 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRayFronts: Open-Set Semantic Ray Frontiers for Online Scene Understanding and Exploration
Apr 09, 2025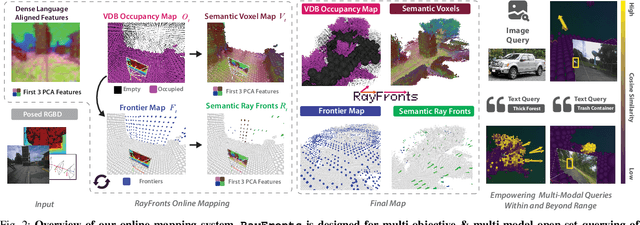
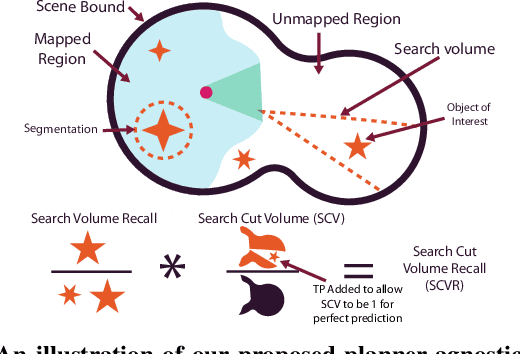
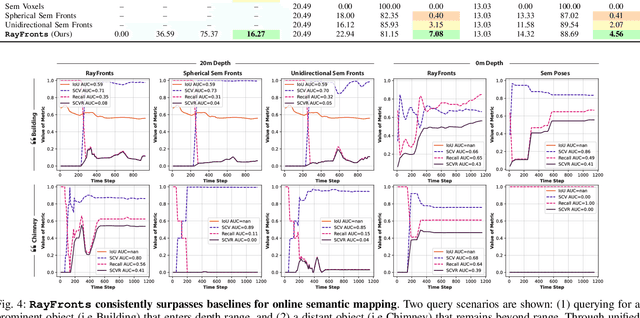
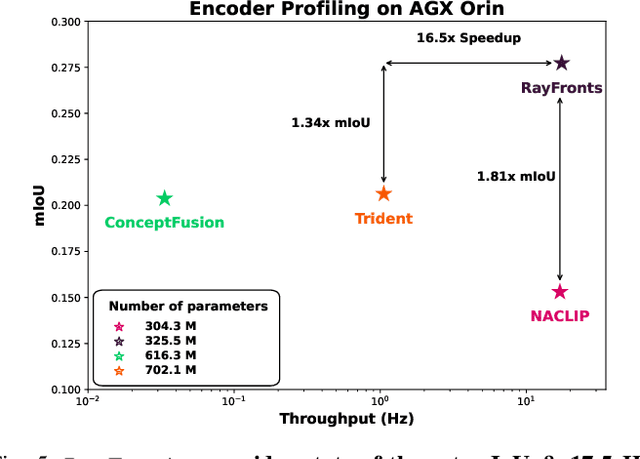
Open-set semantic mapping is crucial for open-world robots. Current mapping approaches either are limited by the depth range or only map beyond-range entities in constrained settings, where overall they fail to combine within-range and beyond-range observations. Furthermore, these methods make a trade-off between fine-grained semantics and efficiency. We introduce RayFronts, a unified representation that enables both dense and beyond-range efficient semantic mapping. RayFronts encodes task-agnostic open-set semantics to both in-range voxels and beyond-range rays encoded at map boundaries, empowering the robot to reduce search volumes significantly and make informed decisions both within & beyond sensory range, while running at 8.84 Hz on an Orin AGX. Benchmarking the within-range semantics shows that RayFronts's fine-grained image encoding provides 1.34x zero-shot 3D semantic segmentation performance while improving throughput by 16.5x. Traditionally, online mapping performance is entangled with other system components, complicating evaluation. We propose a planner-agnostic evaluation framework that captures the utility for online beyond-range search and exploration, and show RayFronts reduces search volume 2.2x more efficiently than the closest online baselines.
PIPE Planner: Pathwise Information Gain with Map Predictions for Indoor Robot Exploration
Mar 10, 2025



Autonomous exploration in unknown environments requires estimating the information gain of an action to guide planning decisions. While prior approaches often compute information gain at discrete waypoints, pathwise integration offers a more comprehensive estimation but is often computationally challenging or infeasible and prone to overestimation. In this work, we propose the Pathwise Information Gain with Map Prediction for Exploration (PIPE) planner, which integrates cumulative sensor coverage along planned trajectories while leveraging map prediction to mitigate overestimation. To enable efficient pathwise coverage computation, we introduce a method to efficiently calculate the expected observation mask along the planned path, significantly reducing computational overhead. We validate PIPE on real-world floorplan datasets, demonstrating its superior performance over state-of-the-art baselines. Our results highlight the benefits of integrating predictive mapping with pathwise information gain for efficient and informed exploration.
MapExRL: Human-Inspired Indoor Exploration with Predicted Environment Context and Reinforcement Learning
Mar 03, 2025



Path planning for robotic exploration is challenging, requiring reasoning over unknown spaces and anticipating future observations. Efficient exploration requires selecting budget-constrained paths that maximize information gain. Despite advances in autonomous exploration, existing algorithms still fall short of human performance, particularly in structured environments where predictive cues exist but are underutilized. Guided by insights from our user study, we introduce MapExRL, which improves robot exploration efficiency in structured indoor environments by enabling longer-horizon planning through reinforcement learning (RL) and global map predictions. Unlike many RL-based exploration methods that use motion primitives as the action space, our approach leverages frontiers for more efficient model learning and longer horizon reasoning. Our framework generates global map predictions from the observed map, which our policy utilizes, along with the prediction uncertainty, estimated sensor coverage, frontier distance, and remaining distance budget, to assess the strategic long-term value of frontiers. By leveraging multiple frontier scoring methods and additional context, our policy makes more informed decisions at each stage of the exploration. We evaluate our framework on a real-world indoor map dataset, achieving up to an 18.8% improvement over the strongest state-of-the-art baseline, with even greater gains compared to conventional frontier-based algorithms.
Toward General-Purpose Robots via Foundation Models: A Survey and Meta-Analysis
Dec 15, 2023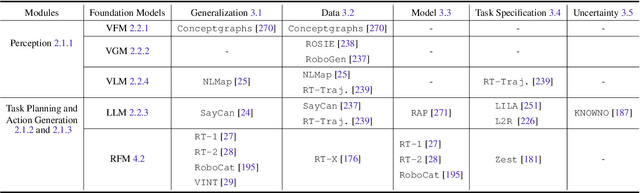

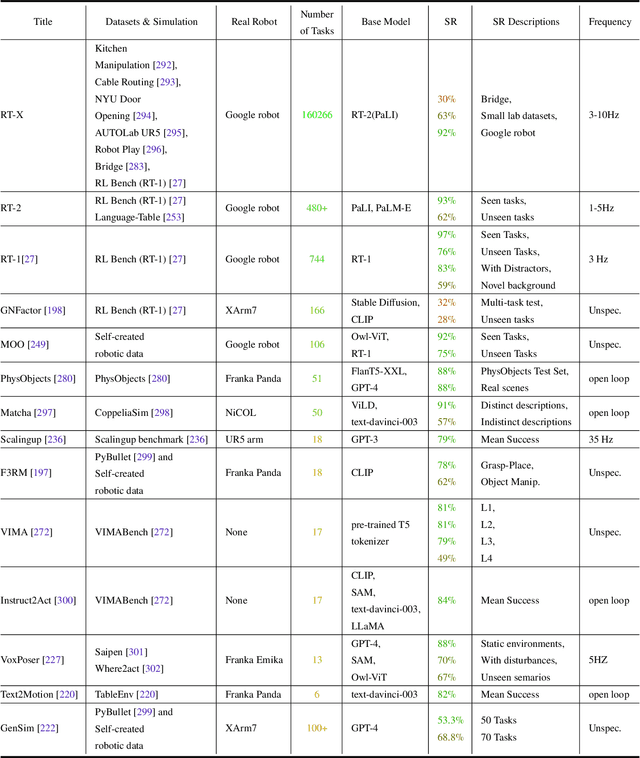
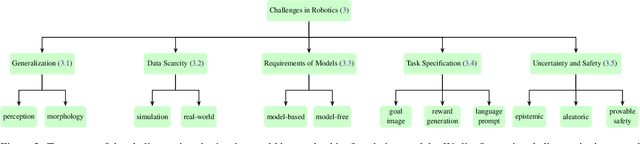
Building general-purpose robots that can operate seamlessly, in any environment, with any object, and utilizing various skills to complete diverse tasks has been a long-standing goal in Artificial Intelligence. Unfortunately, however, most existing robotic systems have been constrained - having been designed for specific tasks, trained on specific datasets, and deployed within specific environments. These systems usually require extensively-labeled data, rely on task-specific models, have numerous generalization issues when deployed in real-world scenarios, and struggle to remain robust to distribution shifts. Motivated by the impressive open-set performance and content generation capabilities of web-scale, large-capacity pre-trained models (i.e., foundation models) in research fields such as Natural Language Processing (NLP) and Computer Vision (CV), we devote this survey to exploring (i) how these existing foundation models from NLP and CV can be applied to the field of robotics, and also exploring (ii) what a robotics-specific foundation model would look like. We begin by providing an overview of what constitutes a conventional robotic system and the fundamental barriers to making it universally applicable. Next, we establish a taxonomy to discuss current work exploring ways to leverage existing foundation models for robotics and develop ones catered to robotics. Finally, we discuss key challenges and promising future directions in using foundation models for enabling general-purpose robotic systems. We encourage readers to view our living GitHub repository of resources, including papers reviewed in this survey as well as related projects and repositories for developing foundation models for robotics.
Multi-Robot Multi-Room Exploration with Geometric Cue Extraction and Spherical Decomposition
Jul 27, 2023



This work proposes an autonomous multi-robot exploration pipeline that coordinates the behaviors of robots in an indoor environment composed of multiple rooms. Contrary to simple frontier-based exploration approaches, we aim to enable robots to methodically explore and observe an unknown set of rooms in a structured building, keeping track of which rooms are already explored and sharing this information among robots to coordinate their behaviors in a distributed manner. To this end, we propose (1) a geometric cue extraction method that processes 3D map point cloud data and detects the locations of potential cues such as doors and rooms, (2) a spherical decomposition for open spaces used for target assignment. Using these two components, our pipeline effectively assigns tasks among robots, and enables a methodical exploration of rooms. We evaluate the performance of our pipeline using a team of up to 3 aerial robots, and show that our method outperforms the baseline by 36.6% in simulation and 26.4% in real-world experiments.
Robotic Interestingness via Human-Informed Few-Shot Object Detection
Aug 01, 2022


Interestingness recognition is crucial for decision making in autonomous exploration for mobile robots. Previous methods proposed an unsupervised online learning approach that can adapt to environments and detect interesting scenes quickly, but lack the ability to adapt to human-informed interesting objects. To solve this problem, we introduce a human-interactive framework, AirInteraction, that can detect human-informed objects via few-shot online learning. To reduce the communication bandwidth, we first apply an online unsupervised learning algorithm on the unmanned vehicle for interestingness recognition and then only send the potential interesting scenes to a base-station for human inspection. The human operator is able to draw and provide bounding box annotations for particular interesting objects, which are sent back to the robot to detect similar objects via few-shot learning. Only using few human-labeled examples, the robot can learn novel interesting object categories during the mission and detect interesting scenes that contain the objects. We evaluate our method on various interesting scene recognition datasets. To the best of our knowledge, it is the first human-informed few-shot object detection framework for autonomous exploration.
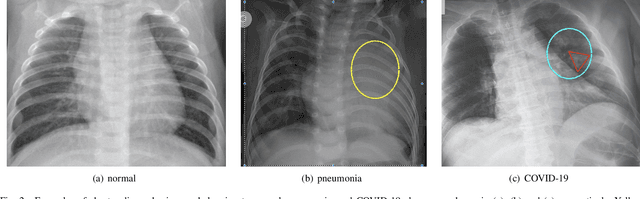
Calibrated Bagging Deep Learning for Image Semantic Segmentation: A Case Study on COVID-19 Chest X-ray Image
May 27, 2022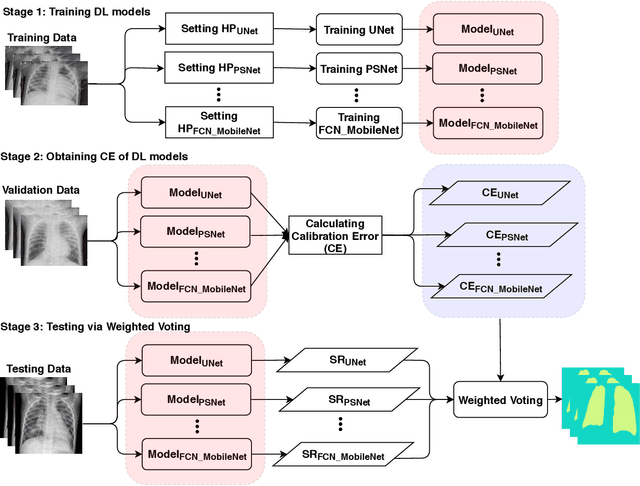
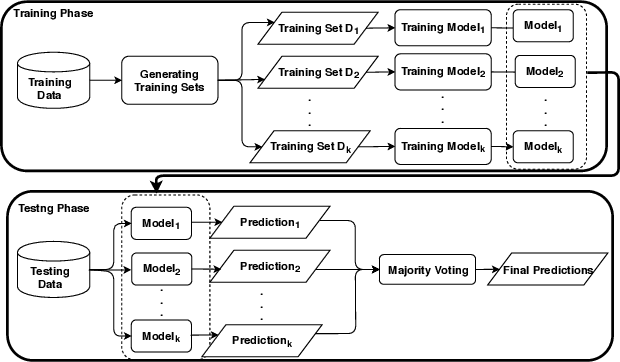
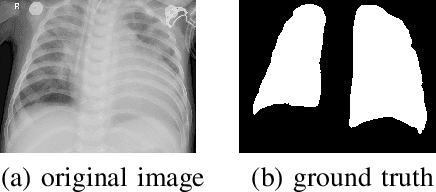
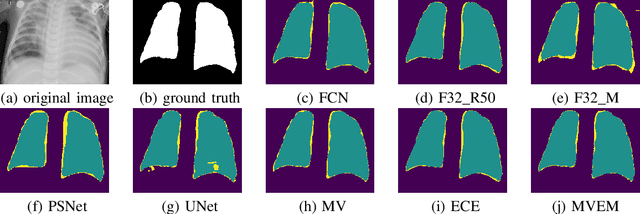
Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) causes coronavirus disease 2019 (COVID-19). Imaging tests such as chest X-ray (CXR) and computed tomography (CT) can provide useful information to clinical staff for facilitating a diagnosis of COVID-19 in a more efficient and comprehensive manner. As a breakthrough of artificial intelligence (AI), deep learning has been applied to perform COVID-19 infection region segmentation and disease classification by analyzing CXR and CT data. However, prediction uncertainty of deep learning models for these tasks, which is very important to safety-critical applications like medical image processing, has not been comprehensively investigated. In this work, we propose a novel ensemble deep learning model through integrating bagging deep learning and model calibration to not only enhance segmentation performance, but also reduce prediction uncertainty. The proposed method has been validated on a large dataset that is associated with CXR image segmentation. Experimental results demonstrate that the proposed method can improve the segmentation performance, as well as decrease prediction uncertainties.
AirDet: Few-Shot Detection without Fine-tuning for Autonomous Exploration
Dec 03, 2021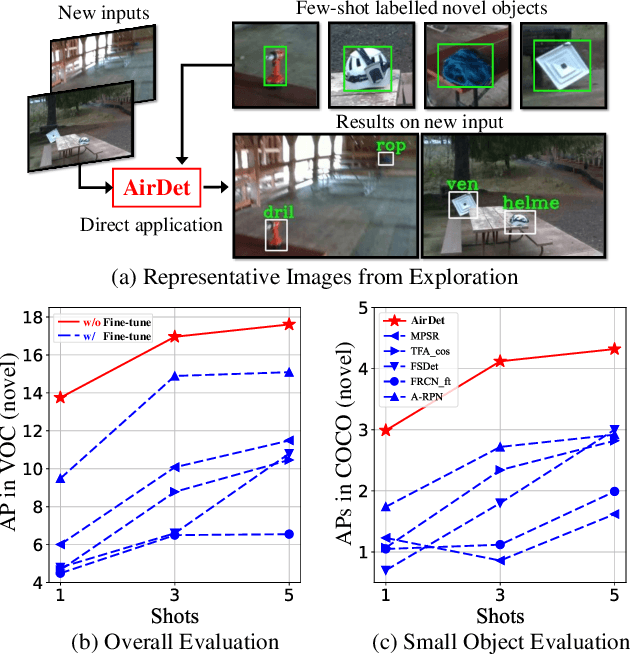
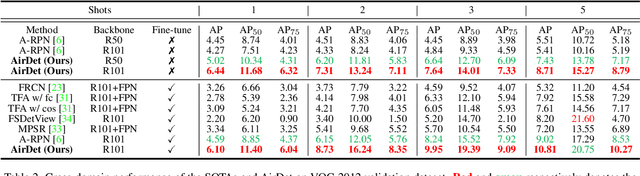
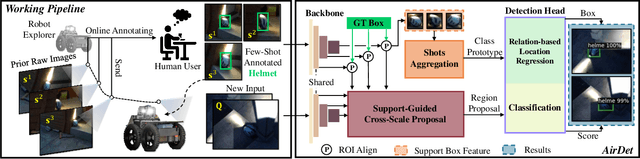
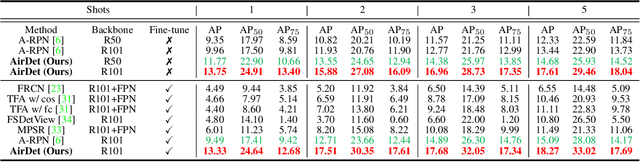
Few-shot object detection has rapidly progressed owing to the success of meta-learning strategies. However, the requirement of a fine-tuning stage in existing methods is timeconsuming and significantly hinders their usage in real-time applications such as autonomous exploration of low-power robots. To solve this problem, we present a brand new architecture, AirDet, which is free of fine-tuning by learning class agnostic relation with support images. Specifically, we propose a support-guided cross-scale (SCS) feature fusion network to generate object proposals, a global-local relation network (GLR) for shots aggregation, and a relation-based prototype embedding network (R-PEN) for precise localization. Exhaustive experiments are conducted on COCO and PASCAL VOC datasets, where surprisingly, AirDet achieves comparable or even better results than the exhaustively finetuned methods, reaching up to 40-60% improvements on the baseline. To our excitement, AirDet obtains favorable performance on multi-scale objects, especially the small ones. Furthermore, we present evaluation results on real-world exploration tests from the DARPA Subterranean Challenge, which strongly validate the feasibility of AirDet in robotics. The source code, pre-trained models, along with the real world data for exploration, will be made public.
Unsupervised Online Learning for Robotic Interestingness with Visual Memory
Nov 19, 2021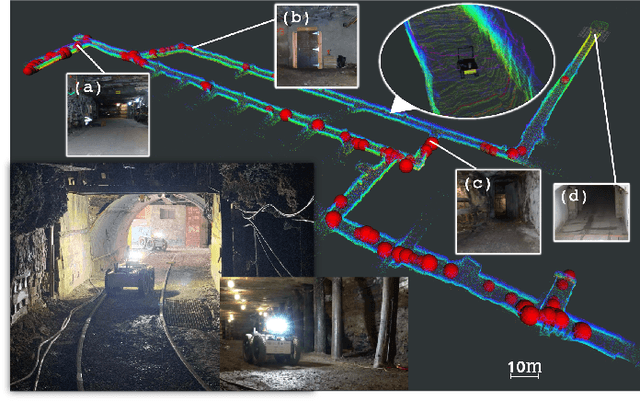

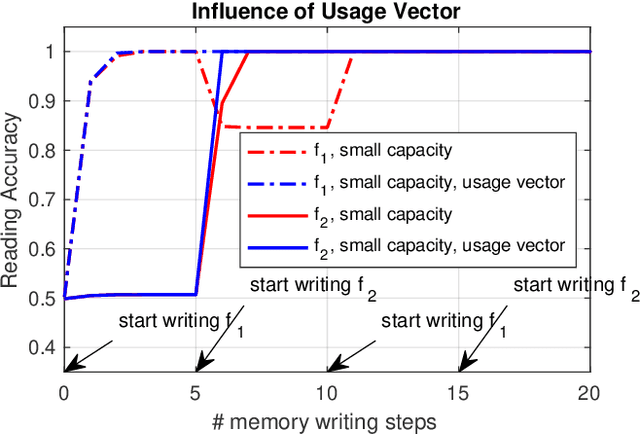

Autonomous robots frequently need to detect "interesting" scenes to decide on further exploration, or to decide which data to share for cooperation. These scenarios often require fast deployment with little or no training data. Prior work considers "interestingness" based on data from the same distribution. Instead, we propose to develop a method that automatically adapts online to the environment to report interesting scenes quickly. To address this problem, we develop a novel translation-invariant visual memory and design a three-stage architecture for long-term, short-term, and online learning, which enables the system to learn human-like experience, environmental knowledge, and online adaption, respectively. With this system, we achieve an average of 20% higher accuracy than the state-of-the-art unsupervised methods in a subterranean tunnel environment. We show comparable performance to supervised methods for robot exploration scenarios showing the efficacy of our approach. We expect that the presented method will play an important role in the robotic interestingness recognition exploration tasks.
Semi-supervised Learning for COVID-19 Image Classification via ResNet
Feb 27, 2021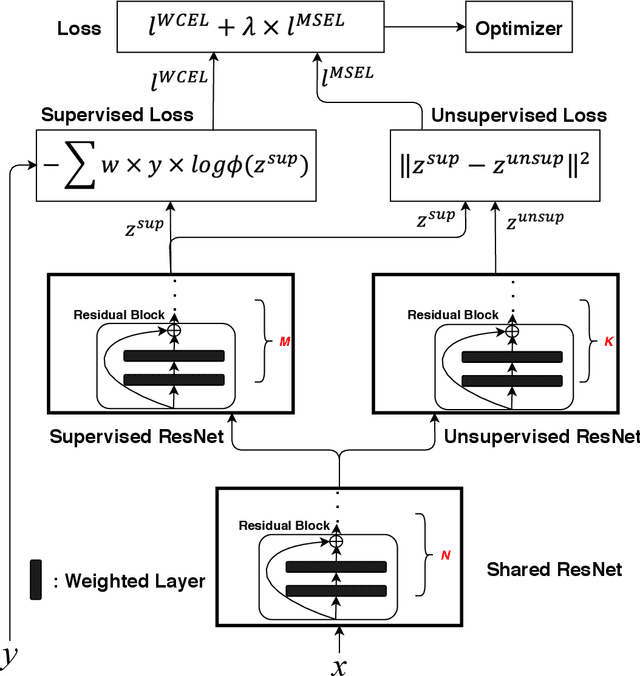
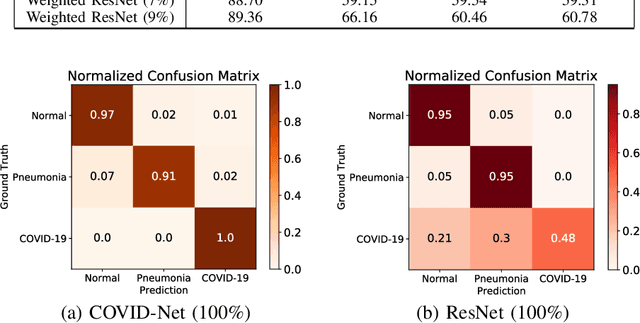
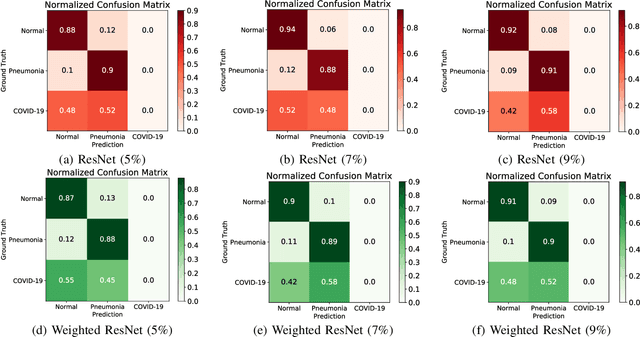
Coronavirus disease 2019 (COVID-19) is an ongoing global pandemic in over 200 countries and territories, which has resulted in a great public health concern across the international community. Analysis of X-ray imaging data can play a critical role in timely and accurate screening and fighting against COVID-19. Supervised deep learning has been successfully applied to recognize COVID-19 pathology from X-ray imaging datasets. However, it requires a substantial amount of annotated X-ray images to train models, which is often not applicable to data analysis for emerging events such as COVID-19 outbreak, especially in the early stage of the outbreak. To address this challenge, this paper proposes a two-path semi-supervised deep learning model, ssResNet, based on Residual Neural Network (ResNet) for COVID-19 image classification, where two paths refer to a supervised path and an unsupervised path, respectively. Moreover, we design a weighted supervised loss that assigns higher weight for the minority classes in the training process to resolve the data imbalance. Experimental results on a large-scale of X-ray image dataset COVIDx demonstrate that the proposed model can achieve promising performance even when trained on very few labeled training images.