 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM Fine-tuning for Text-to-SQLs by SQL Quality Measurement
Paper and Code
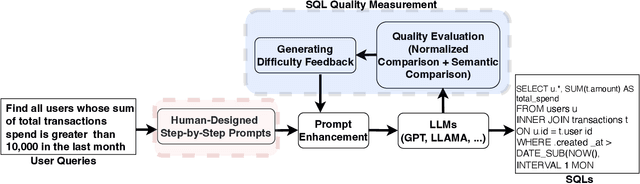
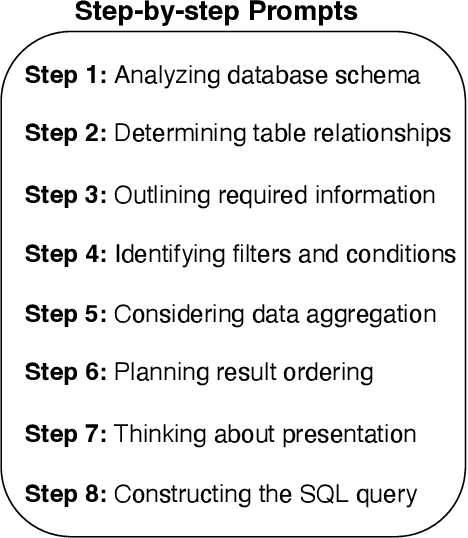
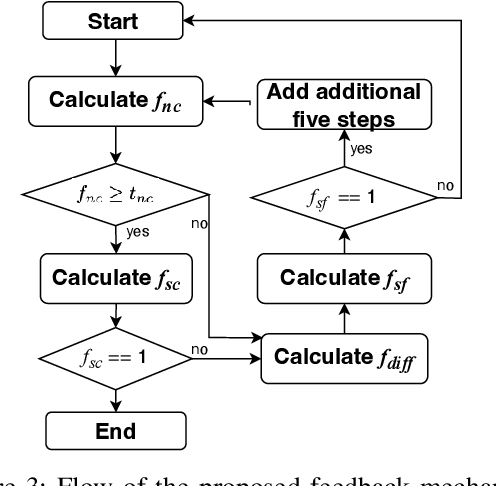
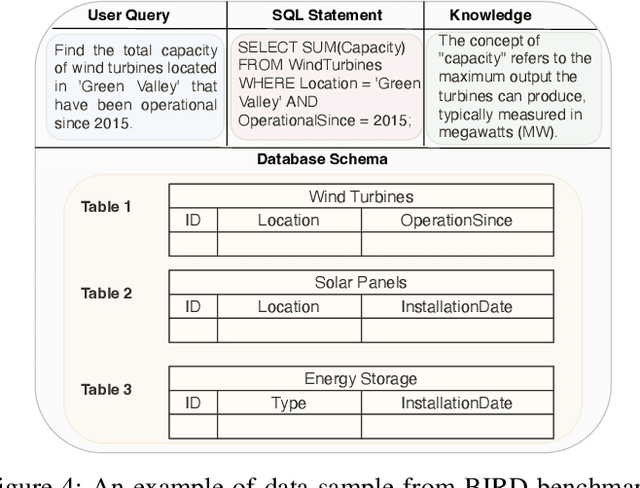
Text-to-SQLs enables non-expert users to effortlessly retrieve desired information from relational databases using natural language queries. While recent advancements, particularly with Large Language Models (LLMs) like GPT and T5, have shown impressive performance on large-scale benchmarks such as BIRD, current state-of-the-art (SOTA) LLM-based Text-to-SQLs models often require significant efforts to develop auxiliary tools like SQL classifiers to achieve high performance. This paper proposed a novel approach that only needs SQL Quality Measurement to enhance LLMs-based Text-to-SQLs performance. It establishes a SQL quality evaluation mechanism to assess the generated SQL queries against predefined criteria and actual database responses. This feedback loop enables continuous learning and refinement of model outputs based on both syntactic correctness and semantic accuracy. The proposed method undergoes comprehensive validation on the BIRD benchmark, assessing Execution Accuracy (EX) and Valid Efficiency Score (VES) across various Text-to-SQLs difficulty levels. Experimental results reveal competitive performance in both EX and VES compared to SOTA models like GPT4 and T5.