 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Warmup: Complexity-Aware Curricula for Efficient Diffusion Training
Apr 08, 2026A key inefficiency in diffusion training occurs when a randomly initialized network, lacking visual priors, encounters gradients from the full complexity spectrum--most of which it lacks the capacity to resolve. We propose Data Warmup, a curriculum strategy that schedules training images from simple to complex without modifying the model or loss. Each image is scored offline by a semantic-aware complexity metric combining foreground dominance (how much of the image salient objects occupy) and foreground typicality (how closely the salient content matches learned visual prototypes). A temperature-controlled sampler then prioritizes low-complexity images early and anneals toward uniform sampling. On ImageNet 256x256 with SiT backbones (S/2 to XL/2), Data Warmup improves IS by up to 6.11 and FID by up to 3.41, reaching baseline quality tens of thousands of iterations earlier. Reversing the curriculum (exposing hard images first) degrades performance below the uniform baseline, confirming that the simple-to-complex ordering itself drives the gains. The method combines with orthogonal accelerators such as REPA and requires only ~10 minutes of one-time preprocessing with zero per-iteration overhead.
Bundle Adjustment in the Eager Mode
Sep 18, 2024



Bundle adjustment (BA) is a critical technique in various robotic applications, such as simultaneous localization and mapping (SLAM), augmented reality (AR), and photogrammetry. BA optimizes parameters such as camera poses and 3D landmarks to align them with observations. With the growing importance of deep learning in perception systems, there is an increasing need to integrate BA with deep learning frameworks for enhanced reliability and performance. However, widely-used C++-based BA frameworks, such as GTSAM, g$^2$o, and Ceres, lack native integration with modern deep learning libraries like PyTorch. This limitation affects their flexibility, adaptability, ease of debugging, and overall implementation efficiency. To address this gap, we introduce an eager-mode BA framework seamlessly integrated with PyPose, providing PyTorch-compatible interfaces with high efficiency. Our approach includes GPU-accelerated, differentiable, and sparse operations designed for 2nd-order optimization, Lie group and Lie algebra operations, and linear solvers. Our eager-mode BA on GPU demonstrates substantial runtime efficiency, achieving an average speedup of 18.5$\times$, 22$\times$, and 23$\times$ compared to GTSAM, g$^2$o, and Ceres, respectively.
Imperative Learning: A Self-supervised Neural-Symbolic Learning Framework for Robot Autonomy
Jun 23, 2024



Data-driven methods such as reinforcement and imitation learning have achieved remarkable success in robot autonomy. However, their data-centric nature still hinders them from generalizing well to ever-changing environments. Moreover, collecting large datasets for robotic tasks is often impractical and expensive. To overcome these challenges, we introduce a new self-supervised neural-symbolic (NeSy) computational framework, imperative learning (IL), for robot autonomy, leveraging the generalization abilities of symbolic reasoning. The framework of IL consists of three primary components: a neural module, a reasoning engine, and a memory system. We formulate IL as a special bilevel optimization (BLO), which enables reciprocal learning over the three modules. This overcomes the label-intensive obstacles associated with data-driven approaches and takes advantage of symbolic reasoning concerning logical reasoning, physical principles, geometric analysis, etc. We discuss several optimization techniques for IL and verify their effectiveness in five distinct robot autonomy tasks including path planning, rule induction, optimal control, visual odometry, and multi-robot routing. Through various experiments, we show that IL can significantly enhance robot autonomy capabilities and we anticipate that it will catalyze further research across diverse domains.
iMatching: Imperative Correspondence Learning
Dec 04, 2023Learning feature correspondence is a foundational task in computer vision, holding immense importance for downstream applications such as visual odometry and 3D reconstruction. Despite recent progress in data-driven models, feature correspondence learning is still limited by the lack of accurate per-pixel correspondence labels. To overcome this difficulty, we introduce a new self-supervised scheme, imperative learning (IL), for training feature correspondence. It enables correspondence learning on arbitrary uninterrupted videos without any camera pose or depth labels, heralding a new era for self-supervised correspondence learning. Specifically, we formulated the problem of correspondence learning as a bilevel optimization, which takes the reprojection error from bundle adjustment as a supervisory signal for the model. To avoid large memory and computation overhead, we leverage the stationary point to effectively back-propagate the implicit gradients through bundle adjustment. Through extensive experiments, we demonstrate superior performance on tasks including feature matching and pose estimation, in which we obtained an average of 30% accuracy gain over the state-of-the-art matching models.
PyPose v0.6: The Imperative Programming Interface for Robotics
Sep 22, 2023
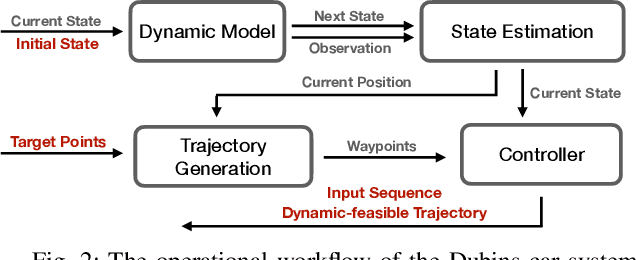
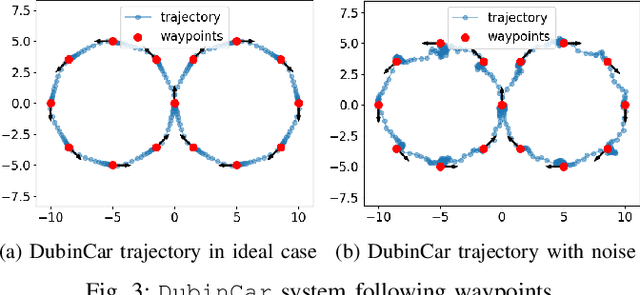
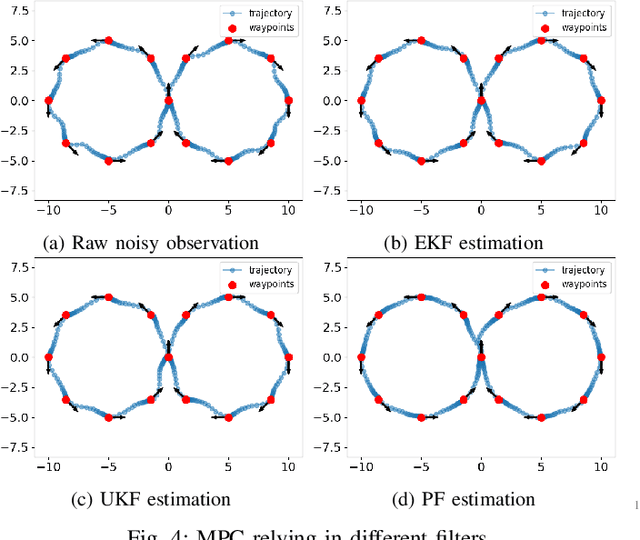
PyPose is an open-source library for robot learning. It combines a learning-based approach with physics-based optimization, which enables seamless end-to-end robot learning. It has been used in many tasks due to its meticulously designed application programming interface (API) and efficient implementation. From its initial launch in early 2022, PyPose has experienced significant enhancements, incorporating a wide variety of new features into its platform. To satisfy the growing demand for understanding and utilizing the library and reduce the learning curve of new users, we present the fundamental design principle of the imperative programming interface, and showcase the flexible usage of diverse functionalities and modules using an extremely simple Dubins car example. We also demonstrate that the PyPose can be easily used to navigate a real quadruped robot with a few lines of code.
Robust Online Video Instance Segmentation with Track Queries
Nov 16, 2022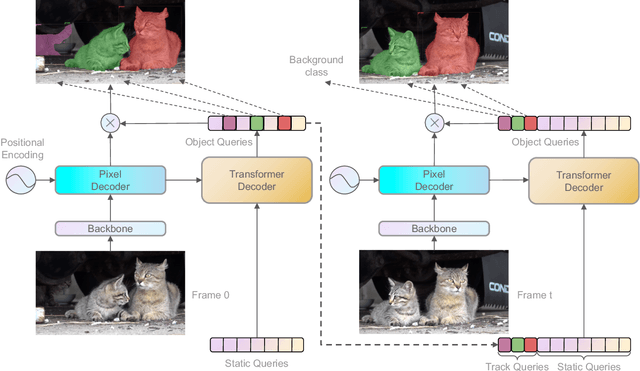
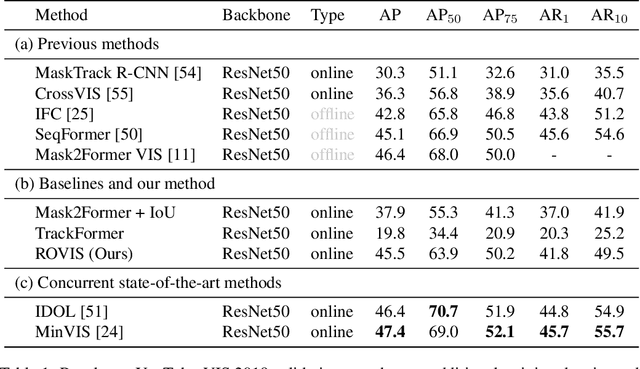

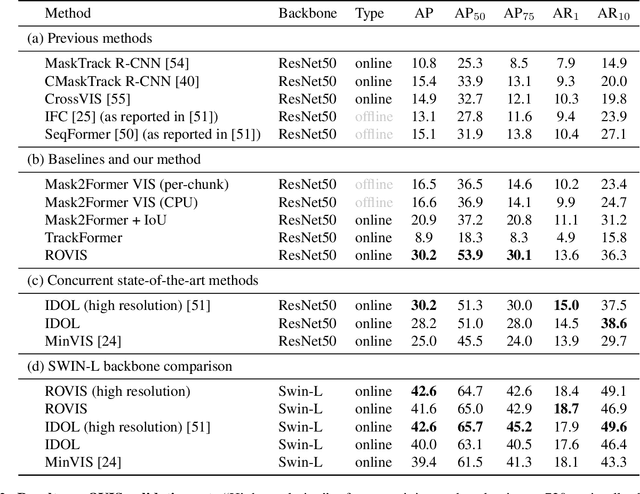
Recently, transformer-based methods have achieved impressive results on Video Instance Segmentation (VIS). However, most of these top-performing methods run in an offline manner by processing the entire video clip at once to predict instance mask volumes. This makes them incapable of handling the long videos that appear in challenging new video instance segmentation datasets like UVO and OVIS. We propose a fully online transformer-based video instance segmentation model that performs comparably to top offline methods on the YouTube-VIS 2019 benchmark and considerably outperforms them on UVO and OVIS. This method, called Robust Online Video Segmentation (ROVIS), augments the Mask2Former image instance segmentation model with track queries, a lightweight mechanism for carrying track information from frame to frame, originally introduced by the TrackFormer method for multi-object tracking. We show that, when combined with a strong enough image segmentation architecture, track queries can exhibit impressive accuracy while not being constrained to short videos.
Transfer of Representations to Video Label Propagation: Implementation Factors Matter
Mar 10, 2022
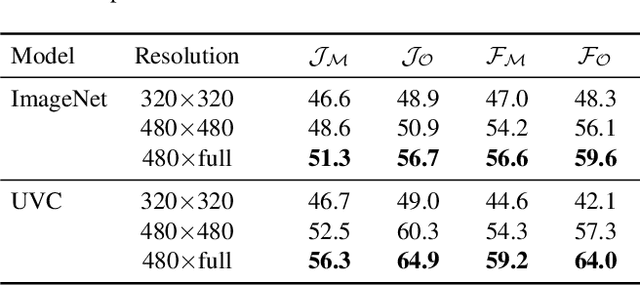
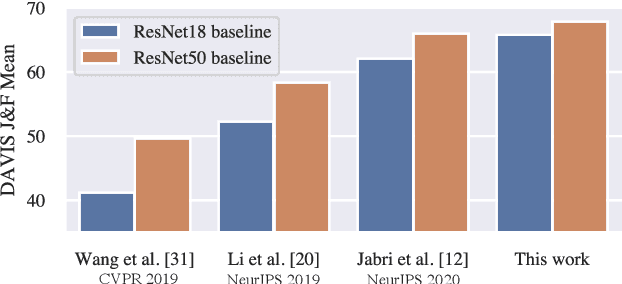
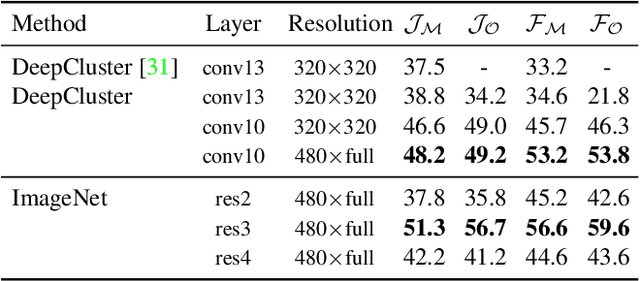
This work studies feature representations for dense label propagation in video, with a focus on recently proposed methods that learn video correspondence using self-supervised signals such as colorization or temporal cycle consistency. In the literature, these methods have been evaluated with an array of inconsistent settings, making it difficult to discern trends or compare performance fairly. Starting with a unified formulation of the label propagation algorithm that encompasses most existing variations, we systematically study the impact of important implementation factors in feature extraction and label propagation. Along the way, we report the accuracies of properly tuned supervised and unsupervised still image baselines, which are higher than those found in previous works. We also demonstrate that augmenting video-based correspondence cues with still-image-based ones can further improve performance. We then attempt a fair comparison of recent video-based methods on the DAVIS benchmark, showing convergence of best methods to performance levels near our strong ImageNet baseline, despite the usage of a variety of specialized video-based losses and training particulars. Additional comparisons on JHMDB and VIP datasets confirm the similar performance of current methods. We hope that this study will help to improve evaluation practices and better inform future research directions in temporal correspondence.