 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Feature Highlighting for Human-AI Decision-Making
Apr 24, 2026Human decision-makers often face choices about complex cases with many potentially relevant features, but limited bandwidth to inspect and integrate all available information. In such settings, we study algorithms that highlight a small subset of case-specific features for human consideration, rather than producing a single prediction or recommendation. We model highlighting as a constrained information policy that selects a small number of features to reveal. A central issue is how humans interpret the algorithm's choice of features: a sophisticated agent correctly conditions on the selection rule, while a naive agent updates only on revealed feature values and treats the selection event as exogenous. We show that optimizing highlighting for sophisticated agents can be computationally intractable, even in simple discrete and binary settings, whereas optimizing for naive agents is tractable as long as the maximal bandwidth is fixed. We also show that a highlighting policy that is optimal for sophisticated agents can perform arbitrarily poorly when deployed to naive agents, motivating robust, implementable alternatives. We illustrate our framework in a calibrated empirical exercise based on the American Housing Survey. Overall, our results establish the value of highlighting a context-specific set of features rather than a fixed one as a practically appealing and computationally feasible tool for achieving human-algorithm complementarity.
FAS-aided Robust Anti-Jamming Communications: Continuous and Discrete Positioning Designs
Apr 13, 2026This paper investigates the joint optimization of beamforming and antenna positions in fluid antenna system (FAS)-aided anti-jamming communications. We consider a multi-user multiple-input multiple-output downlink scenario where multiple malicious jammers exist and the jammer channel state information is imperfect. The goal is to maximize the worst-case sum-rate under quality-of-service and transmit power constraints. To achieve this, we develop two distinct optimization frameworks for continuous and discrete antenna position designs, respectively. For continuous design, we propose an alternating optimization (AO) framework that integrates successive convex approximation and majorization minimization (MM) to handle the highly non-convex problem. For discrete design, based on the minimum mean squared error criterion and MM, we reformulate the problem as a sparse recovery task and propose a low-complexity block coordinate descent and simultaneous orthogonal matching pursuit, which enables joint design rather than AO. Through systematic comparison, we uncover a practical phenomenon: the discrete joint design yields superior sum-rate performance compared to the AO-based continuous counterpart under identical conditions. This superiority stems from the sparse recovery formulation which effectively circumvents the severe local optima. Our findings challenge the conventional view that continuous optimization is inherently superior, and reveal that discretization combined with sparse recovery can offer a more effective paradigm for exploiting spatial degrees-of-freedom in FAS-aided anti-jamming communications.
Robust Hybrid Precoding for Millimeter Wave MU-MISO System Via Meta-Learning
Nov 24, 2024Thanks to the low cost and power consumption, hybrid analog-digital architectures are considered as a promising energy-efficient solution for massive multiple-input multiple-output (MIMO) systems. The key idea is to connect one RF chain to multiple antennas through low-cost phase shifters. However, due to the non-convex objective function and constraints, we propose a gradient-guided meta-learning (GGML) based alternating optimization framework to solve this challenging problem. The GGML based hybrid precoding framework is \textit{free-of-training} and \textit{plug-and-play}. Specifically, GGML feeds the raw gradient information into a neural network, leveraging gradient descent to alternately optimize sub-problems from a local perspective, while a lightweight neural network embedded within the meta-learning framework is updated from a global perspective. We also extend the proposed framework to include precoding with imperfect channel state information. Simulation results demonstrate that GGML can significantly enhance spectral efficiency, and speed up the convergence by 8 times faster compared to traditional approaches. Moreover, GGML could even outperform fully digital weighted minimum mean square error (WMMSE) precoding with the same number of antennas.
Meta-Learning for Hybrid Precoding in Millimeter Wave MIMO System
Oct 12, 2024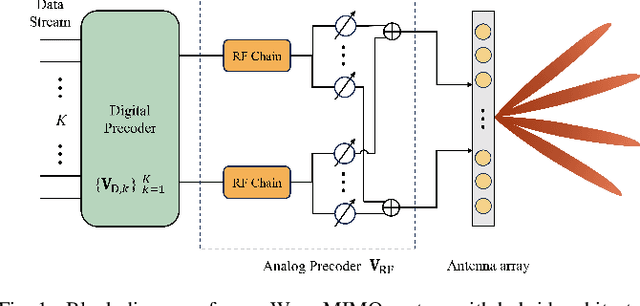
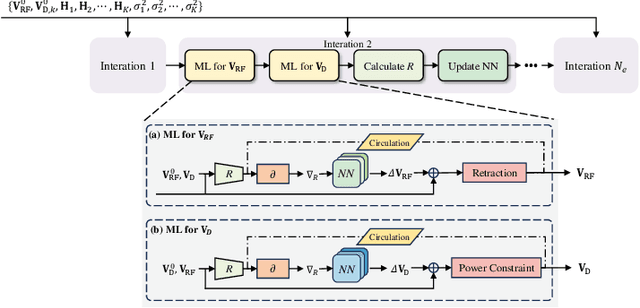
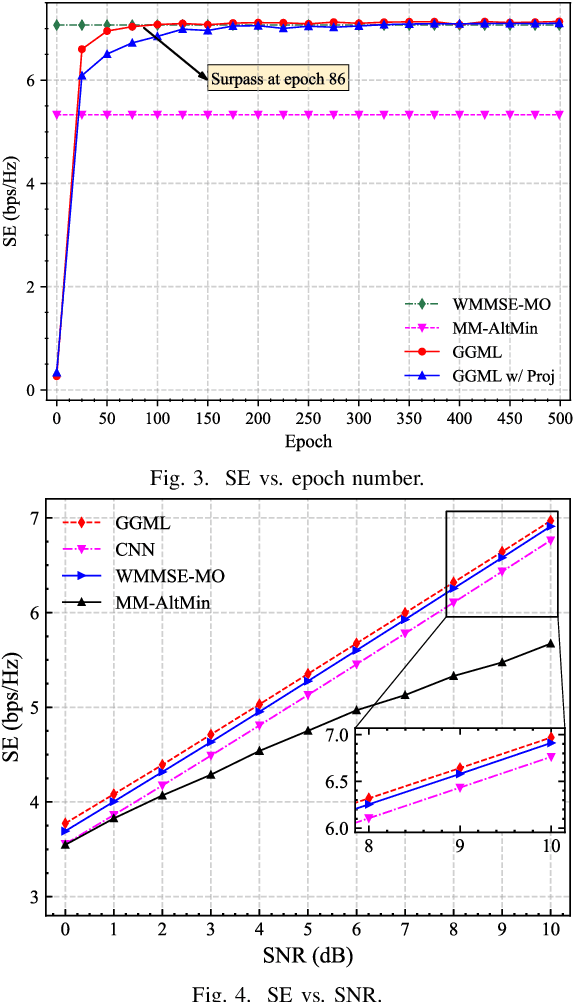
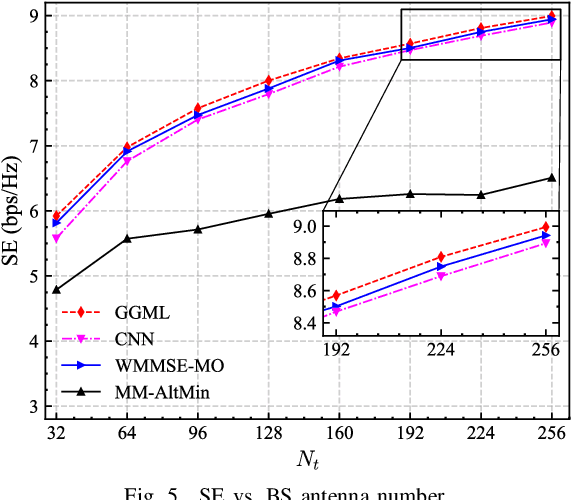
The hybrid analog/digital architecture that connects a limited number of RF chains to multiple antennas through phase shifters could effectively address the energy consumption issues in massive multiple-input multiple-output (MIMO) systems. However, the main challenges in hybrid precoding lie in the coupling between analog and digital precoders and the constant modulus constraint. Generally, traditional optimization algorithms for this problem typically suffer from high computational complexity or suboptimal performance, while deep learning based solutions exhibit poor scalability and robustness. This paper proposes a plug and play, free of pre-training solution that leverages gradient guided meta learning (GGML) framework to maximize the spectral efficiency of MIMO systems through hybrid precoding. Specifically, GGML utilizes gradient information as network input to facilitate the sharing of gradient information flow. We retain the iterative process of traditional algorithms and leverage meta learning to alternately optimize the precoder. Simulation results show that this method outperforms existing methods, demonstrates robustness to variations in system parameters, and can even exceed the performance of fully digital weighted minimum mean square error (WMMSE) precoding with the same number of antennas.
Range-based Multi-Robot Integrity Monitoring Against Cyberattacks and Faults: An Anchor-Free Approach
Aug 20, 2024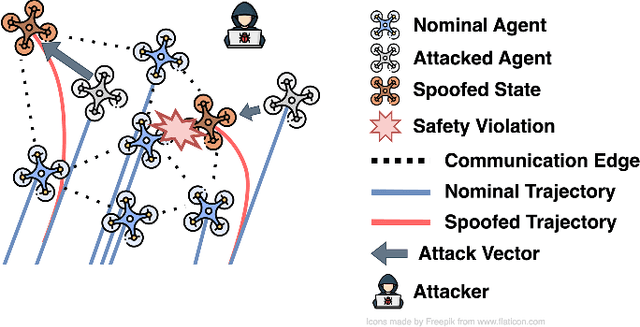
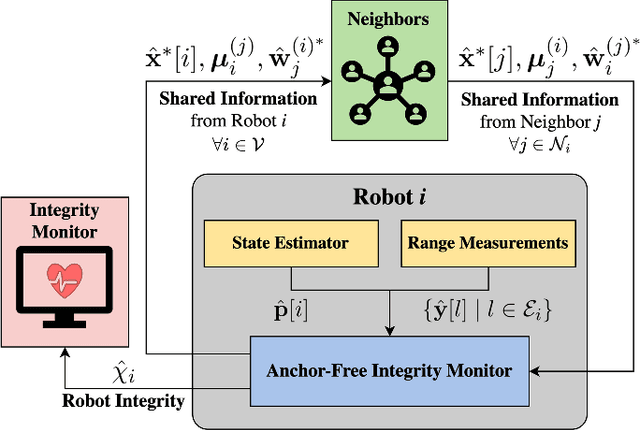
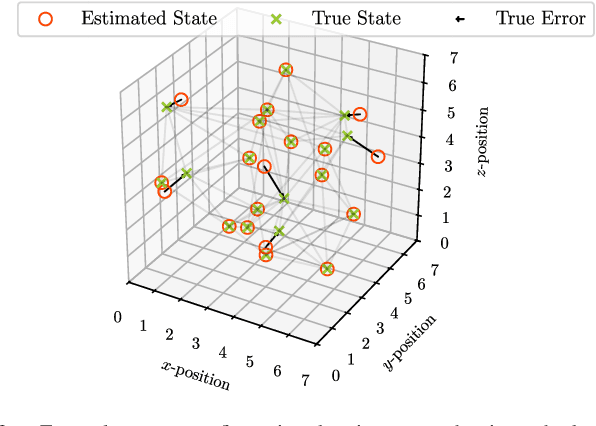
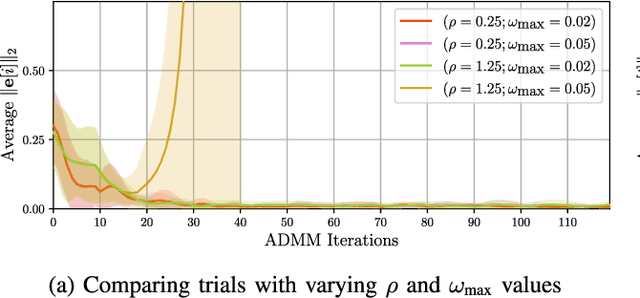
Coordination of multi-robot systems (MRSs) relies on efficient sensing and reliable communication among the robots. However, the sensors and communication channels of these robots are often vulnerable to cyberattacks and faults, which can disrupt their individual behavior and the overall objective of the MRS. In this work, we present a multi-robot integrity monitoring framework that utilizes inter-robot range measurements to (i) detect the presence of cyberattacks or faults affecting the MRS, (ii) identify the affected robot(s), and (iii) reconstruct the resulting localization error of these robot(s). The proposed iterative algorithm leverages sequential convex programming and alternating direction of multipliers method to enable real-time and distributed implementation. Our approach is validated using numerical simulations and demonstrated using PX4-SiTL in Gazebo on an MRS, where certain agents deviate from their desired position due to a GNSS spoofing attack. Furthermore, we demonstrate the scalability and interoperability of our algorithm through mixed-reality experiments by forming a heterogeneous MRS comprising real Crazyflie UAVs and virtual PX4-SiTL UAVs working in tandem.
Imperative Learning: A Self-supervised Neural-Symbolic Learning Framework for Robot Autonomy
Jun 23, 2024



Data-driven methods such as reinforcement and imitation learning have achieved remarkable success in robot autonomy. However, their data-centric nature still hinders them from generalizing well to ever-changing environments. Moreover, collecting large datasets for robotic tasks is often impractical and expensive. To overcome these challenges, we introduce a new self-supervised neural-symbolic (NeSy) computational framework, imperative learning (IL), for robot autonomy, leveraging the generalization abilities of symbolic reasoning. The framework of IL consists of three primary components: a neural module, a reasoning engine, and a memory system. We formulate IL as a special bilevel optimization (BLO), which enables reciprocal learning over the three modules. This overcomes the label-intensive obstacles associated with data-driven approaches and takes advantage of symbolic reasoning concerning logical reasoning, physical principles, geometric analysis, etc. We discuss several optimization techniques for IL and verify their effectiveness in five distinct robot autonomy tasks including path planning, rule induction, optimal control, visual odometry, and multi-robot routing. Through various experiments, we show that IL can significantly enhance robot autonomy capabilities and we anticipate that it will catalyze further research across diverse domains.
iMTSP: Solving Min-Max Multiple Traveling Salesman Problem with Imperative Learning
May 01, 2024



This paper considers a Min-Max Multiple Traveling Salesman Problem (MTSP), where the goal is to find a set of tours, one for each agent, to collectively visit all the cities while minimizing the length of the longest tour. Though MTSP has been widely studied, obtaining near-optimal solutions for large-scale problems is still challenging due to its NP-hardness. Recent efforts in data-driven methods face challenges of the need for hard-to-obtain supervision and issues with high variance in gradient estimations, leading to slow convergence and highly suboptimal solutions. We address these issues by reformulating MTSP as a bilevel optimization problem, using the concept of imperative learning (IL). This involves introducing an allocation network that decomposes the MTSP into multiple single-agent traveling salesman problems (TSPs). The longest tour from these TSP solutions is then used to self-supervise the allocation network, resulting in a new self-supervised, bilevel, end-to-end learning framework, which we refer to as imperative MTSP (iMTSP). Additionally, to tackle the high-variance gradient issues during the optimization, we introduce a control variate-based gradient estimation algorithm. Our experiments showed that these innovative designs enable our gradient estimator to converge 20% faster than the advanced reinforcement learning baseline and find up to 80% shorter tour length compared with Google OR-Tools MTSP solver, especially in large-scale problems (e.g. 1000 cities and 15 agents).
Interrelate Training and Searching: A Unified Online Clustering Framework for Speaker Diarization
Jun 28, 2022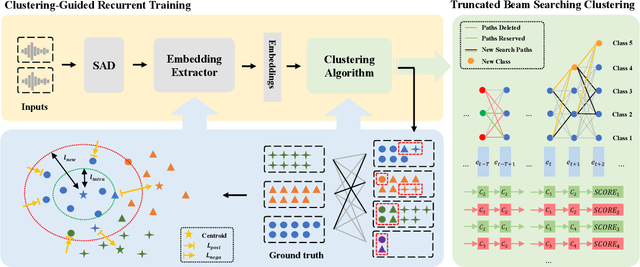
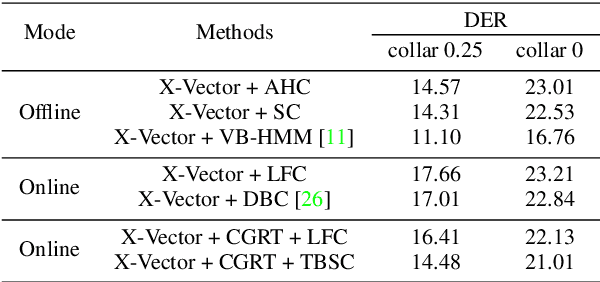
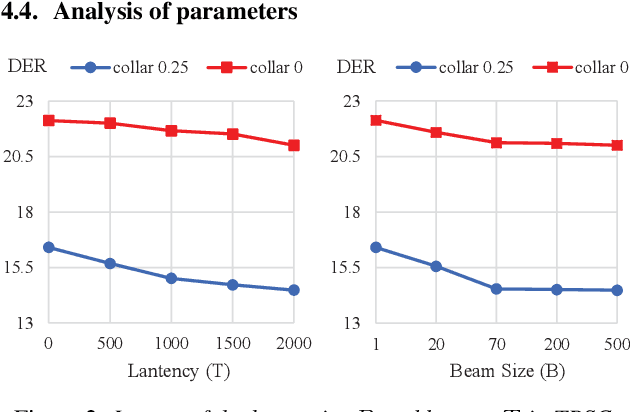
For online speaker diarization, samples arrive incrementally, and the overall distribution of the samples is invisible. Moreover, in most existing clustering-based methods, the training objective of the embedding extractor is not designed specially for clustering. To improve online speaker diarization performance, we propose a unified online clustering framework, which provides an interactive manner between embedding extractors and clustering algorithms. Specifically, the framework consists of two highly coupled parts: clustering-guided recurrent training (CGRT) and truncated beam searching clustering (TBSC). The CGRT introduces the clustering algorithm into the training process of embedding extractors, which could provide not only cluster-aware information for the embedding extractor, but also crucial parameters for the clustering process afterward. And with these parameters, which contain preliminary information of the metric space, the TBSC penalizes the probability score of each cluster, in order to output more accurate clustering results in online fashion with low latency. With the above innovations, our proposed online clustering system achieves 14.48\% DER with collar 0.25 at 2.5s latency on the AISHELL-4, while the DER of the offline agglomerative hierarchical clustering is 14.57\%.
Data Augmentation based Consistency Contrastive Pre-training for Automatic Speech Recognition
Dec 23, 2021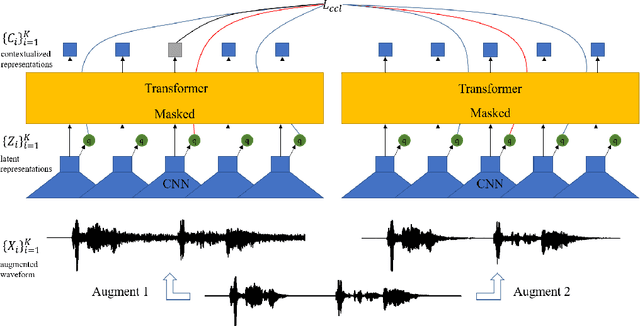
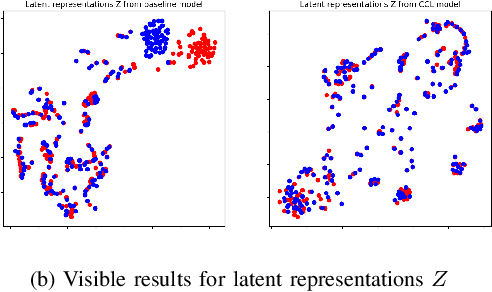
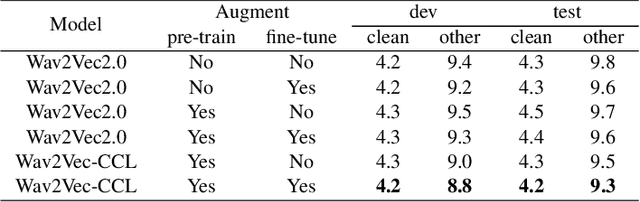
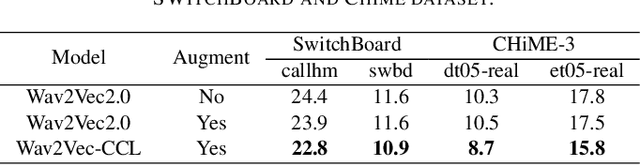
Self-supervised acoustic pre-training has achieved amazing results on the automatic speech recognition (ASR) task. Most of the successful acoustic pre-training methods use contrastive learning to learn the acoustic representations by distinguish the representations from different time steps, ignoring the speaker and environment robustness. As a result, the pre-trained model could show poor performance when meeting out-of-domain data during fine-tuning. In this letter, we design a novel consistency contrastive learning (CCL) method by utilizing data augmentation for acoustic pre-training. Different kinds of augmentation are applied on the original audios and then the augmented audios are fed into an encoder. The encoder should not only contrast the representations within one audio but also maximize the measurement of the representations across different augmented audios. By this way, the pre-trained model can learn a text-related representation method which is more robust with the change of the speaker or the environment.Experiments show that by applying the CCL method on the Wav2Vec2.0, better results can be realized both on the in-domain data and the out-of-domain data. Especially for noisy out-of-domain data, more than 15% relative improvement can be obtained.
Communication Model-Task Pairing in Artificial Swarm Design
Jan 22, 2018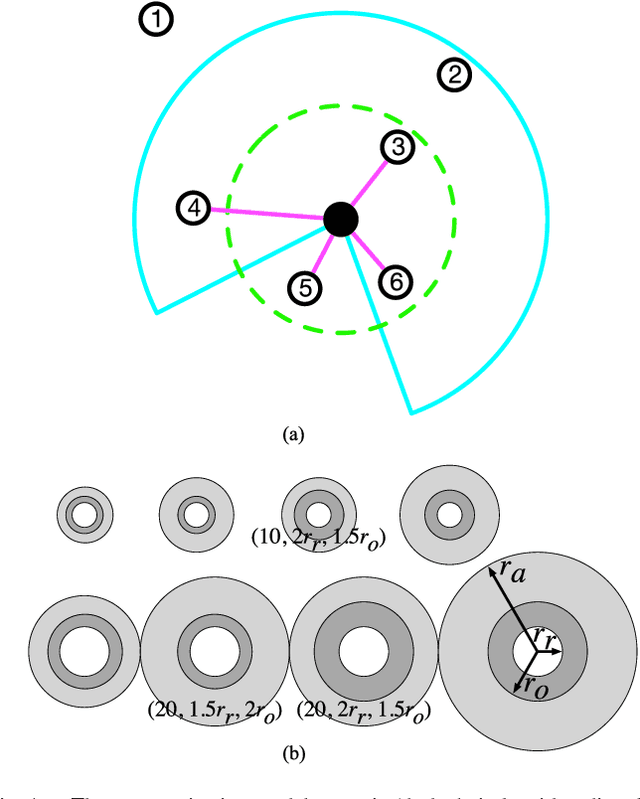
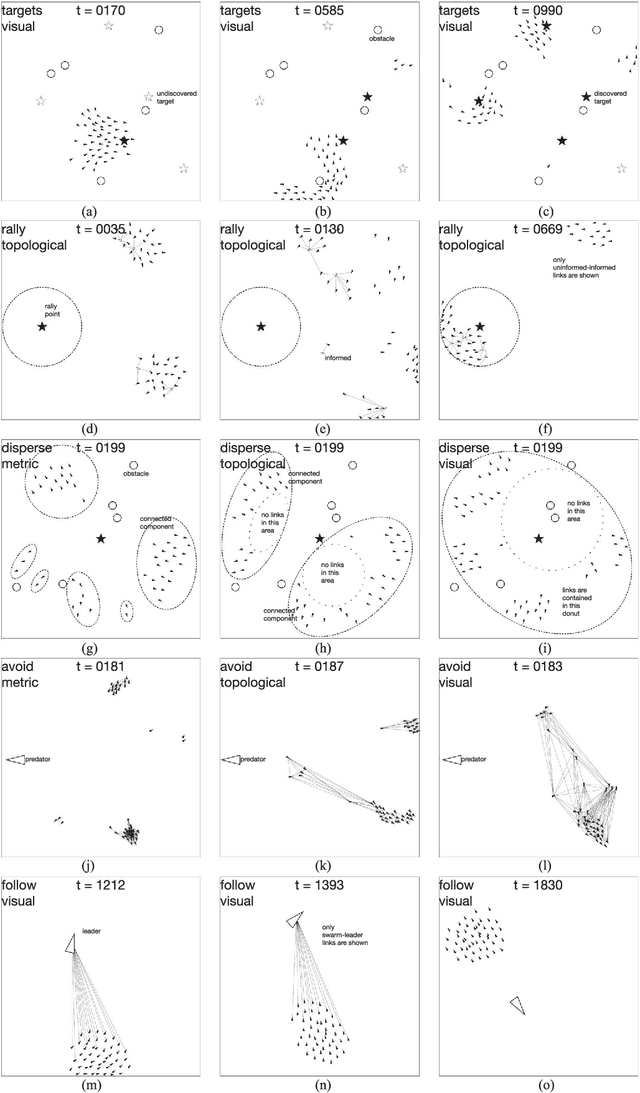
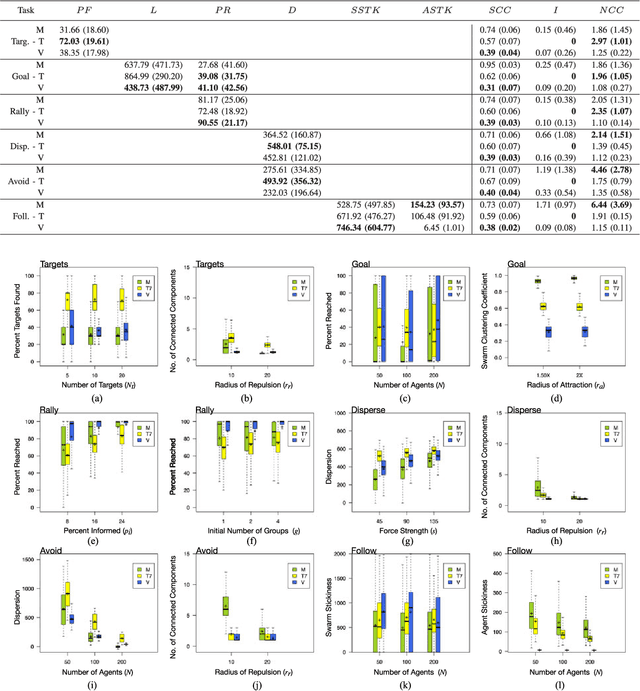
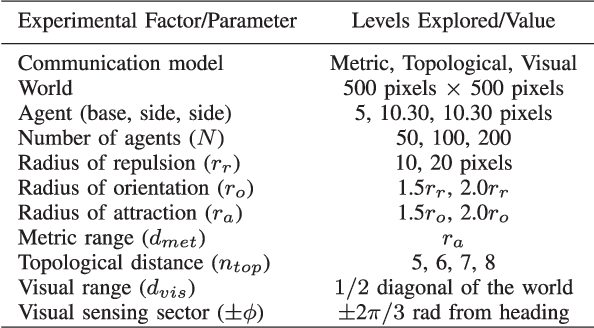
Unraveling the nature of the communication model that governs which two individuals in a swarm interact with each other is an important line of inquiry in the collective behavior sciences. A number of models have been proposed in the biological swarm literature, with the leading models being the metric, topological, and visual models. The hypothesis evaluated in this manuscript is whether the choice of a communication model impacts the performance of a tasked artificial swarm. The biological models are used to design coordination algorithms for a simulated swarm, which are evaluated over a range of six swarm robotics tasks. Each task has an associated set of performance metrics that are used to evaluate how the communication models fare against each other. The general findings demonstrate that the communication model significantly affects the swarm's performance for individual tasks, and this result implies that the communication model-task pairing is an important consideration when designing artificial swarms. Further analysis of each tasks' performance metrics reveal instances in which pairwise considerations of model and one of the various experimental factors becomes relevant. The reported research demonstrates that the artificial swarm's task performance can be increased through the careful selection of a communications model.