 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task GINN-LP for Multi-target Symbolic Regression
Nov 17, 2025In the area of explainable artificial intelligence, Symbolic Regression (SR) has emerged as a promising approach by discovering interpretable mathematical expressions that fit data. However, SR faces two main challenges: most methods are evaluated on scientific datasets with well-understood relationships, limiting generalization, and SR primarily targets single-output regression, whereas many real-world problems involve multi-target outputs with interdependent variables. To address these issues, we propose multi-task regression GINN-LP (MTRGINN-LP), an interpretable neural network for multi-target symbolic regression. By integrating GINN-LP with a multi-task deep learning, the model combines a shared backbone including multiple power-term approximator blocks with task-specific output layers, capturing inter-target dependencies while preserving interpretability. We validate multi-task GINN-LP on practical multi-target applications, including energy efficiency prediction and sustainable agriculture. Experimental results demonstrate competitive predictive performance alongside high interpretability, effectively extending symbolic regression to broader real-world multi-output tasks.
Knowledge Acquisition on Mass-shooting Events via LLMs for AI-Driven Justice
Apr 17, 2025



Mass-shooting events pose a significant challenge to public safety, generating large volumes of unstructured textual data that hinder effective investigations and the formulation of public policy. Despite the urgency, few prior studies have effectively automated the extraction of key information from these events to support legal and investigative efforts. This paper presented the first dataset designed for knowledge acquisition on mass-shooting events through the application of named entity recognition (NER) techniques. It focuses on identifying key entities such as offenders, victims, locations, and criminal instruments, that are vital for legal and investigative purposes. The NER process is powered by Large Language Models (LLMs) using few-shot prompting, facilitating the efficient extraction and organization of critical information from diverse sources, including news articles, police reports, and social media. Experimental results on real-world mass-shooting corpora demonstrate that GPT-4o is the most effective model for mass-shooting NER, achieving the highest Micro Precision, Micro Recall, and Micro F1-scores. Meanwhile, o1-mini delivers competitive performance, making it a resource-efficient alternative for less complex NER tasks. It is also observed that increasing the shot count enhances the performance of all models, but the gains are more substantial for GPT-4o and o1-mini, highlighting their superior adaptability to few-shot learning scenarios.
Data Augmentation via Diffusion Model to Enhance AI Fairness
Oct 20, 2024



AI fairness seeks to improve the transparency and explainability of AI systems by ensuring that their outcomes genuinely reflect the best interests of users. Data augmentation, which involves generating synthetic data from existing datasets, has gained significant attention as a solution to data scarcity. In particular, diffusion models have become a powerful technique for generating synthetic data, especially in fields like computer vision. This paper explores the potential of diffusion models to generate synthetic tabular data to improve AI fairness. The Tabular Denoising Diffusion Probabilistic Model (Tab-DDPM), a diffusion model adaptable to any tabular dataset and capable of handling various feature types, was utilized with different amounts of generated data for data augmentation. Additionally, reweighting samples from AIF360 was employed to further enhance AI fairness. Five traditional machine learning models-Decision Tree (DT), Gaussian Naive Bayes (GNB), K-Nearest Neighbors (KNN), Logistic Regression (LR), and Random Forest (RF)-were used to validate the proposed approach. Experimental results demonstrate that the synthetic data generated by Tab-DDPM improves fairness in binary classification.
Enhancing LLM Fine-tuning for Text-to-SQLs by SQL Quality Measurement
Oct 02, 2024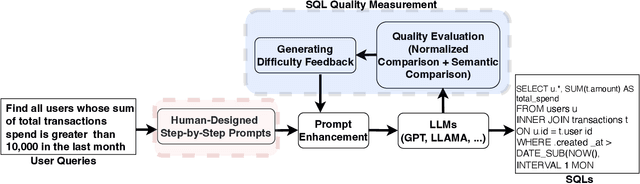
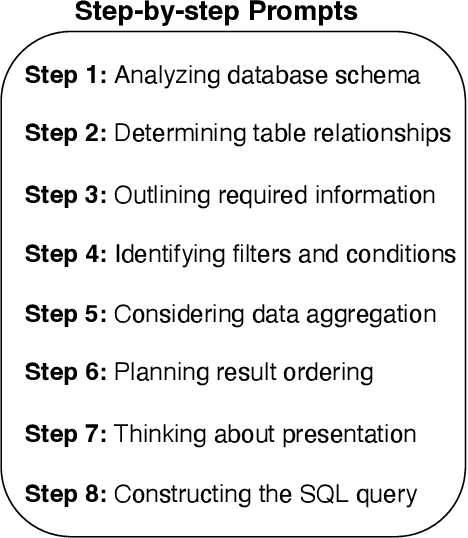
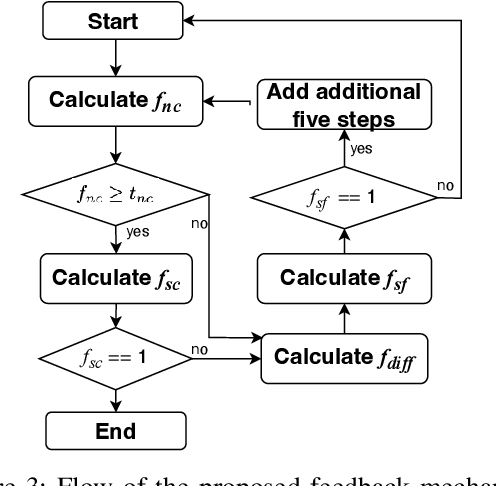
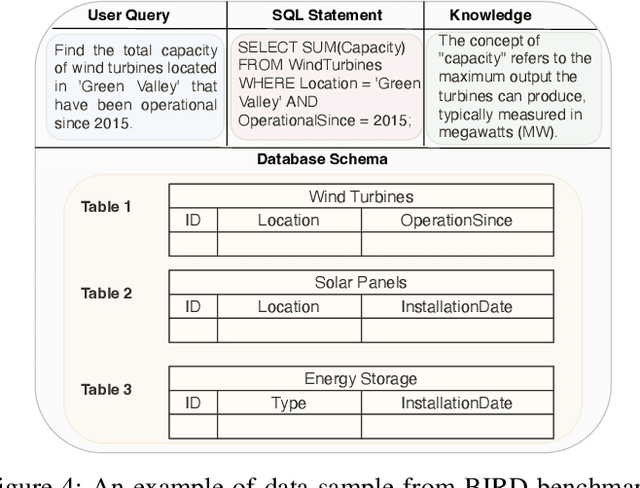
Text-to-SQLs enables non-expert users to effortlessly retrieve desired information from relational databases using natural language queries. While recent advancements, particularly with Large Language Models (LLMs) like GPT and T5, have shown impressive performance on large-scale benchmarks such as BIRD, current state-of-the-art (SOTA) LLM-based Text-to-SQLs models often require significant efforts to develop auxiliary tools like SQL classifiers to achieve high performance. This paper proposed a novel approach that only needs SQL Quality Measurement to enhance LLMs-based Text-to-SQLs performance. It establishes a SQL quality evaluation mechanism to assess the generated SQL queries against predefined criteria and actual database responses. This feedback loop enables continuous learning and refinement of model outputs based on both syntactic correctness and semantic accuracy. The proposed method undergoes comprehensive validation on the BIRD benchmark, assessing Execution Accuracy (EX) and Valid Efficiency Score (VES) across various Text-to-SQLs difficulty levels. Experimental results reveal competitive performance in both EX and VES compared to SOTA models like GPT4 and T5.
Enhancing Deep Knowledge Tracing via Diffusion Models for Personalized Adaptive Learning
Apr 25, 2024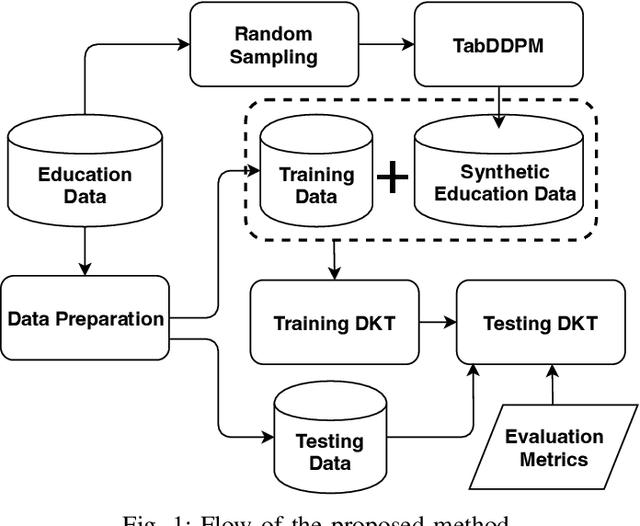
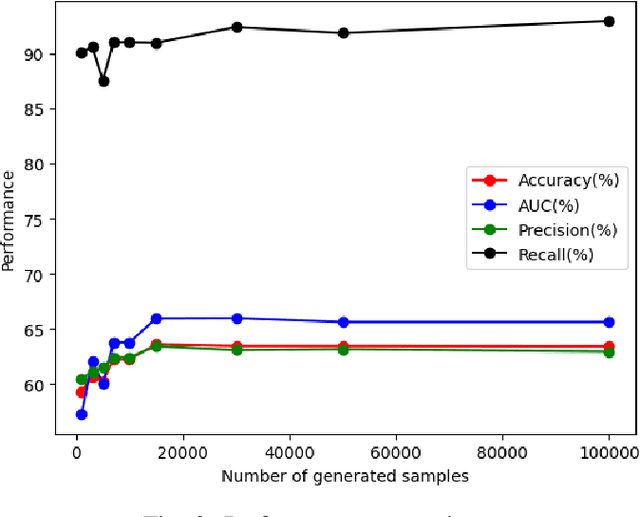
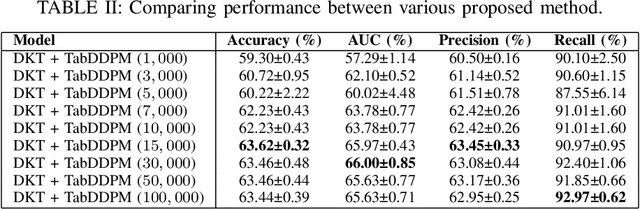
In contrast to pedagogies like evidence-based teaching, personalized adaptive learning (PAL) distinguishes itself by closely monitoring the progress of individual students and tailoring the learning path to their unique knowledge and requirements. A crucial technique for effective PAL implementation is knowledge tracing, which models students' evolving knowledge to predict their future performance. Based on these predictions, personalized recommendations for resources and learning paths can be made to meet individual needs. Recent advancements in deep learning have successfully enhanced knowledge tracking through Deep Knowledge Tracing (DKT). This paper introduces generative AI models to further enhance DKT. Generative AI models, rooted in deep learning, are trained to generate synthetic data, addressing data scarcity challenges in various applications across fields such as natural language processing (NLP) and computer vision (CV). This study aims to tackle data shortage issues in student learning records to enhance DKT performance for PAL. Specifically, it employs TabDDPM, a diffusion model, to generate synthetic educational records to augment training data for enhancing DKT. The proposed method's effectiveness is validated through extensive experiments on ASSISTments datasets. The experimental results demonstrate that the AI-generated data by TabDDPM significantly improves DKT performance, particularly in scenarios with small data for training and large data for testing.
Comprehensive Validation on Reweighting Samples for Bias Mitigation via AIF360
Dec 19, 2023



Fairness AI aims to detect and alleviate bias across the entire AI development life cycle, encompassing data curation, modeling, evaluation, and deployment-a pivotal aspect of ethical AI implementation. Addressing data bias, particularly concerning sensitive attributes like gender and race, reweighting samples proves efficient for fairness AI. This paper contributes a systematic examination of reweighting samples for traditional machine learning (ML) models, employing five models for binary classification on the Adult Income and COMPUS datasets with various protected attributes. The study evaluates prediction results using five fairness metrics, uncovering the nuanced and model-specific nature of reweighting sample effectiveness in achieving fairness in traditional ML models, as well as revealing the complexity of bias dynamics.
Medical Data Augmentation via ChatGPT: A Case Study on Medication Identification and Medication Event Classification
Jun 10, 2023



The identification of key factors such as medications, diseases, and relationships within electronic health records and clinical notes has a wide range of applications in the clinical field. In the N2C2 2022 competitions, various tasks were presented to promote the identification of key factors in electronic health records (EHRs) using the Contextualized Medication Event Dataset (CMED). Pretrained large language models (LLMs) demonstrated exceptional performance in these tasks. This study aims to explore the utilization of LLMs, specifically ChatGPT, for data augmentation to overcome the limited availability of annotated data for identifying the key factors in EHRs. Additionally, different pre-trained BERT models, initially trained on extensive datasets like Wikipedia and MIMIC, were employed to develop models for identifying these key variables in EHRs through fine-tuning on augmented datasets. The experimental results of two EHR analysis tasks, namely medication identification and medication event classification, indicate that data augmentation based on ChatGPT proves beneficial in improving performance for both medication identification and medication event classification.
Calibrated Bagging Deep Learning for Image Semantic Segmentation: A Case Study on COVID-19 Chest X-ray Image
May 27, 2022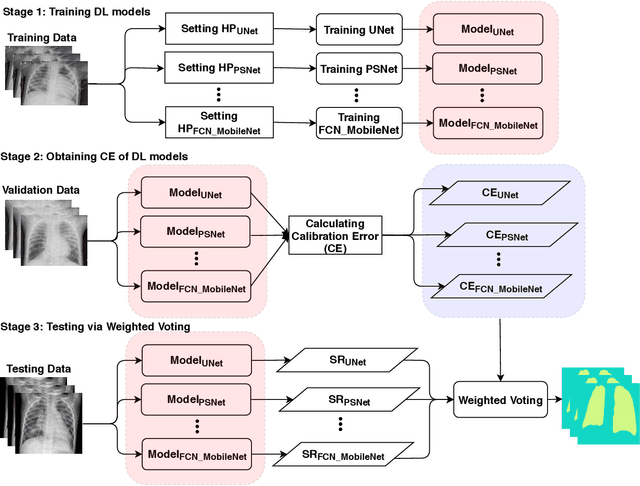
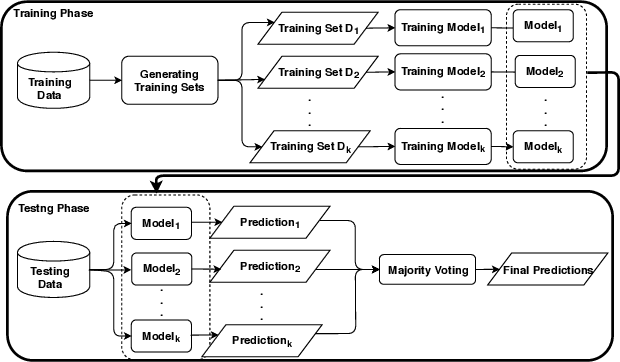
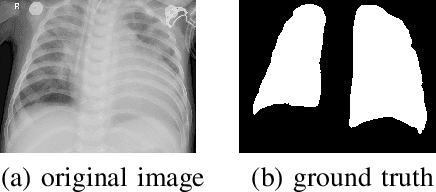
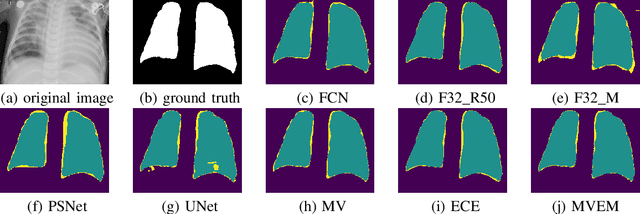
Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) causes coronavirus disease 2019 (COVID-19). Imaging tests such as chest X-ray (CXR) and computed tomography (CT) can provide useful information to clinical staff for facilitating a diagnosis of COVID-19 in a more efficient and comprehensive manner. As a breakthrough of artificial intelligence (AI), deep learning has been applied to perform COVID-19 infection region segmentation and disease classification by analyzing CXR and CT data. However, prediction uncertainty of deep learning models for these tasks, which is very important to safety-critical applications like medical image processing, has not been comprehensively investigated. In this work, we propose a novel ensemble deep learning model through integrating bagging deep learning and model calibration to not only enhance segmentation performance, but also reduce prediction uncertainty. The proposed method has been validated on a large dataset that is associated with CXR image segmentation. Experimental results demonstrate that the proposed method can improve the segmentation performance, as well as decrease prediction uncertainties.
Integrating Human-in-the-loop into Swarm Learning for Decentralized Fake News Detection
Jan 04, 2022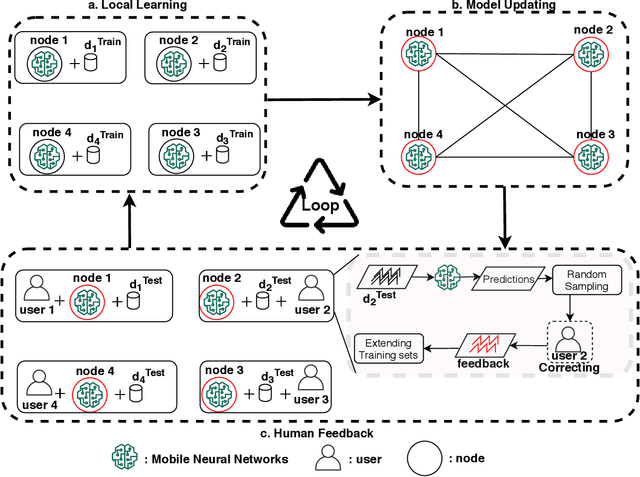
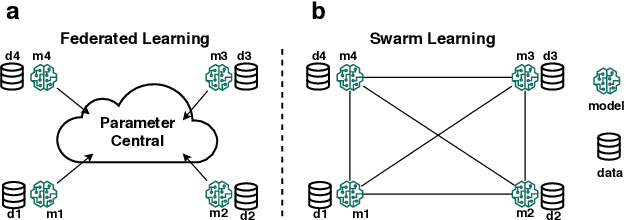
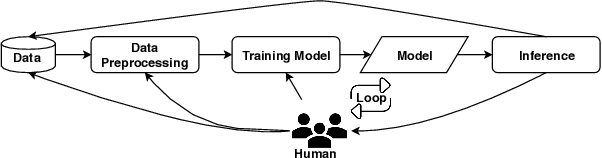
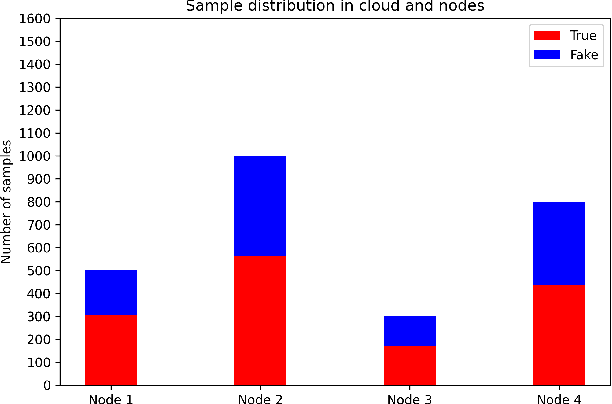
Social media has become an effective platform to generate and spread fake news that can mislead people and even distort public opinion. Centralized methods for fake news detection, however, cannot effectively protect user privacy during the process of centralized data collection for training models. Moreover, it cannot fully involve user feedback in the loop of learning detection models for further enhancing fake news detection. To overcome these challenges, this paper proposed a novel decentralized method, Human-in-the-loop Based Swarm Learning (HBSL), to integrate user feedback into the loop of learning and inference for recognizing fake news without violating user privacy in a decentralized manner. It consists of distributed nodes that are able to independently learn and detect fake news on local data. Furthermore, detection models trained on these nodes can be enhanced through decentralized model merging. Experimental results demonstrate that the proposed method outperforms the state-of-the-art decentralized method in regard of detecting fake news on a benchmark dataset.
A Novel Dataset for Keypoint Detection of quadruped Animals from Images
Aug 31, 2021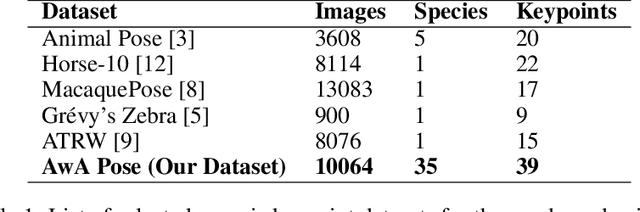
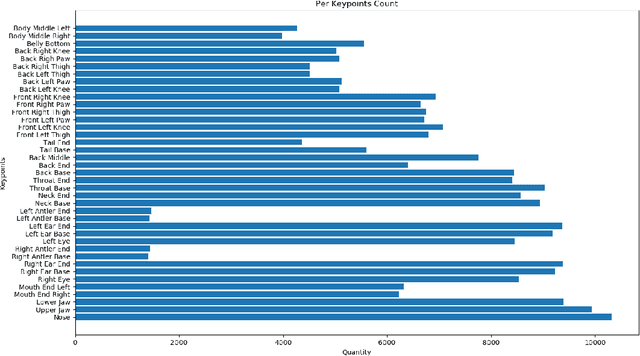

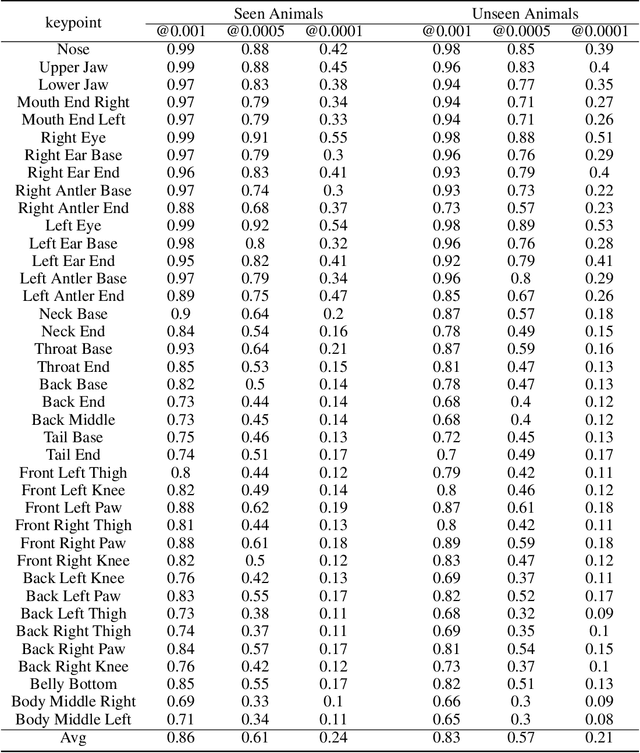
In this paper, we studied the problem of localizing a generic set of keypoints across multiple quadruped or four-legged animal species from images. Due to the lack of large scale animal keypoint dataset with ground truth annotations, we developed a novel dataset, AwA Pose, for keypoint detection of quadruped animals from images. Our dataset contains significantly more keypoints per animal and has much more diverse animals than the existing datasets for animal keypoint detection. We benchmarked the dataset with a state-of-the-art deep learning model for different keypoint detection tasks, including both seen and unseen animal cases. Experimental results showed the effectiveness of the dataset. We believe that this dataset will help the computer vision community in the design and evaluation of improved models for the generalized quadruped animal keypoint detection problem.