 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-Manual Joint Camera Calibration and Scene Representation
May 30, 2025



Robot manipulation, especially bimanual manipulation, often requires setting up multiple cameras on multiple robot manipulators. Before robot manipulators can generate motion or even build representations of their environments, the cameras rigidly mounted to the robot need to be calibrated. Camera calibration is a cumbersome process involving collecting a set of images, with each capturing a pre-determined marker. In this work, we introduce the Bi-Manual Joint Calibration and Representation Framework (Bi-JCR). Bi-JCR enables multiple robot manipulators, each with cameras mounted, to circumvent taking images of calibration markers. By leveraging 3D foundation models for dense, marker-free multi-view correspondence, Bi-JCR jointly estimates: (i) the extrinsic transformation from each camera to its end-effector, (ii) the inter-arm relative poses between manipulators, and (iii) a unified, scale-consistent 3D representation of the shared workspace, all from the same captured RGB image sets. The representation, jointly constructed from images captured by cameras on both manipulators, lives in a common coordinate frame and supports collision checking and semantic segmentation to facilitate downstream bimanual coordination tasks. We empirically evaluate the robustness of Bi-JCR on a variety of tabletop environments, and demonstrate its applicability on a variety of downstream tasks.
From Single Images to Motion Policies via Video-Generation Environment Representations
May 25, 2025Autonomous robots typically need to construct representations of their surroundings and adapt their motions to the geometry of their environment. Here, we tackle the problem of constructing a policy model for collision-free motion generation, consistent with the environment, from a single input RGB image. Extracting 3D structures from a single image often involves monocular depth estimation. Developments in depth estimation have given rise to large pre-trained models such as DepthAnything. However, using outputs of these models for downstream motion generation is challenging due to frustum-shaped errors that arise. Instead, we propose a framework known as Video-Generation Environment Representation (VGER), which leverages the advances of large-scale video generation models to generate a moving camera video conditioned on the input image. Frames of this video, which form a multiview dataset, are then input into a pre-trained 3D foundation model to produce a dense point cloud. We then introduce a multi-scale noise approach to train an implicit representation of the environment structure and build a motion generation model that complies with the geometry of the representation. We extensively evaluate VGER over a diverse set of indoor and outdoor environments. We demonstrate its ability to produce smooth motions that account for the captured geometry of a scene, all from a single RGB input image.
GraphSeg: Segmented 3D Representations via Graph Edge Addition and Contraction
Apr 04, 2025Robots operating in unstructured environments often require accurate and consistent object-level representations. This typically requires segmenting individual objects from the robot's surroundings. While recent large models such as Segment Anything (SAM) offer strong performance in 2D image segmentation. These advances do not translate directly to performance in the physical 3D world, where they often over-segment objects and fail to produce consistent mask correspondences across views. In this paper, we present GraphSeg, a framework for generating consistent 3D object segmentations from a sparse set of 2D images of the environment without any depth information. GraphSeg adds edges to graphs and constructs dual correspondence graphs: one from 2D pixel-level similarities and one from inferred 3D structure. We formulate segmentation as a problem of edge addition, then subsequent graph contraction, which merges multiple 2D masks into unified object-level segmentations. We can then leverage \emph{3D foundation models} to produce segmented 3D representations. GraphSeg achieves robust segmentation with significantly fewer images and greater accuracy than prior methods. We demonstrate state-of-the-art performance on tabletop scenes and show that GraphSeg enables improved performance on downstream robotic manipulation tasks. Code available at https://github.com/tomtang502/graphseg.git.
Infinite Leagues Under the Sea: Photorealistic 3D Underwater Terrain Generation by Latent Fractal Diffusion Models
Mar 09, 2025This paper tackles the problem of generating representations of underwater 3D terrain. Off-the-shelf generative models, trained on Internet-scale data but not on specialized underwater images, exhibit downgraded realism, as images of the seafloor are relatively uncommon. To this end, we introduce DreamSea, a generative model to generate hyper-realistic underwater scenes. DreamSea is trained on real-world image databases collected from underwater robot surveys. Images from these surveys contain massive real seafloor observations and covering large areas, but are prone to noise and artifacts from the real world. We extract 3D geometry and semantics from the data with visual foundation models, and train a diffusion model that generates realistic seafloor images in RGBD channels, conditioned on novel fractal distribution-based latent embeddings. We then fuse the generated images into a 3D map, building a 3DGS model supervised by 2D diffusion priors which allows photorealistic novel view rendering. DreamSea is rigorously evaluated, demonstrating the ability to robustly generate large-scale underwater scenes that are consistent, diverse, and photorealistic. Our work drives impact in multiple domains, spanning filming, gaming, and robot simulation.
Towards Ambiguity-Free Spatial Foundation Model: Rethinking and Decoupling Depth Ambiguity
Mar 08, 2025



Depth ambiguity is a fundamental challenge in spatial scene understanding, especially in transparent scenes where single-depth estimates fail to capture full 3D structure. Existing models, limited to deterministic predictions, overlook real-world multi-layer depth. To address this, we introduce a paradigm shift from single-prediction to multi-hypothesis spatial foundation models. We first present \texttt{MD-3k}, a benchmark exposing depth biases in expert and foundational models through multi-layer spatial relationship labels and new metrics. To resolve depth ambiguity, we propose Laplacian Visual Prompting (LVP), a training-free spectral prompting technique that extracts hidden depth from pre-trained models via Laplacian-transformed RGB inputs. By integrating LVP-inferred depth with standard RGB-based estimates, our approach elicits multi-layer depth without model retraining. Extensive experiments validate the effectiveness of LVP in zero-shot multi-layer depth estimation, unlocking more robust and comprehensive geometry-conditioned visual generation, 3D-grounded spatial reasoning, and temporally consistent video-level depth inference. Our benchmark and code will be available at https://github.com/Xiaohao-Xu/Ambiguity-in-Space.
DOSE3 : Diffusion-based Out-of-distribution detection on SE(3) trajectories
Feb 23, 2025Out-of-Distribution(OOD) detection, a fundamental machine learning task aimed at identifying abnormal samples, traditionally requires model retraining for different inlier distributions. While recent research demonstrates the applicability of diffusion models to OOD detection, existing approaches are limited to Euclidean or latent image spaces. Our work extends OOD detection to trajectories in the Special Euclidean Group in 3D ($\mathbb{SE}(3)$), addressing a critical need in computer vision, robotics, and engineering applications that process object pose sequences in $\mathbb{SE}(3)$. We present $\textbf{D}$iffusion-based $\textbf{O}$ut-of-distribution detection on $\mathbb{SE}(3)$ ($\mathbf{DOSE3}$), a novel OOD framework that extends diffusion to a unified sample space of $\mathbb{SE}(3)$ pose sequences. Through extensive validation on multiple benchmark datasets, we demonstrate $\mathbf{DOSE3}$'s superior performance compared to state-of-the-art OOD detection frameworks.
Scalable Benchmarking and Robust Learning for Noise-Free Ego-Motion and 3D Reconstruction from Noisy Video
Jan 24, 2025We aim to redefine robust ego-motion estimation and photorealistic 3D reconstruction by addressing a critical limitation: the reliance on noise-free data in existing models. While such sanitized conditions simplify evaluation, they fail to capture the unpredictable, noisy complexities of real-world environments. Dynamic motion, sensor imperfections, and synchronization perturbations lead to sharp performance declines when these models are deployed in practice, revealing an urgent need for frameworks that embrace and excel under real-world noise. To bridge this gap, we tackle three core challenges: scalable data generation, comprehensive benchmarking, and model robustness enhancement. First, we introduce a scalable noisy data synthesis pipeline that generates diverse datasets simulating complex motion, sensor imperfections, and synchronization errors. Second, we leverage this pipeline to create Robust-Ego3D, a benchmark rigorously designed to expose noise-induced performance degradation, highlighting the limitations of current learning-based methods in ego-motion accuracy and 3D reconstruction quality. Third, we propose Correspondence-guided Gaussian Splatting (CorrGS), a novel test-time adaptation method that progressively refines an internal clean 3D representation by aligning noisy observations with rendered RGB-D frames from clean 3D map, enhancing geometric alignment and appearance restoration through visual correspondence. Extensive experiments on synthetic and real-world data demonstrate that CorrGS consistently outperforms prior state-of-the-art methods, particularly in scenarios involving rapid motion and dynamic illumination.
Robust Bayesian Scene Reconstruction by Leveraging Retrieval-Augmented Priors
Nov 29, 2024



Constructing 3D representations of object geometry is critical for many downstream manipulation tasks. These representations must be built from potentially noisy partial observations. In this work we focus on the problem of reconstructing a multi-object scene from a single RGBD image. Current deep learning approaches to this problem can be brittle to noisy real world observations and out-of-distribution objects. Other approaches that do not rely on training data cannot accurately infer the backside of objects. We propose BRRP, a reconstruction method that can leverage preexisting mesh datasets to build an informative prior during robust probabilistic reconstruction. In order to make our method more efficient, we introduce the concept of retrieval-augmented prior, where we retrieve relevant components of our prior distribution during inference. Our method produces a distribution over object shape that can be used for reconstruction or measuring uncertainty. We evaluate our method in both procedurally generated scenes and in real world scenes. We show our method is more robust than a deep learning approach while being more accurate than a method with an uninformative prior.
SplaTraj: Camera Trajectory Generation with Semantic Gaussian Splatting
Oct 08, 2024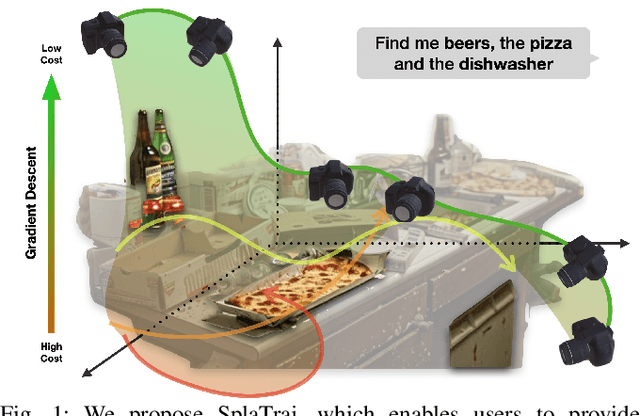
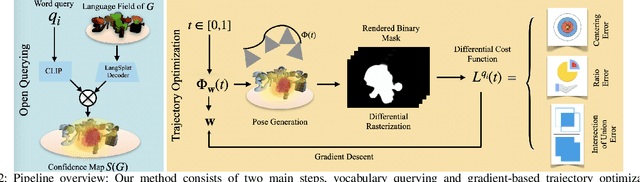


Many recent developments for robots to represent environments have focused on photorealistic reconstructions. This paper particularly focuses on generating sequences of images from the photorealistic Gaussian Splatting models, that match instructions that are given by user-inputted language. We contribute a novel framework, SplaTraj, which formulates the generation of images within photorealistic environment representations as a continuous-time trajectory optimization problem. Costs are designed so that a camera following the trajectory poses will smoothly traverse through the environment and render the specified spatial information in a photogenic manner. This is achieved by querying a photorealistic representation with language embedding to isolate regions that correspond to the user-specified inputs. These regions are then projected to the camera's view as it moves over time and a cost is constructed. We can then apply gradient-based optimization and differentiate through the rendering to optimize the trajectory for the defined cost. The resulting trajectory moves to photogenically view each of the specified objects. We empirically evaluate our approach on a suite of environments and instructions, and demonstrate the quality of generated image sequences.
PhotoReg: Photometrically Registering 3D Gaussian Splatting Models
Oct 07, 2024



Building accurate representations of the environment is critical for intelligent robots to make decisions during deployment. Advances in photorealistic environment models have enabled robots to develop hyper-realistic reconstructions, which can be used to generate images that are intuitive for human inspection. In particular, the recently introduced \ac{3DGS}, which describes the scene with up to millions of primitive ellipsoids, can be rendered in real time. \ac{3DGS} has rapidly gained prominence. However, a critical unsolved problem persists: how can we fuse multiple \ac{3DGS} into a single coherent model? Solving this problem will enable robot teams to jointly build \ac{3DGS} models of their surroundings. A key insight of this work is to leverage the {duality} between photorealistic reconstructions, which render realistic 2D images from 3D structure, and \emph{3D foundation models}, which predict 3D structure from image pairs. To this end, we develop PhotoReg, a framework to register multiple photorealistic \ac{3DGS} models with 3D foundation models. As \ac{3DGS} models are generally built from monocular camera images, they have \emph{arbitrary scale}. To resolve this, PhotoReg actively enforces scale consistency among the different \ac{3DGS} models by considering depth estimates within these models. Then, the alignment is iteratively refined with fine-grained photometric losses to produce high-quality fused \ac{3DGS} models. We rigorously evaluate PhotoReg on both standard benchmark datasets and our custom-collected datasets, including with two quadruped robots. The code is released at \url{ziweny11.github.io/photoreg}.