 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRayFronts: Open-Set Semantic Ray Frontiers for Online Scene Understanding and Exploration
Apr 09, 2025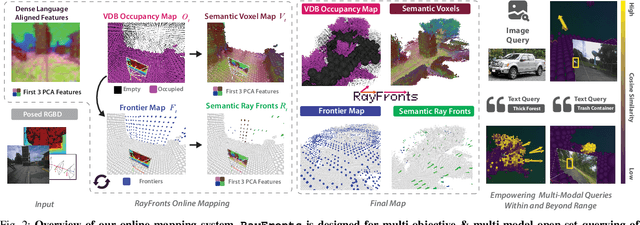
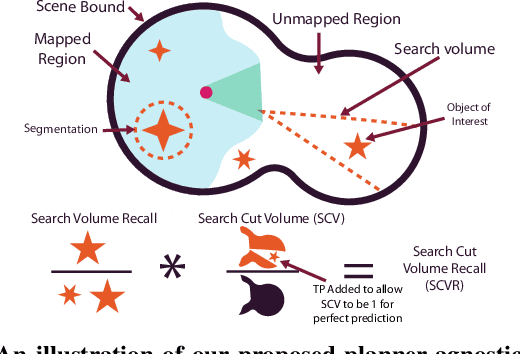
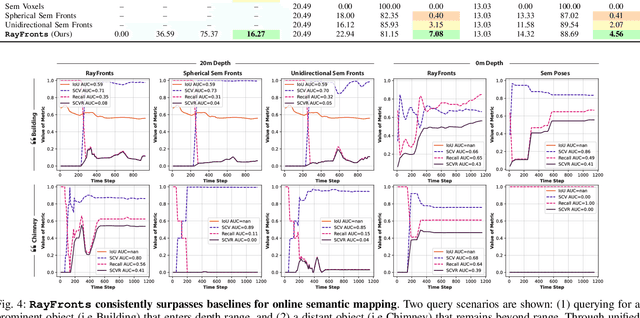
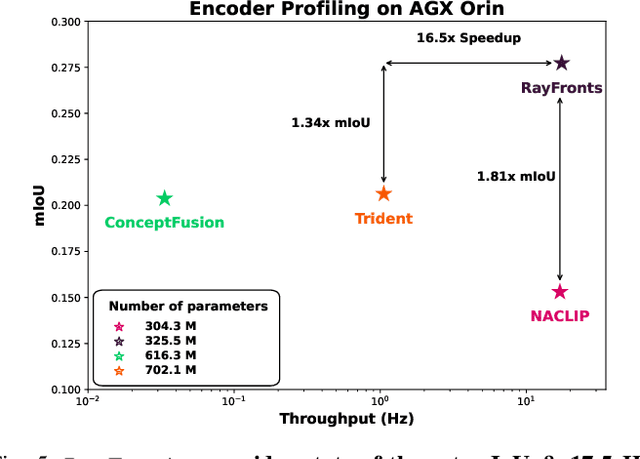
Open-set semantic mapping is crucial for open-world robots. Current mapping approaches either are limited by the depth range or only map beyond-range entities in constrained settings, where overall they fail to combine within-range and beyond-range observations. Furthermore, these methods make a trade-off between fine-grained semantics and efficiency. We introduce RayFronts, a unified representation that enables both dense and beyond-range efficient semantic mapping. RayFronts encodes task-agnostic open-set semantics to both in-range voxels and beyond-range rays encoded at map boundaries, empowering the robot to reduce search volumes significantly and make informed decisions both within & beyond sensory range, while running at 8.84 Hz on an Orin AGX. Benchmarking the within-range semantics shows that RayFronts's fine-grained image encoding provides 1.34x zero-shot 3D semantic segmentation performance while improving throughput by 16.5x. Traditionally, online mapping performance is entangled with other system components, complicating evaluation. We propose a planner-agnostic evaluation framework that captures the utility for online beyond-range search and exploration, and show RayFronts reduces search volume 2.2x more efficiently than the closest online baselines.
C-SAW: Self-Supervised Prompt Learning for Image Generalization in Remote Sensing
Nov 27, 2023

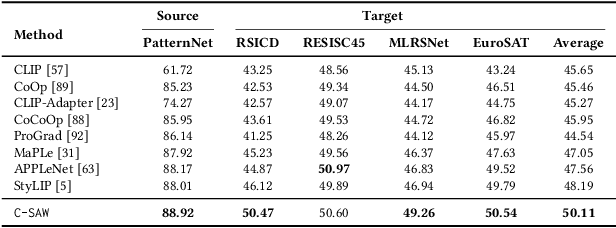

We focus on domain and class generalization problems in analyzing optical remote sensing images, using the large-scale pre-trained vision-language model (VLM), CLIP. While contrastively trained VLMs show impressive zero-shot generalization performance, their effectiveness is limited when dealing with diverse domains during training and testing. Existing prompt learning techniques overlook the importance of incorporating domain and content information into the prompts, which results in a drop in performance while dealing with such multi-domain data. To address these challenges, we propose a solution that ensures domain-invariant prompt learning while enhancing the expressiveness of visual features. We observe that CLIP's vision encoder struggles to identify contextual image information, particularly when image patches are jumbled up. This issue is especially severe in optical remote sensing images, where land-cover classes exhibit well-defined contextual appearances. To this end, we introduce C-SAW, a method that complements CLIP with a self-supervised loss in the visual space and a novel prompt learning technique that emphasizes both visual domain and content-specific features. We keep the CLIP backbone frozen and introduce a small set of projectors for both the CLIP encoders to train C-SAW contrastively. Experimental results demonstrate the superiority of C-SAW across multiple remote sensing benchmarks and different generalization tasks.
Learning Class and Domain Augmentations for Single-Source Open-Domain Generalization
Nov 05, 2023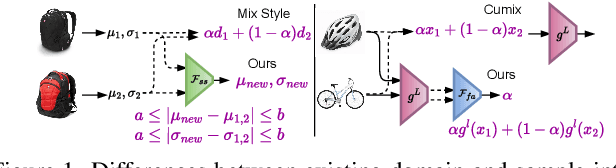
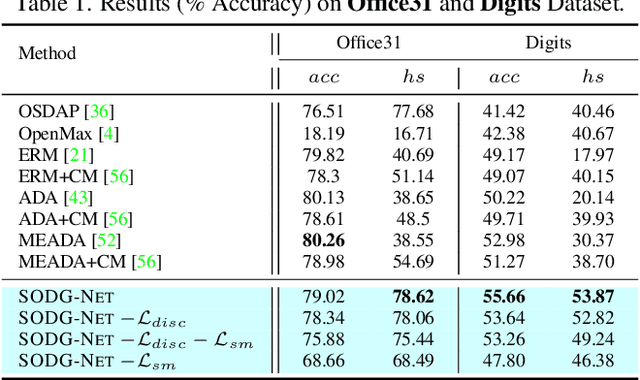
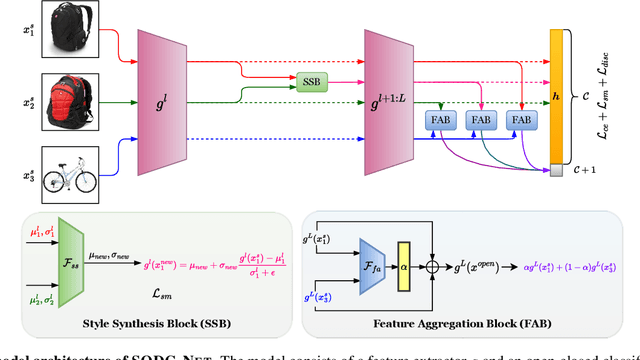
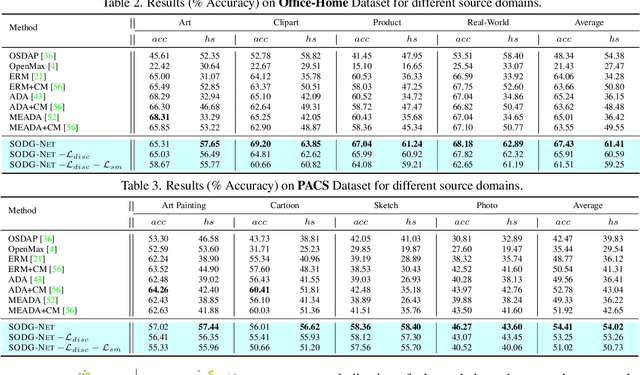
Single-source open-domain generalization (SS-ODG) addresses the challenge of labeled source domains with supervision during training and unlabeled novel target domains during testing. The target domain includes both known classes from the source domain and samples from previously unseen classes. Existing techniques for SS-ODG primarily focus on calibrating source-domain classifiers to identify open samples in the target domain. However, these methods struggle with visually fine-grained open-closed data, often misclassifying open samples as closed-set classes. Moreover, relying solely on a single source domain restricts the model's ability to generalize. To overcome these limitations, we propose a novel framework called SODG-Net that simultaneously synthesizes novel domains and generates pseudo-open samples using a learning-based objective, in contrast to the ad-hoc mixing strategies commonly found in the literature. Our approach enhances generalization by diversifying the styles of known class samples using a novel metric criterion and generates diverse pseudo-open samples to train a unified and confident multi-class classifier capable of handling both open and closed-set data. Extensive experimental evaluations conducted on multiple benchmarks consistently demonstrate the superior performance of SODG-Net compared to the literature.
ClamNet: Using contrastive learning with variable depth Unets for medical image segmentation
Jun 10, 2022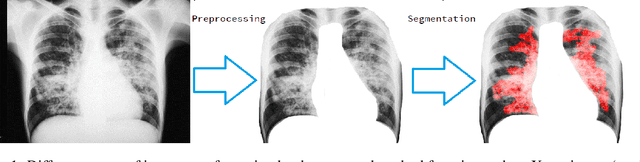
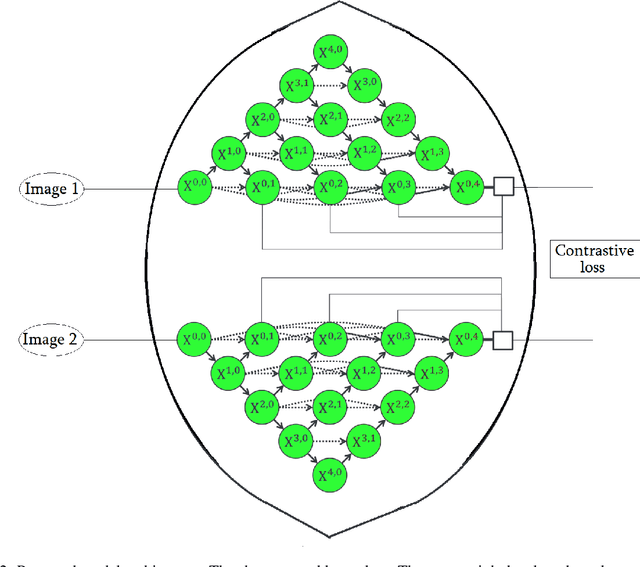
Unets have become the standard method for semantic segmentation of medical images, along with fully convolutional networks (FCN). Unet++ was introduced as a variant of Unet, in order to solve some of the problems facing Unet and FCNs. Unet++ provided networks with an ensemble of variable depth Unets, hence eliminating the need for professionals estimating the best suitable depth for a task. While Unet and all its variants, including Unet++ aimed at providing networks that were able to train well without requiring large quantities of annotated data, none of them attempted to eliminate the need for pixel-wise annotated data altogether. Obtaining such data for each disease to be diagnosed comes at a high cost. Hence such data is scarce. In this paper we use contrastive learning to train Unet++ for semantic segmentation of medical images using medical images from various sources including magnetic resonance imaging (MRI) and computed tomography (CT), without the need for pixel-wise annotations. Here we describe the architecture of the proposed model and the training method used. This is still a work in progress and so we abstain from including results in this paper. The results and the trained model would be made available upon publication or in subsequent versions of this paper on arxiv.