 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAirIO: Learning Inertial Odometry with Enhanced IMU Feature Observability
Jan 26, 2025



Inertial odometry (IO) using only Inertial Measurement Units (IMUs) offers a lightweight and cost-effective solution for Unmanned Aerial Vehicle (UAV) applications, yet existing learning-based IO models often fail to generalize to UAVs due to the highly dynamic and non-linear-flight patterns that differ from pedestrian motion. In this work, we identify that the conventional practice of transforming raw IMU data to global coordinates undermines the observability of critical kinematic information in UAVs. By preserving the body-frame representation, our method achieves substantial performance improvements, with a 66.7% average increase in accuracy across three datasets. Furthermore, explicitly encoding attitude information into the motion network results in an additional 23.8% improvement over prior results. Combined with a data-driven IMU correction model (AirIMU) and an uncertainty-aware Extended Kalman Filter (EKF), our approach ensures robust state estimation under aggressive UAV maneuvers without relying on external sensors or control inputs. Notably, our method also demonstrates strong generalizability to unseen data not included in the training set, underscoring its potential for real-world UAV applications.
Scalable Benchmarking and Robust Learning for Noise-Free Ego-Motion and 3D Reconstruction from Noisy Video
Jan 24, 2025We aim to redefine robust ego-motion estimation and photorealistic 3D reconstruction by addressing a critical limitation: the reliance on noise-free data in existing models. While such sanitized conditions simplify evaluation, they fail to capture the unpredictable, noisy complexities of real-world environments. Dynamic motion, sensor imperfections, and synchronization perturbations lead to sharp performance declines when these models are deployed in practice, revealing an urgent need for frameworks that embrace and excel under real-world noise. To bridge this gap, we tackle three core challenges: scalable data generation, comprehensive benchmarking, and model robustness enhancement. First, we introduce a scalable noisy data synthesis pipeline that generates diverse datasets simulating complex motion, sensor imperfections, and synchronization errors. Second, we leverage this pipeline to create Robust-Ego3D, a benchmark rigorously designed to expose noise-induced performance degradation, highlighting the limitations of current learning-based methods in ego-motion accuracy and 3D reconstruction quality. Third, we propose Correspondence-guided Gaussian Splatting (CorrGS), a novel test-time adaptation method that progressively refines an internal clean 3D representation by aligning noisy observations with rendered RGB-D frames from clean 3D map, enhancing geometric alignment and appearance restoration through visual correspondence. Extensive experiments on synthetic and real-world data demonstrate that CorrGS consistently outperforms prior state-of-the-art methods, particularly in scenarios involving rapid motion and dynamic illumination.
MAC-Ego3D: Multi-Agent Gaussian Consensus for Real-Time Collaborative Ego-Motion and Photorealistic 3D Reconstruction
Dec 12, 2024



Real-time multi-agent collaboration for ego-motion estimation and high-fidelity 3D reconstruction is vital for scalable spatial intelligence. However, traditional methods produce sparse, low-detail maps, while recent dense mapping approaches struggle with high latency. To overcome these challenges, we present MAC-Ego3D, a novel framework for real-time collaborative photorealistic 3D reconstruction via Multi-Agent Gaussian Consensus. MAC-Ego3D enables agents to independently construct, align, and iteratively refine local maps using a unified Gaussian splat representation. Through Intra-Agent Gaussian Consensus, it enforces spatial coherence among neighboring Gaussian splats within an agent. For global alignment, parallelized Inter-Agent Gaussian Consensus, which asynchronously aligns and optimizes local maps by regularizing multi-agent Gaussian splats, seamlessly integrates them into a high-fidelity 3D model. Leveraging Gaussian primitives, MAC-Ego3D supports efficient RGB-D rendering, enabling rapid inter-agent Gaussian association and alignment. MAC-Ego3D bridges local precision and global coherence, delivering higher efficiency, largely reducing localization error, and improving mapping fidelity. It establishes a new SOTA on synthetic and real-world benchmarks, achieving a 15x increase in inference speed, order-of-magnitude reductions in ego-motion estimation error for partial cases, and RGB PSNR gains of 4 to 10 dB. Our code will be made publicly available at https://github.com/Xiaohao-Xu/MAC-Ego3D .
SuperLoc: The Key to Robust LiDAR-Inertial Localization Lies in Predicting Alignment Risks
Dec 03, 2024



Map-based LiDAR localization, while widely used in autonomous systems, faces significant challenges in degraded environments due to lacking distinct geometric features. This paper introduces SuperLoc, a robust LiDAR localization package that addresses key limitations in existing methods. SuperLoc features a novel predictive alignment risk assessment technique, enabling early detection and mitigation of potential failures before optimization. This approach significantly improves performance in challenging scenarios such as corridors, tunnels, and caves. Unlike existing degeneracy mitigation algorithms that rely on post-optimization analysis and heuristic thresholds, SuperLoc evaluates the localizability of raw sensor measurements. Experimental results demonstrate significant performance improvements over state-of-the-art methods across various degraded environments. Our approach achieves a 54% increase in accuracy and exhibits the highest robustness. To facilitate further research, we release our implementation along with datasets from eight challenging scenarios
MVCTrack: Boosting 3D Point Cloud Tracking via Multimodal-Guided Virtual Cues
Dec 03, 2024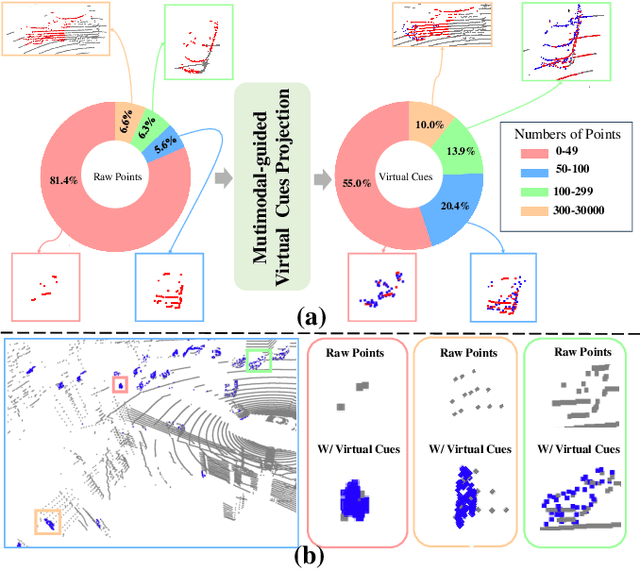
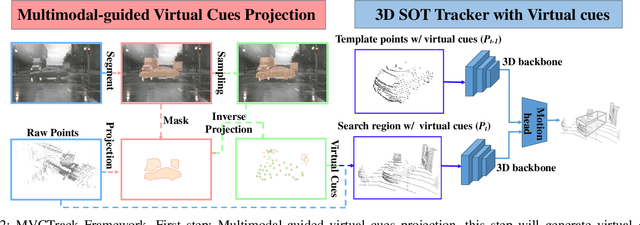
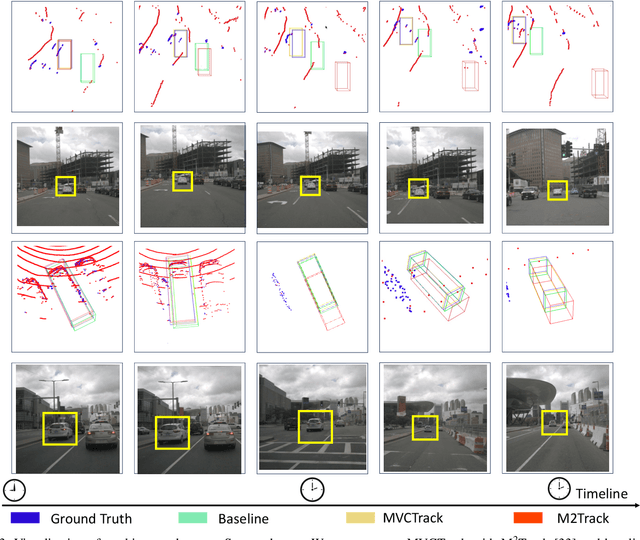

3D single object tracking is essential in autonomous driving and robotics. Existing methods often struggle with sparse and incomplete point cloud scenarios. To address these limitations, we propose a Multimodal-guided Virtual Cues Projection (MVCP) scheme that generates virtual cues to enrich sparse point clouds. Additionally, we introduce an enhanced tracker MVCTrack based on the generated virtual cues. Specifically, the MVCP scheme seamlessly integrates RGB sensors into LiDAR-based systems, leveraging a set of 2D detections to create dense 3D virtual cues that significantly improve the sparsity of point clouds. These virtual cues can naturally integrate with existing LiDAR-based 3D trackers, yielding substantial performance gains. Extensive experiments demonstrate that our method achieves competitive performance on the NuScenes dataset.
PTQ4RIS: Post-Training Quantization for Referring Image Segmentation
Sep 25, 2024Referring Image Segmentation (RIS), aims to segment the object referred by a given sentence in an image by understanding both visual and linguistic information. However, existing RIS methods tend to explore top-performance models, disregarding considerations for practical applications on resources-limited edge devices. This oversight poses a significant challenge for on-device RIS inference. To this end, we propose an effective and efficient post-training quantization framework termed PTQ4RIS. Specifically, we first conduct an in-depth analysis of the root causes of performance degradation in RIS model quantization and propose dual-region quantization (DRQ) and reorder-based outlier-retained quantization (RORQ) to address the quantization difficulties in visual and text encoders. Extensive experiments on three benchmarks with different bits settings (from 8 to 4 bits) demonstrates its superior performance. Importantly, we are the first PTQ method specifically designed for the RIS task, highlighting the feasibility of PTQ in RIS applications. Code will be available at {https://github.com/gugu511yy/PTQ4RIS}.
Toward General-Purpose Robots via Foundation Models: A Survey and Meta-Analysis
Dec 15, 2023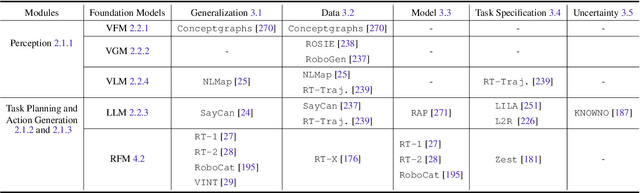

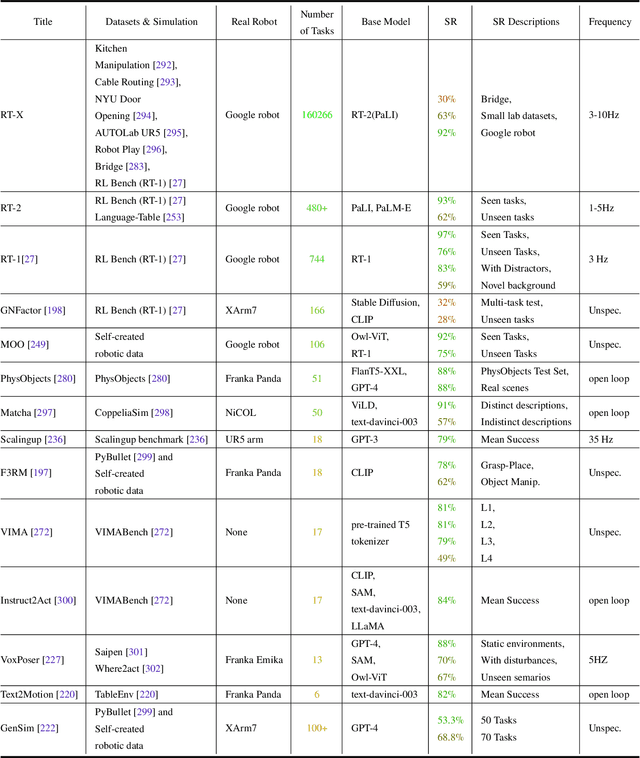
Building general-purpose robots that can operate seamlessly, in any environment, with any object, and utilizing various skills to complete diverse tasks has been a long-standing goal in Artificial Intelligence. Unfortunately, however, most existing robotic systems have been constrained - having been designed for specific tasks, trained on specific datasets, and deployed within specific environments. These systems usually require extensively-labeled data, rely on task-specific models, have numerous generalization issues when deployed in real-world scenarios, and struggle to remain robust to distribution shifts. Motivated by the impressive open-set performance and content generation capabilities of web-scale, large-capacity pre-trained models (i.e., foundation models) in research fields such as Natural Language Processing (NLP) and Computer Vision (CV), we devote this survey to exploring (i) how these existing foundation models from NLP and CV can be applied to the field of robotics, and also exploring (ii) what a robotics-specific foundation model would look like. We begin by providing an overview of what constitutes a conventional robotic system and the fundamental barriers to making it universally applicable. Next, we establish a taxonomy to discuss current work exploring ways to leverage existing foundation models for robotics and develop ones catered to robotics. Finally, we discuss key challenges and promising future directions in using foundation models for enabling general-purpose robotic systems. We encourage readers to view our living GitHub repository of resources, including papers reviewed in this survey as well as related projects and repositories for developing foundation models for robotics.
SubT-MRS: A Subterranean, Multi-Robot, Multi-Spectral and Multi-Degraded Dataset for Robust SLAM
Aug 02, 2023



In recent years, significant progress has been made in the field of simultaneous localization and mapping (SLAM) research. However, current state-of-the-art solutions still struggle with limited accuracy and robustness in real-world applications. One major reason is the lack of datasets that fully capture the conditions faced by robots in the wild. To address this problem, we present SubT-MRS, an extremely challenging real-world dataset designed to push the limits of SLAM and perception algorithms. SubT-MRS is a multi-modal, multi-robot dataset collected mainly from subterranean environments having multi-degraded conditions including structureless corridors, varying lighting conditions, and perceptual obscurants such as smoke and dust. Furthermore, the dataset packages information from a diverse range of time-synchronized sensors, including LiDAR, visual cameras, thermal cameras, and IMUs captured using varied vehicular motions like aerial, legged, and wheeled, to support research in sensor fusion, which is essential for achieving accurate and robust robotic perception in complex environments. To evaluate the accuracy of SLAM systems, we also provide a dense 3D model with sub-centimeter-level accuracy, as well as accurate 6DoF ground truth. Our benchmarking approach includes several state-of-the-art methods to demonstrate the challenges our datasets introduce, particularly in the case of multi-degraded environments.
PyPose: A Library for Robot Learning with Physics-based Optimization
Sep 30, 2022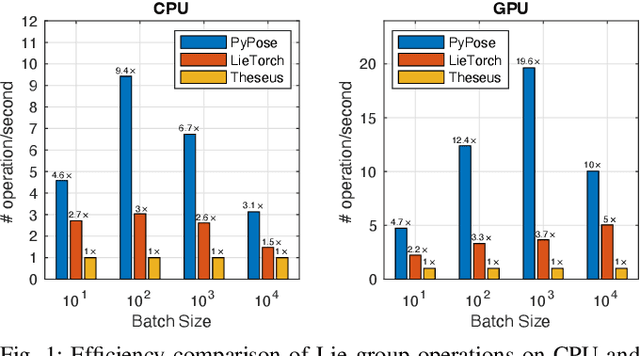
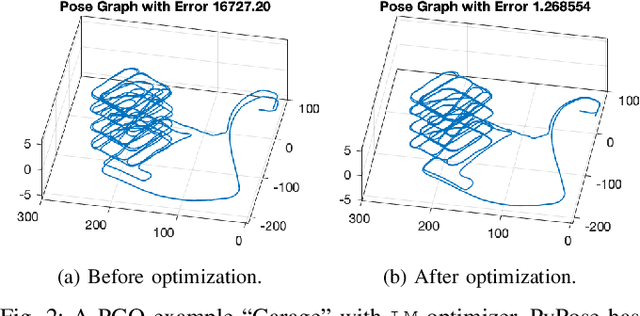
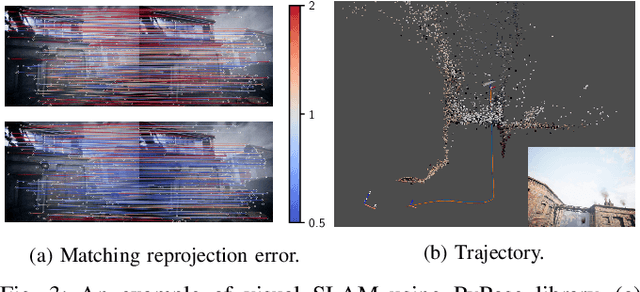
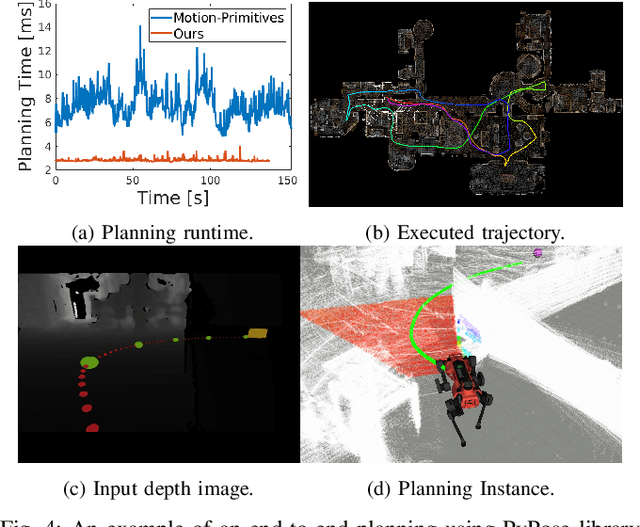
Deep learning has had remarkable success in robotic perception, but its data-centric nature suffers when it comes to generalizing to ever-changing environments. By contrast, physics-based optimization generalizes better, but it does not perform as well in complicated tasks due to the lack of high-level semantic information and the reliance on manual parametric tuning. To take advantage of these two complementary worlds, we present PyPose: a robotics-oriented, PyTorch-based library that combines deep perceptual models with physics-based optimization techniques. Our design goal for PyPose is to make it user-friendly, efficient, and interpretable with a tidy and well-organized architecture. Using an imperative style interface, it can be easily integrated into real-world robotic applications. Besides, it supports parallel computing of any order gradients of Lie groups and Lie algebras and $2^{\text{nd}}$-order optimizers, such as trust region methods. Experiments show that PyPose achieves 3-20$\times$ speedup in computation compared to state-of-the-art libraries. To boost future research, we provide concrete examples across several fields of robotics, including SLAM, inertial navigation, planning, and control.
Present and Future of SLAM in Extreme Underground Environments
Aug 02, 2022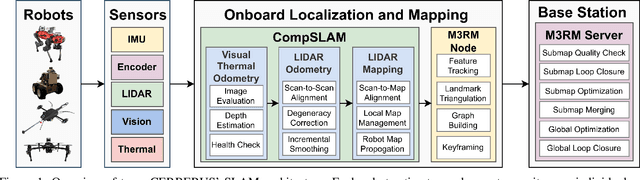
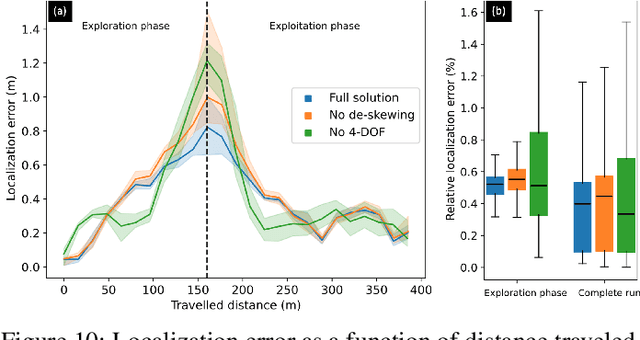
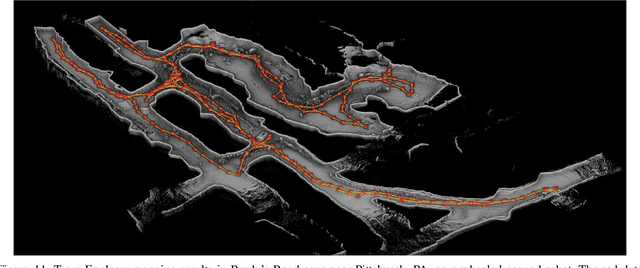
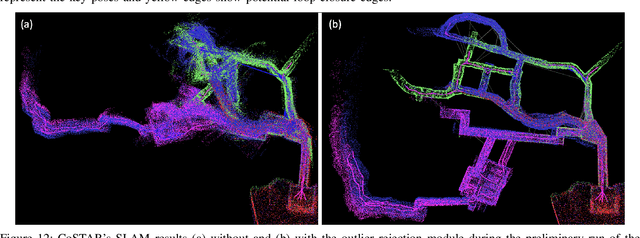
This paper reports on the state of the art in underground SLAM by discussing different SLAM strategies and results across six teams that participated in the three-year-long SubT competition. In particular, the paper has four main goals. First, we review the algorithms, architectures, and systems adopted by the teams; particular emphasis is put on lidar-centric SLAM solutions (the go-to approach for virtually all teams in the competition), heterogeneous multi-robot operation (including both aerial and ground robots), and real-world underground operation (from the presence of obscurants to the need to handle tight computational constraints). We do not shy away from discussing the dirty details behind the different SubT SLAM systems, which are often omitted from technical papers. Second, we discuss the maturity of the field by highlighting what is possible with the current SLAM systems and what we believe is within reach with some good systems engineering. Third, we outline what we believe are fundamental open problems, that are likely to require further research to break through. Finally, we provide a list of open-source SLAM implementations and datasets that have been produced during the SubT challenge and related efforts, and constitute a useful resource for researchers and practitioners.