 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLANe: Lighting-Aware Neural Fields for Compositional Scene Synthesis
Apr 06, 2023



Neural fields have recently enjoyed great success in representing and rendering 3D scenes. However, most state-of-the-art implicit representations model static or dynamic scenes as a whole, with minor variations. Existing work on learning disentangled world and object neural fields do not consider the problem of composing objects into different world neural fields in a lighting-aware manner. We present Lighting-Aware Neural Field (LANe) for the compositional synthesis of driving scenes in a physically consistent manner. Specifically, we learn a scene representation that disentangles the static background and transient elements into a world-NeRF and class-specific object-NeRFs to allow compositional synthesis of multiple objects in the scene. Furthermore, we explicitly designed both the world and object models to handle lighting variation, which allows us to compose objects into scenes with spatially varying lighting. This is achieved by constructing a light field of the scene and using it in conjunction with a learned shader to modulate the appearance of the object NeRFs. We demonstrate the performance of our model on a synthetic dataset of diverse lighting conditions rendered with the CARLA simulator, as well as a novel real-world dataset of cars collected at different times of the day. Our approach shows that it outperforms state-of-the-art compositional scene synthesis on the challenging dataset setup, via composing object-NeRFs learned from one scene into an entirely different scene whilst still respecting the lighting variations in the novel scene. For more results, please visit our project website https://lane-composition.github.io/.
CLONeR: Camera-Lidar Fusion for Occupancy Grid-aided Neural Representations
Sep 06, 2022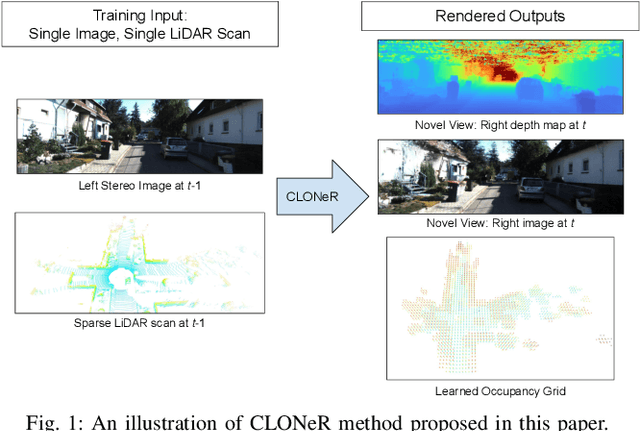

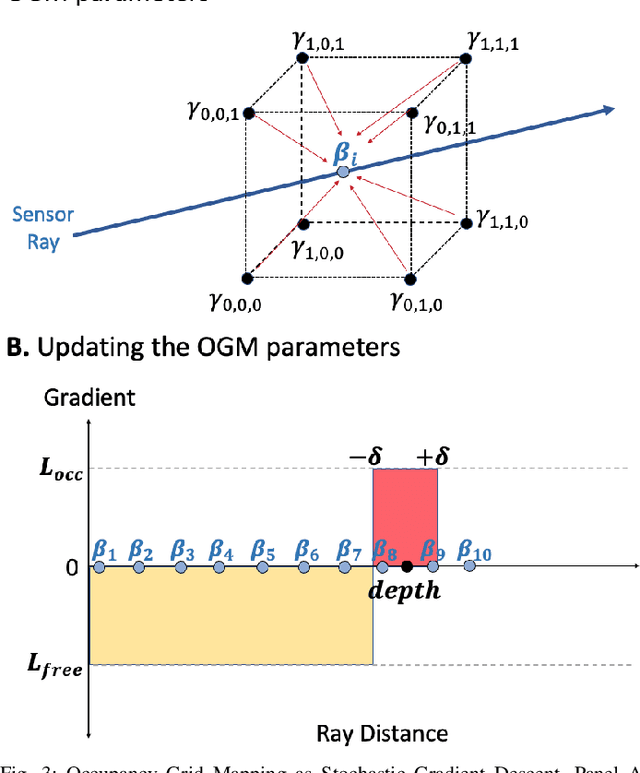

Recent advances in neural radiance fields (NeRFs) achieve state-of-the-art novel view synthesis and facilitate dense estimation of scene properties. However, NeRFs often fail for large, unbounded scenes that are captured under very sparse views with the scene content concentrated far away from the camera, as is typical for field robotics applications. In particular, NeRF-style algorithms perform poorly: (1) when there are insufficient views with little pose diversity, (2) when scenes contain saturation and shadows, and (3) when finely sampling large unbounded scenes with fine structures becomes computationally intensive. This paper proposes CLONeR, which significantly improves upon NeRF by allowing it to model large outdoor driving scenes that are observed from sparse input sensor views. This is achieved by decoupling occupancy and color learning within the NeRF framework into separate Multi-Layer Perceptrons (MLPs) trained using LiDAR and camera data, respectively. In addition, this paper proposes a novel method to build differentiable 3D Occupancy Grid Maps (OGM) alongside the NeRF model, and leverage this occupancy grid for improved sampling of points along a ray for volumetric rendering in metric space. Through extensive quantitative and qualitative experiments on scenes from the KITTI dataset, this paper demonstrates that the proposed method outperforms state-of-the-art NeRF models on both novel view synthesis and dense depth prediction tasks when trained on sparse input data.
Shadow Transfer: Single Image Relighting For Urban Road Scenes
Sep 26, 2019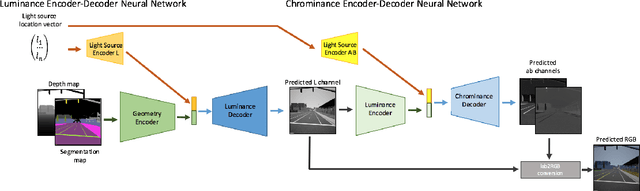



Illumination effects in images, specifically cast shadows and shading, have been shown to decrease the performance of deep neural networks on a large number of vision-based detection, recognition and segmentation tasks in urban driving scenes. A key factor that contributes to this performance gap is the lack of `time-of-day' diversity within real, labeled datasets. There have been impressive advances in the realm of image to image translation in transferring previously unseen visual effects into a dataset, specifically in day to night translation. However, it is not easy to constrain what visual effects, let alone illumination effects, are transferred from one dataset to another during the training process. To address this problem, we propose deep learning framework, called Shadow Transfer, that can relight complex outdoor scenes by transferring realistic shadow, shading, and other lighting effects onto a single image. The novelty of the proposed framework is that it is both self-supervised, and is designed to operate on sensor and label information that is easily available in autonomous vehicle datasets. We show the effectiveness of this method on both synthetic and real datasets, and we provide experiments that demonstrate that the proposed method produces images of higher visual quality than state of the art image to image translation methods.
Modeling Camera Effects to Improve Visual Learning from Synthetic Data
Oct 02, 2018



Recent work has focused on generating synthetic imagery to increase the size and variability of training data for learning visual tasks in urban scenes. This includes increasing the occurrence of occlusions or varying environmental and weather effects. However, few have addressed modeling variation in the sensor domain. Sensor effects can degrade real images, limiting generalizability of network performance on visual tasks trained on synthetic data and tested in real environments. This paper proposes an efficient, automatic, physically-based augmentation pipeline to vary sensor effects --chromatic aberration, blur, exposure, noise, and color cast-- for synthetic imagery. In particular, this paper illustrates that augmenting synthetic training datasets with the proposed pipeline reduces the domain gap between synthetic and real domains for the task of object detection in urban driving scenes.
Sensor Transfer: Learning Optimal Sensor Effect Image Augmentation for Sim-to-Real Domain Adaptation
Sep 17, 2018

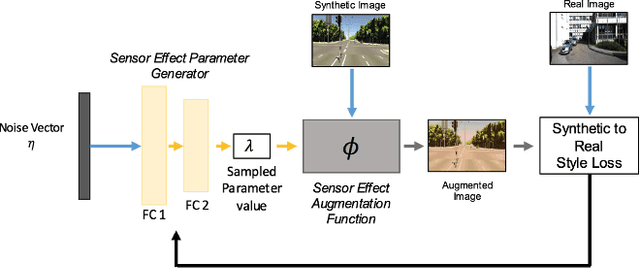

Performance on benchmark datasets has drastically improved with advances in deep learning. Still, cross- dataset generalization performance remains relatively low due to the domain shift that can occur between two different datasets. This domain shift is especially exaggerated between synthetic and real datasets. Significant research has been done to reduce this gap, specifically via modeling variation in the spatial layout of a scene, such as occlusions, and scene environmental factors, such as time of day and weather effects. However, few works have addressed modeling the variation in the sensor domain as a means of reducing the synthetic to real domain gap. The camera or sensor used to capture a dataset introduces artifacts into the image data that are unique to the sensor model, suggesting that sensor effects may also contribute to domain shift. To address this, we propose a learned augmentation network composed of physically-based augmentation functions. Our proposed augmentation pipeline transfers specific effects of the sensor model --chromatic aberration, blur, exposure, noise, and color temperature-- from a real dataset to a synthetic dataset. We provide experiments that demonstrate that augmenting synthetic training datasets with the proposed learned augmentation framework reduces the domain gap between synthetic and real domains for object detection in urban driving scenes.