 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-View Splatter: Feed-Forward View Synthesis with Georeferenced Images
May 19, 2026We present Cross-View Splatter, a feed-forward method that predicts pixel-aligned Gaussian splats for outdoor scenes captured at ground level AND by satellite. Faithful reconstructions require good camera coverage, but ground imagery is time-consuming and hard to capture at scale for large outdoor scenes. Fortunately, satellite imagery can provide a global geometric prior that is easy to access via public APIs. Cross-View Splatter fuses orthorectified satellite views with GPS-tagged ground photos to predict Gaussian splats in a unified 3D coordinate frame. By aligning ground and bird's-eye feature representations, our model improves scene coverage and novel-view synthesis, compared to ground imagery alone. We train on curated georeferenced datasets and paired satellite-terrain data, mined from open mapping services. We evaluate our method on a new benchmark for novel-view synthesis with georeferenced imagery allowing comparison to prior state-of-the-art methods. Our code and data preparation will be available at https://nianticspatial.github.io/cross-view-splatter/.
OmniNOCS: A unified NOCS dataset and model for 3D lifting of 2D objects
Jul 11, 2024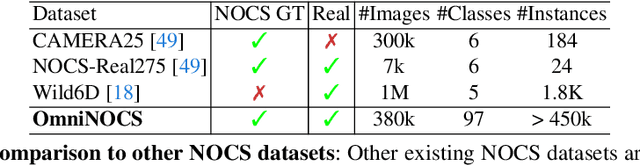


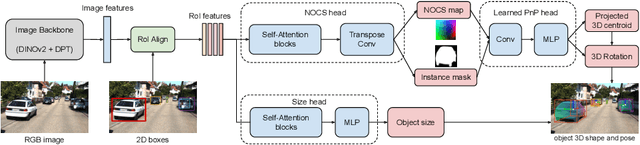
We propose OmniNOCS, a large-scale monocular dataset with 3D Normalized Object Coordinate Space (NOCS) maps, object masks, and 3D bounding box annotations for indoor and outdoor scenes. OmniNOCS has 20 times more object classes and 200 times more instances than existing NOCS datasets (NOCS-Real275, Wild6D). We use OmniNOCS to train a novel, transformer-based monocular NOCS prediction model (NOCSformer) that can predict accurate NOCS, instance masks and poses from 2D object detections across diverse classes. It is the first NOCS model that can generalize to a broad range of classes when prompted with 2D boxes. We evaluate our model on the task of 3D oriented bounding box prediction, where it achieves comparable results to state-of-the-art 3D detection methods such as Cube R-CNN. Unlike other 3D detection methods, our model also provides detailed and accurate 3D object shape and segmentation. We propose a novel benchmark for the task of NOCS prediction based on OmniNOCS, which we hope will serve as a useful baseline for future work in this area. Our dataset and code will be at the project website: https://omninocs.github.io.
Distributed Global Structure-from-Motion with a Deep Front-End
Nov 30, 2023While initial approaches to Structure-from-Motion (SfM) revolved around both global and incremental methods, most recent applications rely on incremental systems to estimate camera poses due to their superior robustness. Though there has been tremendous progress in SfM `front-ends' powered by deep models learned from data, the state-of-the-art (incremental) SfM pipelines still rely on classical SIFT features, developed in 2004. In this work, we investigate whether leveraging the developments in feature extraction and matching helps global SfM perform on par with the SOTA incremental SfM approach (COLMAP). To do so, we design a modular SfM framework that allows us to easily combine developments in different stages of the SfM pipeline. Our experiments show that while developments in deep-learning based two-view correspondence estimation do translate to improvements in point density for scenes reconstructed with global SfM, none of them outperform SIFT when comparing with incremental SfM results on a range of datasets. Our SfM system is designed from the ground up to leverage distributed computation, enabling us to parallelize computation on multiple machines and scale to large scenes.
LANe: Lighting-Aware Neural Fields for Compositional Scene Synthesis
Apr 06, 2023



Neural fields have recently enjoyed great success in representing and rendering 3D scenes. However, most state-of-the-art implicit representations model static or dynamic scenes as a whole, with minor variations. Existing work on learning disentangled world and object neural fields do not consider the problem of composing objects into different world neural fields in a lighting-aware manner. We present Lighting-Aware Neural Field (LANe) for the compositional synthesis of driving scenes in a physically consistent manner. Specifically, we learn a scene representation that disentangles the static background and transient elements into a world-NeRF and class-specific object-NeRFs to allow compositional synthesis of multiple objects in the scene. Furthermore, we explicitly designed both the world and object models to handle lighting variation, which allows us to compose objects into scenes with spatially varying lighting. This is achieved by constructing a light field of the scene and using it in conjunction with a learned shader to modulate the appearance of the object NeRFs. We demonstrate the performance of our model on a synthetic dataset of diverse lighting conditions rendered with the CARLA simulator, as well as a novel real-world dataset of cars collected at different times of the day. Our approach shows that it outperforms state-of-the-art compositional scene synthesis on the challenging dataset setup, via composing object-NeRFs learned from one scene into an entirely different scene whilst still respecting the lighting variations in the novel scene. For more results, please visit our project website https://lane-composition.github.io/.
Taking Recoveries to Task: Recovery-Driven Development for Recipe-based Robot Tasks
Jan 28, 2020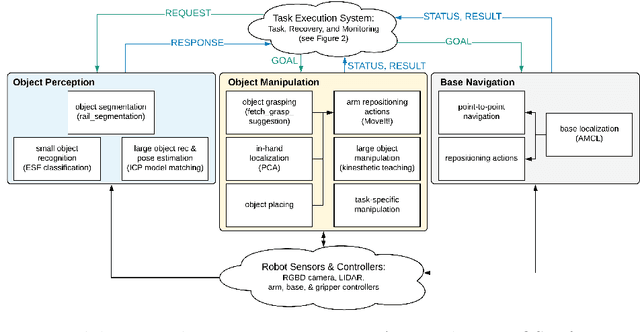
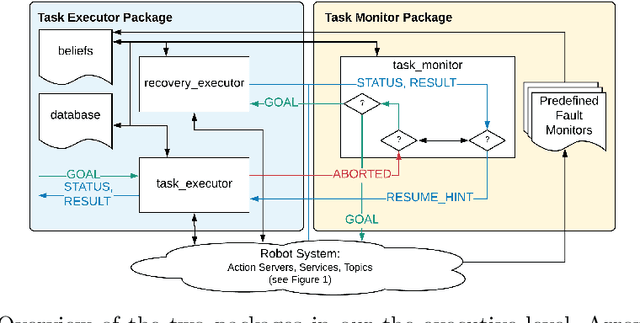

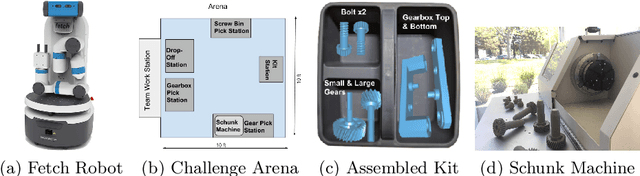
Robot task execution when situated in real-world environments is fragile. As such, robot architectures must rely on robust error recovery, adding non-trivial complexity to highly-complex robot systems. To handle this complexity in development, we introduce Recovery-Driven Development (RDD), an iterative task scripting process that facilitates rapid task and recovery development by leveraging hierarchical specification, separation of nominal task and recovery development, and situated testing. We validate our approach with our challenge-winning mobile manipulator software architecture developed using RDD for the FetchIt! Challenge at the IEEE 2019 International Conference on Robotics and Automation. We attribute the success of our system to the level of robustness achieved using RDD, and conclude with lessons learned for developing such systems.