 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Planning in Dynamic Environments: A Survey from Classical to Modern Methods
Jun 01, 2026Motion planning in dynamic environments requires robots to continuously adapt their paths in response to environmental changes for safe and uninterrupted navigation. While many surveys have reviewed planning in static settings, systematic reviews focused on dynamic environments remain limited. This paper presents a comprehensive survey of 138 works, primarily published between 2015 and 2025, spanning both classical and learning-based approaches. The motion planning methods are grouped into five categories based on the concepts of sampling, graph search, model predictive control, learning, and additional classical local planning approaches, including velocity obstacles, potential fields and dynamic windows. The learning techniques include supervised learning and reinforcement learning. We also discuss the role of dynamic perception in motion planning, covering techniques for detecting and modeling moving obstacles using cameras, LiDAR, and event-based sensors. The survey analyzes the principles, strengths, and limitations of each method, with particular attention to challenges unique to dynamic environments, such as prediction uncertainty, human-robot interaction, and the freezing robot problem. The survey provides researchers with a structured understanding of motion planning methods in dynamic environments.
Optimal Solutions for the Moving Target Vehicle Routing Problem via Branch-and-Price with Relaxed Continuity
Feb 28, 2026The Moving Target Vehicle Routing Problem (MT-VRP) seeks trajectories for several agents that intercept a set of moving targets, subject to speed, time window, and capacity constraints. We introduce an exact algorithm, Branch-and-Price with Relaxed Continuity (BPRC), for the MT-VRP. The main challenge in a branch-and-price approach for the MT-VRP is the pricing subproblem, which is complicated by moving targets and time-dependent travel costs between targets. Our key contribution is a new labeling algorithm that solves this subproblem by means of a novel dominance criterion tailored for problems with moving targets. Numerical results on instances with up to 25 targets show that our algorithm finds optimal solutions more than an order of magnitude faster than a baseline based on previous work, showing particular strength in scenarios with limited agent capacities.
Conflict-Based Search for Multi-Agent Path Finding with Elevators
Feb 24, 2026This paper investigates a problem called Multi-Agent Path Finding with Elevators (MAPF-E), which seeks conflict-free paths for multiple agents from their start to goal locations that may locate on different floors, and the agents can use elevators to travel between floors. The existence of elevators complicates the interaction among the agents and introduces new challenges to the planning. On the one hand, elevators can cause many conflicts among the agents due to its relatively long traversal time across floors, especially when many agents need to reach a different floor. On the other hand, the planner has to reason in a larger state space including the states of the elevators, besides the locations of the agents.
RPT*: Global Planning with Probabilistic Terminals for Target Search in Complex Environments
Jan 19, 2026Routing problems such as Hamiltonian Path Problem (HPP), seeks a path to visit all the vertices in a graph while minimizing the path cost. This paper studies a variant, HPP with Probabilistic Terminals (HPP-PT), where each vertex has a probability representing the likelihood that the robot's path terminates there, and the objective is to minimize the expected path cost. HPP-PT arises in target object search, where a mobile robot must visit all candidate locations to find an object, and prior knowledge of the object's location is expressed as vertex probabilities. While routing problems have been studied for decades, few of them consider uncertainty as required in this work. The challenge lies not only in optimally ordering the vertices, as in standard HPP, but also in handling history dependency: the expected path cost depends on the order in which vertices were previously visited. This makes many existing methods inefficient or inapplicable. To address the challenge, we propose a search-based approach RPT* with solution optimality guarantees, which leverages dynamic programming in a new state space to bypass the history dependency and novel heuristics to speed up the computation. Building on RPT*, we design a Hierarchical Autonomous Target Search (HATS) system that combines RPT* with either Bayesian filtering for lifelong target search with noisy sensors, or autonomous exploration to find targets in unknown environments. Experiments in both simulation and real robot show that our approach can naturally balance between exploitation and exploration, thereby finding targets more quickly on average than baseline methods.
Ergodic Trajectory Planning with Dynamic Sensor Footprints
Dec 09, 2025This paper addresses the problem of trajectory planning for information gathering with a dynamic and resolution-varying sensor footprint. Ergodic planning offers a principled framework that balances exploration (visiting all areas) and exploitation (focusing on high-information regions) by planning trajectories such that the time spent in a region is proportional to the amount of information in that region. Existing ergodic planning often oversimplifies the sensing model by assuming a point sensor or a footprint with constant shape and resolution. In practice, the sensor footprint can drastically change over time as the robot moves, such as aerial robots equipped with downward-facing cameras, whose field of view depends on the orientation and altitude. To overcome this limitation, we propose a new metric that accounts for dynamic sensor footprints, analyze the theoretic local optimality conditions, and propose numerical trajectory optimization algorithms. Experimental results show that the proposed approach can simultaneously optimize both the trajectories and sensor footprints, with up to an order of magnitude better ergodicity than conventional methods. We also deploy our approach in a multi-drone system to ergodically cover an object in 3D space.
Parallel, Asymptotically Optimal Algorithms for Moving Target Traveling Salesman Problems
Sep 10, 2025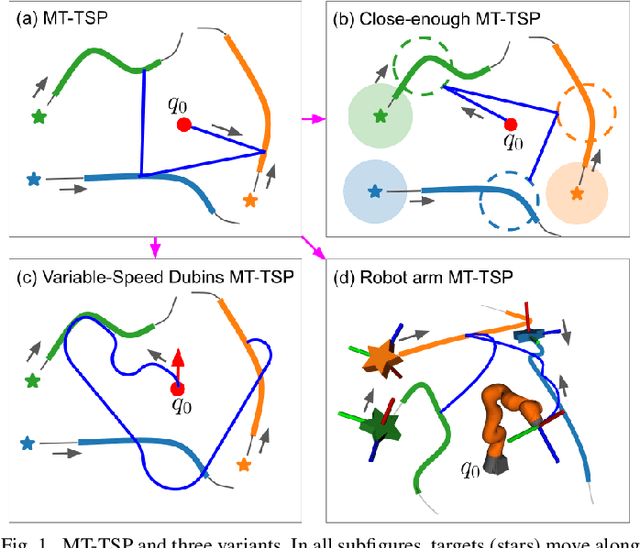
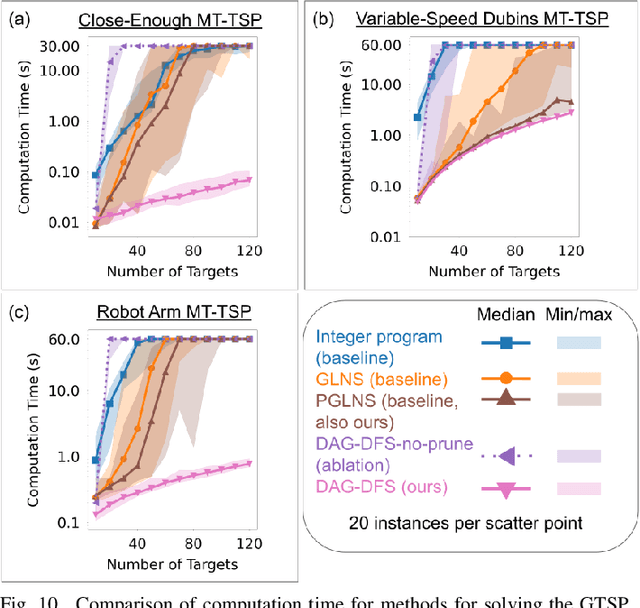
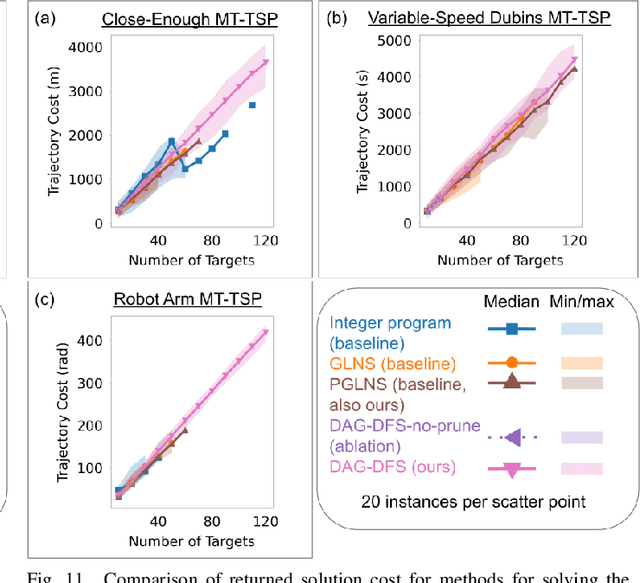
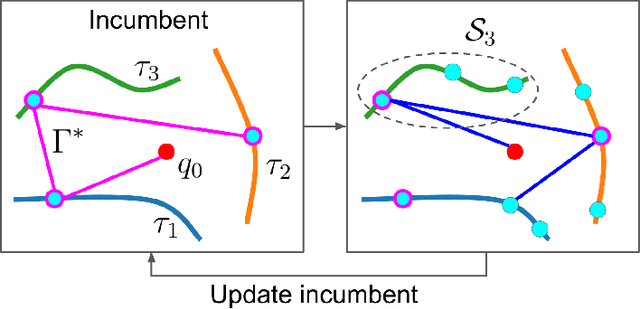
The Moving Target Traveling Salesman Problem (MT-TSP) seeks an agent trajectory that intercepts several moving targets, within a particular time window for each target. In the presence of generic nonlinear target trajectories or kinematic constraints on the agent, no prior algorithm guarantees convergence to an optimal MT-TSP solution. Therefore, we introduce the Iterated Random Generalized (IRG) TSP framework. The key idea behind IRG is to alternate between randomly sampling a set of agent configuration-time points, corresponding to interceptions of targets, and finding a sequence of interception points by solving a generalized TSP (GTSP). This alternation enables asymptotic convergence to the optimum. We introduce two parallel algorithms within the IRG framework. The first algorithm, IRG-PGLNS, solves GTSPs using PGLNS, our parallelized extension of the state-of-the-art solver GLNS. The second algorithm, Parallel Communicating GTSPs (PCG), solves GTSPs corresponding to several sets of points simultaneously. We present numerical results for three variants of the MT-TSP: one where intercepting a target only requires coming within a particular distance, another where the agent is a variable-speed Dubins car, and a third where the agent is a redundant robot arm. We show that IRG-PGLNS and PCG both converge faster than a baseline based on prior work.
A Complete and Bounded-Suboptimal Algorithm for a Moving Target Traveling Salesman Problem with Obstacles in 3D
Apr 20, 2025The moving target traveling salesman problem with obstacles (MT-TSP-O) seeks an obstacle-free trajectory for an agent that intercepts a given set of moving targets, each within specified time windows, and returns to the agent's starting position. Each target moves with a constant velocity within its time windows, and the agent has a speed limit no smaller than any target's speed. We present FMC*-TSP, the first complete and bounded-suboptimal algorithm for the MT-TSP-O, and results for an agent whose configuration space is $\mathbb{R}^3$. Our algorithm interleaves a high-level search and a low-level search, where the high-level search solves a generalized traveling salesman problem with time windows (GTSP-TW) to find a sequence of targets and corresponding time windows for the agent to visit. Given such a sequence, the low-level search then finds an associated agent trajectory. To solve the low-level planning problem, we develop a new algorithm called FMC*, which finds a shortest path on a graph of convex sets (GCS) via implicit graph search and pruning techniques specialized for problems with moving targets. We test FMC*-TSP on 280 problem instances with up to 40 targets and demonstrate its smaller median runtime than a baseline based on prior work.
A Mixed-Integer Conic Program for the Multi-Agent Moving-Target Traveling Salesman Problem
Jan 10, 2025The Moving-Target Traveling Salesman Problem (MT-TSP) aims to find a shortest path for an agent that starts at a stationary depot, visits a set of moving targets exactly once, each within one of their respective time windows, and then returns to the depot. In this paper, we introduce a new Mixed-Integer Conic Program (MICP) formulation that finds the optimum for the Multi-Agent Moving-Target Traveling Salesman Problem (MA-MT-TSP), a generalization of the MT-TSP involving multiple agents. We obtain our formulation by first restating the current state-of-the-art MICP formulation for MA-MT-TSP as a Mixed-Integer Nonlinear Nonconvex Program, and then reformulating it as a new MICP. We present computational results to demonstrate the performance of our approach. The results show that our formulation significantly outperforms the state-of-the-art, with up to a two-order-of-magnitude reduction in runtime, and up to over 90% tighter optimality gap.
Loosely Synchronized Rule-Based Planning for Multi-Agent Path Finding with Asynchronous Actions
Dec 16, 2024
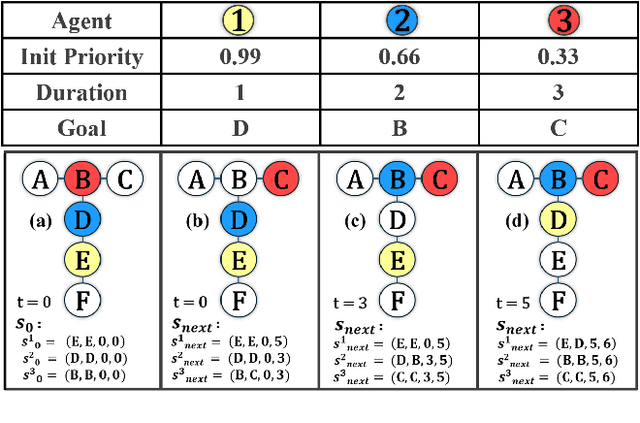
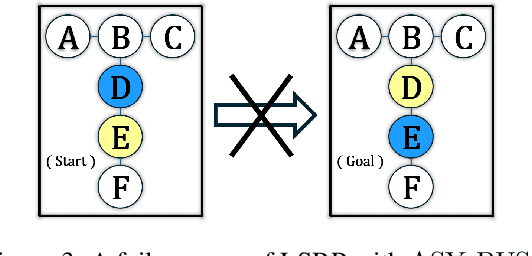
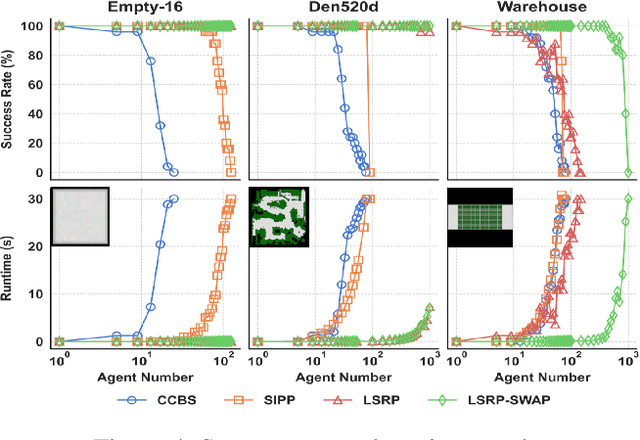
Multi-Agent Path Finding (MAPF) seeks collision-free paths for multiple agents from their respective starting locations to their respective goal locations while minimizing path costs. Although many MAPF algorithms were developed and can handle up to thousands of agents, they usually rely on the assumption that each action of the agent takes a time unit, and the actions of all agents are synchronized in a sense that the actions of agents start at the same discrete time step, which may limit their use in practice. Only a few algorithms were developed to address asynchronous actions, and they all lie on one end of the spectrum, focusing on finding optimal solutions with limited scalability. This paper develops new planners that lie on the other end of the spectrum, trading off solution quality for scalability, by finding an unbounded sub-optimal solution for many agents. Our method leverages both search methods (LSS) in handling asynchronous actions and rule-based planning methods (PIBT) for MAPF. We analyze the properties of our method and test it against several baselines with up to 1000 agents in various maps. Given a runtime limit, our method can handle an order of magnitude more agents than the baselines with about 25% longer makespan.
Search-Based Path Planning among Movable Obstacles
Oct 24, 2024



This paper investigates Path planning Among Movable Obstacles (PAMO), which seeks a minimum cost collision-free path among static obstacles from start to goal while allowing the robot to push away movable obstacles (i.e., objects) along its path when needed. To develop planners that are complete and optimal for PAMO, the planner has to search a giant state space involving both the location of the robot as well as the locations of the objects, which grows exponentially with respect to the number of objects. The main idea in this paper is that, only a small fraction of this giant state space needs to be explored during planning as guided by a heuristic, and most of the objects far away from the robot are intact, which thus leads to runtime efficient algorithms. Based on this idea, this paper introduces two PAMO formulations, i.e., bi-objective and resource constrained problems in an occupancy grid, and develops PAMO*, a search method with completeness and solution optimality guarantees, to solve the two problems. We then further extend PAMO* to hybrid-state PAMO* to plan in continuous spaces with high-fidelity interaction between the robot and the objects. Our results show that, PAMO* can often find optimal solutions within a second in cluttered environments with up to 400 objects.