequence methodology to automatically generate our context-based explanations. By doing so, we are able develop a model that can generalize context-based explanations over both different failure types and failure scenarios.
Adaptive Discretization for Model-Based Reinforcement Learning
Jul 01, 2020
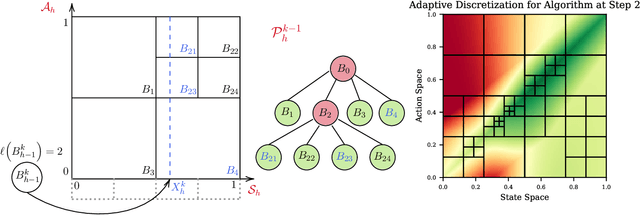
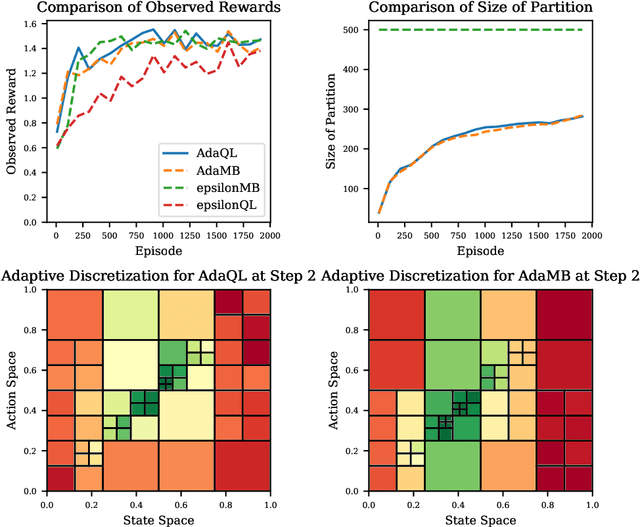

We introduce the technique of adaptive discretization to design efficient model-based episodic reinforcement learning algorithms in large (potentially continuous) state-action spaces. Our algorithm is based on optimistic one-step value iteration extended to maintain an adaptive discretization of the space. From a theoretical perspective, we provide worst-case regret bounds for our algorithm, which are competitive compared to the state-of-the-art model-based algorithms; moreover, our bounds are obtained via a modular proof technique, which can potentially extend to incorporate additional structure on the problem. From an implementation standpoint, our algorithm has much lower storage and computational requirements, due to maintaining a more efficient partition of the state and action spaces. We illustrate this via experiments on several canonical control problems, which shows that our algorithm empirically performs significantly better than fixed discretization in terms of both faster convergence and lower memory usage. Interestingly, we observe empirically that while fixed-discretization model-based algorithms vastly outperform their model-free counterparts, the two achieve comparable performance with adaptive discretization.
Taking Recoveries to Task: Recovery-Driven Development for Recipe-based Robot Tasks
Jan 28, 2020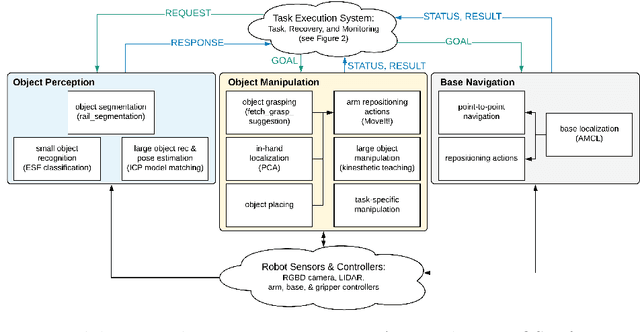
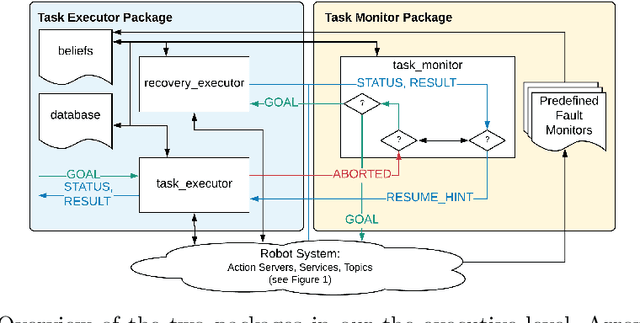

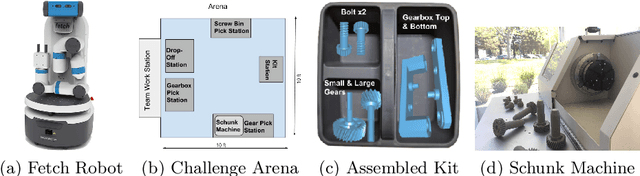
Robot task execution when situated in real-world environments is fragile. As such, robot architectures must rely on robust error recovery, adding non-trivial complexity to highly-complex robot systems. To handle this complexity in development, we introduce Recovery-Driven Development (RDD), an iterative task scripting process that facilitates rapid task and recovery development by leveraging hierarchical specification, separation of nominal task and recovery development, and situated testing. We validate our approach with our challenge-winning mobile manipulator software architecture developed using RDD for the FetchIt! Challenge at the IEEE 2019 International Conference on Robotics and Automation. We attribute the success of our system to the level of robustness achieved using RDD, and conclude with lessons learned for developing such systems.
Adaptive Discretization for Episodic Reinforcement Learning in Metric Spaces
Oct 31, 2019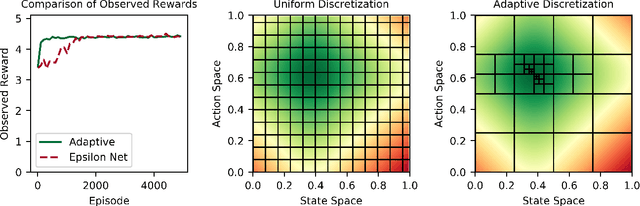
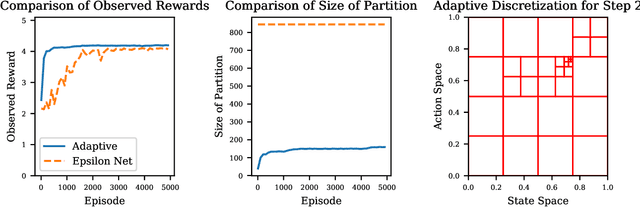
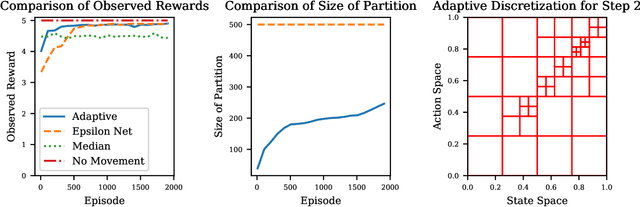
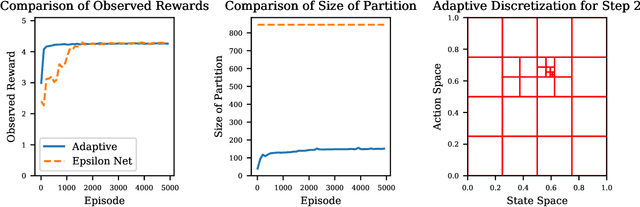
We present an efficient algorithm for model-free episodic reinforcement learning on large (potentially continuous) state-action spaces. Our algorithm is based on a novel $Q$-learning policy with adaptive data-driven discretization. The central idea is to maintain a finer partition of the state-action space in regions which are frequently visited in historical trajectories, and have higher payoff estimates. We demonstrate how our adaptive partitions take advantage of the shape of the optimal $Q$-function and the joint space, without sacrificing the worst-case performance. In particular, we recover the regret guarantees of prior algorithms for continuous state-action spaces, which additionally require either an optimal discretization as input, and/or access to a simulation oracle. Moreover, experiments demonstrate how our algorithm automatically adapts to the underlying structure of the problem, resulting in much better performance compared both to heuristics and $Q$-learning with uniform discretization.