 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Me: Confidence-Guided Token Merging for Visual Geometric Transformers
Nov 18, 2025We propose Confidence-Guided Token Merging (Co-Me), an acceleration mechanism for visual geometric transformers without retraining or finetuning the base model. Co-Me distilled a light-weight confidence predictor to rank tokens by uncertainty and selectively merge low-confidence ones, effectively reducing computation while maintaining spatial coverage. Compared to similarity-based merging or pruning, the confidence signal in Co-Me reliably indicates regions emphasized by the transformer, enabling substantial acceleration without degrading performance. Co-Me applies seamlessly to various multi-view and streaming visual geometric transformers, achieving speedups that scale with sequence length. When applied to VGGT and MapAnything, Co-Me achieves up to $11.3\times$ and $7.2\times$ speedup, making visual geometric transformers practical for real-time 3D perception and reconstruction.
UFM: A Simple Path towards Unified Dense Correspondence with Flow
Jun 10, 2025Dense image correspondence is central to many applications, such as visual odometry, 3D reconstruction, object association, and re-identification. Historically, dense correspondence has been tackled separately for wide-baseline scenarios and optical flow estimation, despite the common goal of matching content between two images. In this paper, we develop a Unified Flow & Matching model (UFM), which is trained on unified data for pixels that are co-visible in both source and target images. UFM uses a simple, generic transformer architecture that directly regresses the (u,v) flow. It is easier to train and more accurate for large flows compared to the typical coarse-to-fine cost volumes in prior work. UFM is 28% more accurate than state-of-the-art flow methods (Unimatch), while also having 62% less error and 6.7x faster than dense wide-baseline matchers (RoMa). UFM is the first to demonstrate that unified training can outperform specialized approaches across both domains. This result enables fast, general-purpose correspondence and opens new directions for multi-modal, long-range, and real-time correspondence tasks.
TartanGround: A Large-Scale Dataset for Ground Robot Perception and Navigation
May 15, 2025We present TartanGround, a large-scale, multi-modal dataset to advance the perception and autonomy of ground robots operating in diverse environments. This dataset, collected in various photorealistic simulation environments includes multiple RGB stereo cameras for 360-degree coverage, along with depth, optical flow, stereo disparity, LiDAR point clouds, ground truth poses, semantic segmented images, and occupancy maps with semantic labels. Data is collected using an integrated automatic pipeline, which generates trajectories mimicking the motion patterns of various ground robot platforms, including wheeled and legged robots. We collect 910 trajectories across 70 environments, resulting in 1.5 million samples. Evaluations on occupancy prediction and SLAM tasks reveal that state-of-the-art methods trained on existing datasets struggle to generalize across diverse scenes. TartanGround can serve as a testbed for training and evaluation of a broad range of learning-based tasks, including occupancy prediction, SLAM, neural scene representation, perception-based navigation, and more, enabling advancements in robotic perception and autonomy towards achieving robust models generalizable to more diverse scenarios. The dataset and codebase for data collection will be made publicly available upon acceptance. Webpage: https://tartanair.org/tartanground
Imperative MPC: An End-to-End Self-Supervised Learning with Differentiable MPC for UAV Attitude Control
Apr 17, 2025



Modeling and control of nonlinear dynamics are critical in robotics, especially in scenarios with unpredictable external influences and complex dynamics. Traditional cascaded modular control pipelines often yield suboptimal performance due to conservative assumptions and tedious parameter tuning. Pure data-driven approaches promise robust performance but suffer from low sample efficiency, sim-to-real gaps, and reliance on extensive datasets. Hybrid methods combining learning-based and traditional model-based control in an end-to-end manner offer a promising alternative. This work presents a self-supervised learning framework combining learning-based inertial odometry (IO) module and differentiable model predictive control (d-MPC) for Unmanned Aerial Vehicle (UAV) attitude control. The IO denoises raw IMU measurements and predicts UAV attitudes, which are then optimized by MPC for control actions in a bi-level optimization (BLO) setup, where the inner MPC optimizes control actions and the upper level minimizes discrepancy between real-world and predicted performance. The framework is thus end-to-end and can be trained in a self-supervised manner. This approach combines the strength of learning-based perception with the interpretable model-based control. Results show the effectiveness even under strong wind. It can simultaneously enhance both the MPC parameter learning and IMU prediction performance.
RayFronts: Open-Set Semantic Ray Frontiers for Online Scene Understanding and Exploration
Apr 09, 2025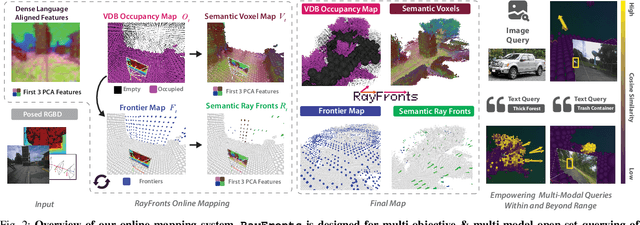
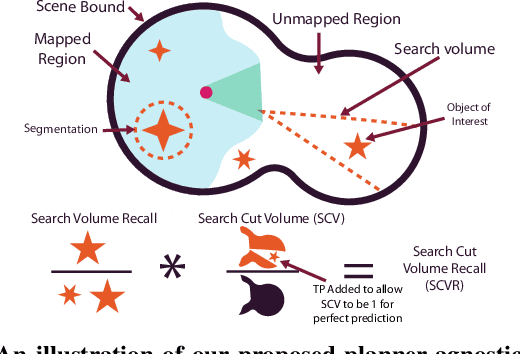
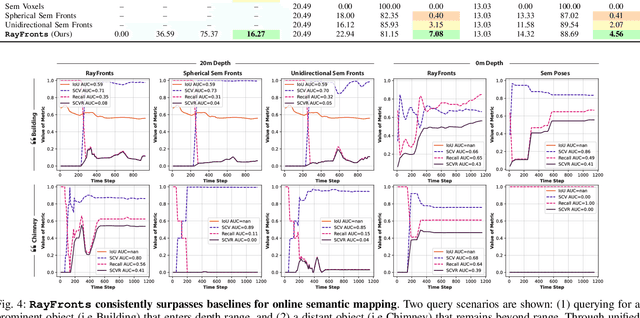
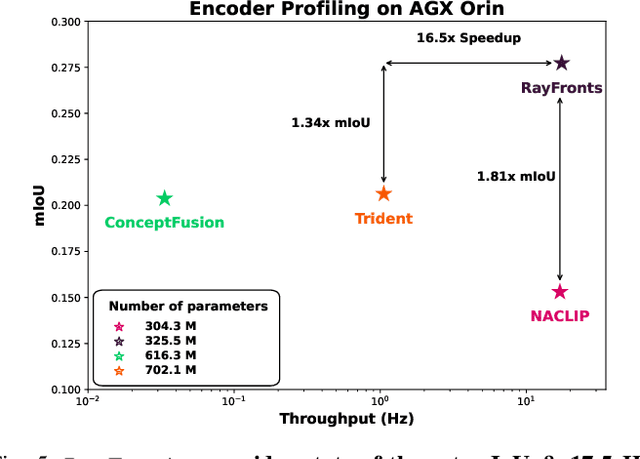
Open-set semantic mapping is crucial for open-world robots. Current mapping approaches either are limited by the depth range or only map beyond-range entities in constrained settings, where overall they fail to combine within-range and beyond-range observations. Furthermore, these methods make a trade-off between fine-grained semantics and efficiency. We introduce RayFronts, a unified representation that enables both dense and beyond-range efficient semantic mapping. RayFronts encodes task-agnostic open-set semantics to both in-range voxels and beyond-range rays encoded at map boundaries, empowering the robot to reduce search volumes significantly and make informed decisions both within & beyond sensory range, while running at 8.84 Hz on an Orin AGX. Benchmarking the within-range semantics shows that RayFronts's fine-grained image encoding provides 1.34x zero-shot 3D semantic segmentation performance while improving throughput by 16.5x. Traditionally, online mapping performance is entangled with other system components, complicating evaluation. We propose a planner-agnostic evaluation framework that captures the utility for online beyond-range search and exploration, and show RayFronts reduces search volume 2.2x more efficiently than the closest online baselines.
AirIO: Learning Inertial Odometry with Enhanced IMU Feature Observability
Jan 26, 2025



Inertial odometry (IO) using only Inertial Measurement Units (IMUs) offers a lightweight and cost-effective solution for Unmanned Aerial Vehicle (UAV) applications, yet existing learning-based IO models often fail to generalize to UAVs due to the highly dynamic and non-linear-flight patterns that differ from pedestrian motion. In this work, we identify that the conventional practice of transforming raw IMU data to global coordinates undermines the observability of critical kinematic information in UAVs. By preserving the body-frame representation, our method achieves substantial performance improvements, with a 66.7% average increase in accuracy across three datasets. Furthermore, explicitly encoding attitude information into the motion network results in an additional 23.8% improvement over prior results. Combined with a data-driven IMU correction model (AirIMU) and an uncertainty-aware Extended Kalman Filter (EKF), our approach ensures robust state estimation under aggressive UAV maneuvers without relying on external sensors or control inputs. Notably, our method also demonstrates strong generalizability to unseen data not included in the training set, underscoring its potential for real-world UAV applications.
SuperLoc: The Key to Robust LiDAR-Inertial Localization Lies in Predicting Alignment Risks
Dec 03, 2024



Map-based LiDAR localization, while widely used in autonomous systems, faces significant challenges in degraded environments due to lacking distinct geometric features. This paper introduces SuperLoc, a robust LiDAR localization package that addresses key limitations in existing methods. SuperLoc features a novel predictive alignment risk assessment technique, enabling early detection and mitigation of potential failures before optimization. This approach significantly improves performance in challenging scenarios such as corridors, tunnels, and caves. Unlike existing degeneracy mitigation algorithms that rely on post-optimization analysis and heuristic thresholds, SuperLoc evaluates the localizability of raw sensor measurements. Experimental results demonstrate significant performance improvements over state-of-the-art methods across various degraded environments. Our approach achieves a 54% increase in accuracy and exhibits the highest robustness. To facilitate further research, we release our implementation along with datasets from eight challenging scenarios
MAC-VO: Metrics-aware Covariance for Learning-based Stereo Visual Odometry
Sep 14, 2024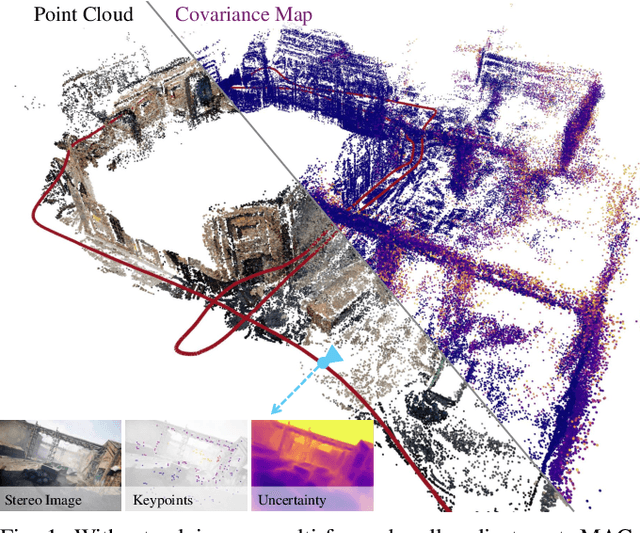
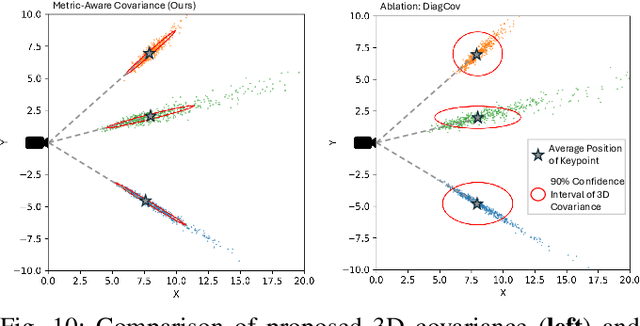
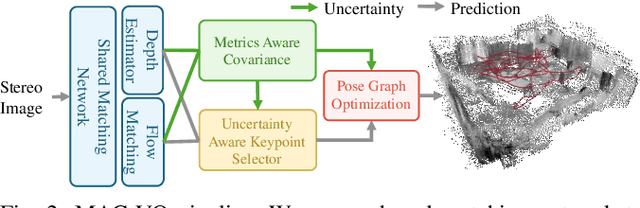
We propose the MAC-VO, a novel learning-based stereo VO that leverages the learned metrics-aware matching uncertainty for dual purposes: selecting keypoint and weighing the residual in pose graph optimization. Compared to traditional geometric methods prioritizing texture-affluent features like edges, our keypoint selector employs the learned uncertainty to filter out the low-quality features based on global inconsistency. In contrast to the learning-based algorithms that model the scale-agnostic diagonal weight matrix for covariance, we design a metrics-aware covariance model to capture the spatial error during keypoint registration and the correlations between different axes. Integrating this covariance model into pose graph optimization enhances the robustness and reliability of pose estimation, particularly in challenging environments with varying illumination, feature density, and motion patterns. On public benchmark datasets, MAC-VO outperforms existing VO algorithms and even some SLAM algorithms in challenging environments. The covariance map also provides valuable information about the reliability of the estimated poses, which can benefit decision-making for autonomous systems.
Imperative Learning: A Self-supervised Neural-Symbolic Learning Framework for Robot Autonomy
Jun 23, 2024



Data-driven methods such as reinforcement and imitation learning have achieved remarkable success in robot autonomy. However, their data-centric nature still hinders them from generalizing well to ever-changing environments. Moreover, collecting large datasets for robotic tasks is often impractical and expensive. To overcome these challenges, we introduce a new self-supervised neural-symbolic (NeSy) computational framework, imperative learning (IL), for robot autonomy, leveraging the generalization abilities of symbolic reasoning. The framework of IL consists of three primary components: a neural module, a reasoning engine, and a memory system. We formulate IL as a special bilevel optimization (BLO), which enables reciprocal learning over the three modules. This overcomes the label-intensive obstacles associated with data-driven approaches and takes advantage of symbolic reasoning concerning logical reasoning, physical principles, geometric analysis, etc. We discuss several optimization techniques for IL and verify their effectiveness in five distinct robot autonomy tasks including path planning, rule induction, optimal control, visual odometry, and multi-robot routing. Through various experiments, we show that IL can significantly enhance robot autonomy capabilities and we anticipate that it will catalyze further research across diverse domains.
AirIMU: Learning Uncertainty Propagation for Inertial Odometry
Oct 12, 2023



Accurate uncertainty estimation for inertial odometry is the foundation to achieve optimal fusion in multi-sensor systems, such as visual or LiDAR inertial odometry. Prior studies often simplify the assumptions regarding the uncertainty of inertial measurements, presuming fixed covariance parameters and empirical IMU sensor models. However, the inherent physical limitations and non-linear characteristics of sensors are difficult to capture. Moreover, uncertainty may fluctuate based on sensor rates and motion modalities, leading to variations across different IMUs. To address these challenges, we formulate a learning-based method that not only encapsulate the non-linearities inherent to IMUs but also ensure the accurate propagation of covariance in a data-driven manner. We extend the PyPose library to enable differentiable batched IMU integration with covariance propagation on manifolds, leading to significant runtime speedup. To demonstrate our method's adaptability, we evaluate it on several benchmarks as well as a large-scale helicopter dataset spanning over 262 kilometers. The drift rate of the inertial odometry on these datasets is reduced by a factor of between 2.2 and 4 times. Our method lays the groundwork for advanced developments in inertial odometry.