 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering and Aligning Anomalous Attention Heads to Defend Against NLP Backdoor Attacks
Nov 16, 2025



Backdoor attacks pose a serious threat to the security of large language models (LLMs), causing them to exhibit anomalous behavior under specific trigger conditions. The design of backdoor triggers has evolved from fixed triggers to dynamic or implicit triggers. This increased flexibility in trigger design makes it challenging for defenders to identify their specific forms accurately. Most existing backdoor defense methods are limited to specific types of triggers or rely on an additional clean model for support. To address this issue, we propose a backdoor detection method based on attention similarity, enabling backdoor detection without prior knowledge of the trigger. Our study reveals that models subjected to backdoor attacks exhibit unusually high similarity among attention heads when exposed to triggers. Based on this observation, we propose an attention safety alignment approach combined with head-wise fine-tuning to rectify potentially contaminated attention heads, thereby effectively mitigating the impact of backdoor attacks. Extensive experimental results demonstrate that our method significantly reduces the success rate of backdoor attacks while preserving the model's performance on downstream tasks.
Enhancing LLM Fine-tuning for Text-to-SQLs by SQL Quality Measurement
Oct 02, 2024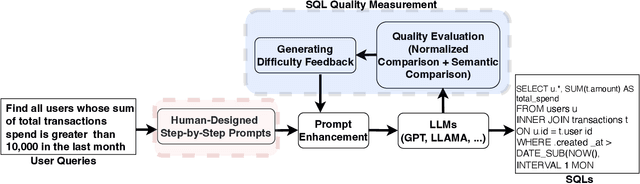
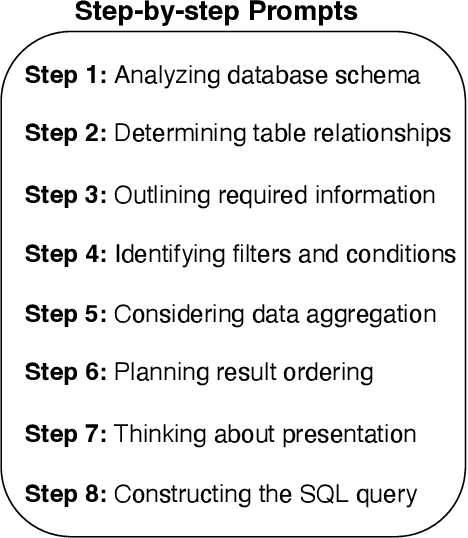
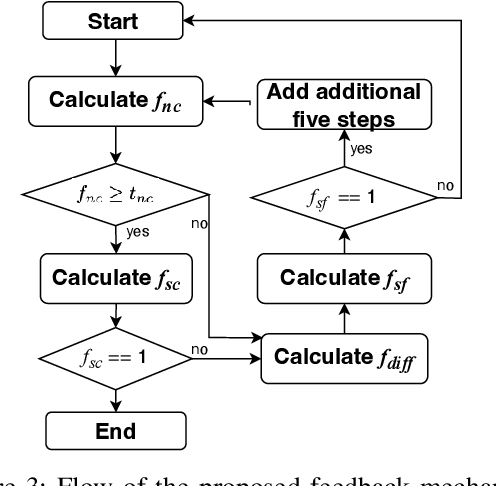
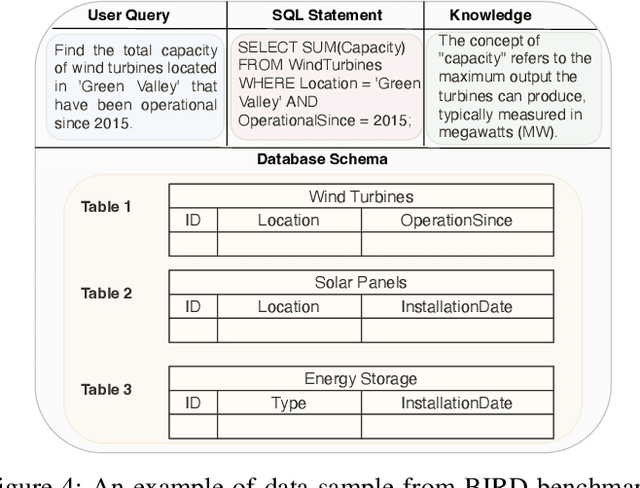
Text-to-SQLs enables non-expert users to effortlessly retrieve desired information from relational databases using natural language queries. While recent advancements, particularly with Large Language Models (LLMs) like GPT and T5, have shown impressive performance on large-scale benchmarks such as BIRD, current state-of-the-art (SOTA) LLM-based Text-to-SQLs models often require significant efforts to develop auxiliary tools like SQL classifiers to achieve high performance. This paper proposed a novel approach that only needs SQL Quality Measurement to enhance LLMs-based Text-to-SQLs performance. It establishes a SQL quality evaluation mechanism to assess the generated SQL queries against predefined criteria and actual database responses. This feedback loop enables continuous learning and refinement of model outputs based on both syntactic correctness and semantic accuracy. The proposed method undergoes comprehensive validation on the BIRD benchmark, assessing Execution Accuracy (EX) and Valid Efficiency Score (VES) across various Text-to-SQLs difficulty levels. Experimental results reveal competitive performance in both EX and VES compared to SOTA models like GPT4 and T5.
Enhancing Deep Knowledge Tracing via Diffusion Models for Personalized Adaptive Learning
Apr 25, 2024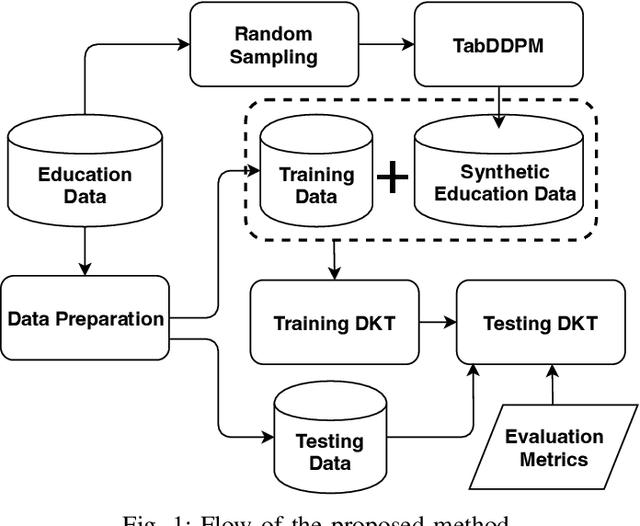
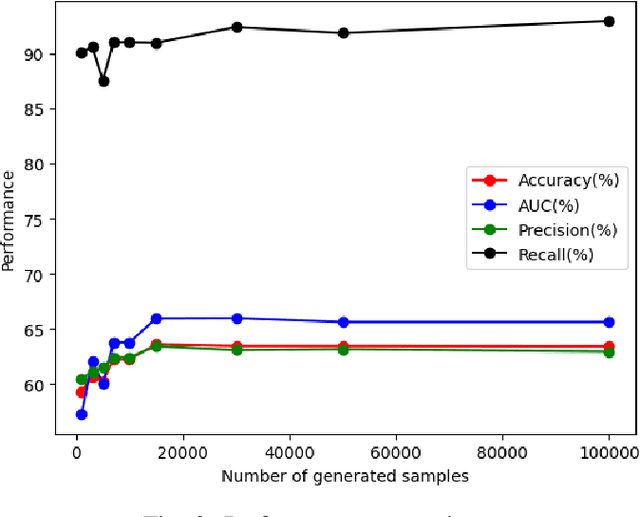
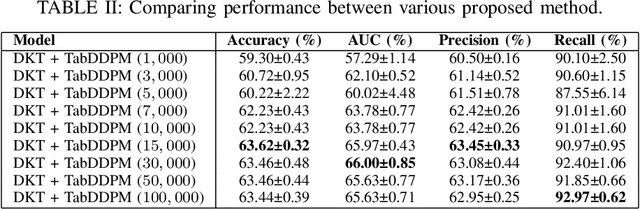
In contrast to pedagogies like evidence-based teaching, personalized adaptive learning (PAL) distinguishes itself by closely monitoring the progress of individual students and tailoring the learning path to their unique knowledge and requirements. A crucial technique for effective PAL implementation is knowledge tracing, which models students' evolving knowledge to predict their future performance. Based on these predictions, personalized recommendations for resources and learning paths can be made to meet individual needs. Recent advancements in deep learning have successfully enhanced knowledge tracking through Deep Knowledge Tracing (DKT). This paper introduces generative AI models to further enhance DKT. Generative AI models, rooted in deep learning, are trained to generate synthetic data, addressing data scarcity challenges in various applications across fields such as natural language processing (NLP) and computer vision (CV). This study aims to tackle data shortage issues in student learning records to enhance DKT performance for PAL. Specifically, it employs TabDDPM, a diffusion model, to generate synthetic educational records to augment training data for enhancing DKT. The proposed method's effectiveness is validated through extensive experiments on ASSISTments datasets. The experimental results demonstrate that the AI-generated data by TabDDPM significantly improves DKT performance, particularly in scenarios with small data for training and large data for testing.
Inverse Quantum Fourier Transform Inspired Algorithm for Unsupervised Image Segmentation
Jan 11, 2023Image segmentation is a very popular and important task in computer vision. In this paper, inverse quantum Fourier transform (IQFT) for image segmentation has been explored and a novel IQFT-inspired algorithm is proposed and implemented by leveraging the underlying mathematical structure of the IQFT. Specifically, the proposed method takes advantage of the phase information of the pixels in the image by encoding the pixels' intensity into qubit relative phases and applying IQFT to classify the pixels into different segments automatically and efficiently. To the best of our knowledge, this is the first attempt of using IQFT for unsupervised image segmentation. The proposed method has low computational cost comparing to the deep learning-based methods and more importantly it does not require training, thus make it suitable for real-time applications. The performance of the proposed method is compared with K-means and Otsu-thresholding. The proposed method outperforms both of them on the PASCAL VOC 2012 segmentation benchmark and the xVIEW2 challenge dataset by as much as 50% in terms of mean Intersection-Over-Union (mIOU).
Calibrated Bagging Deep Learning for Image Semantic Segmentation: A Case Study on COVID-19 Chest X-ray Image
May 27, 2022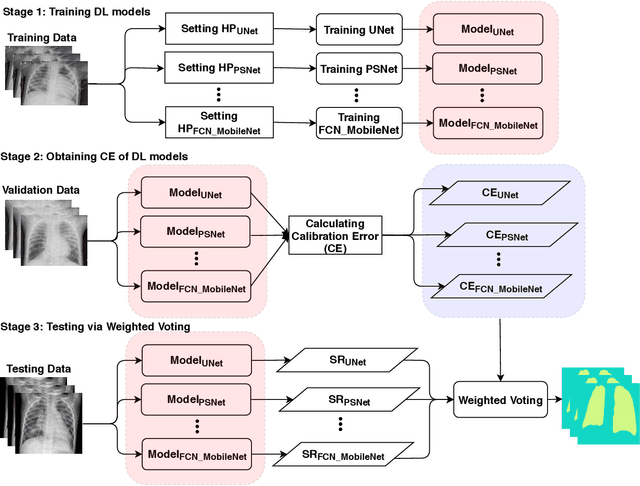
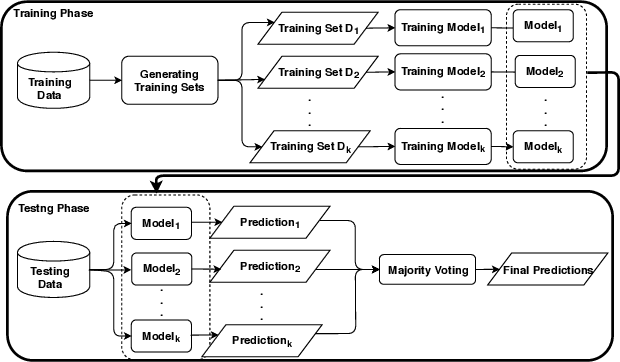
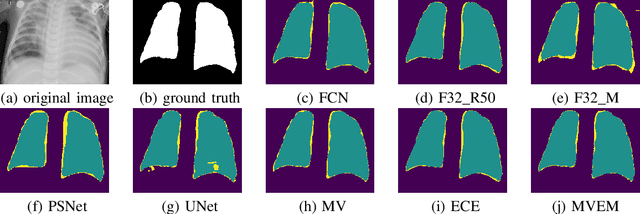
Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) causes coronavirus disease 2019 (COVID-19). Imaging tests such as chest X-ray (CXR) and computed tomography (CT) can provide useful information to clinical staff for facilitating a diagnosis of COVID-19 in a more efficient and comprehensive manner. As a breakthrough of artificial intelligence (AI), deep learning has been applied to perform COVID-19 infection region segmentation and disease classification by analyzing CXR and CT data. However, prediction uncertainty of deep learning models for these tasks, which is very important to safety-critical applications like medical image processing, has not been comprehensively investigated. In this work, we propose a novel ensemble deep learning model through integrating bagging deep learning and model calibration to not only enhance segmentation performance, but also reduce prediction uncertainty. The proposed method has been validated on a large dataset that is associated with CXR image segmentation. Experimental results demonstrate that the proposed method can improve the segmentation performance, as well as decrease prediction uncertainties.
Semi-supervised Learning for COVID-19 Image Classification via ResNet
Feb 27, 2021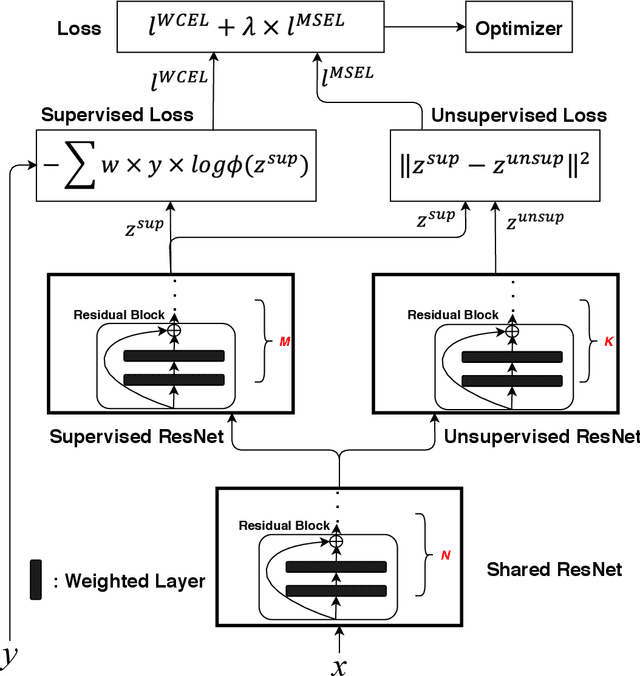
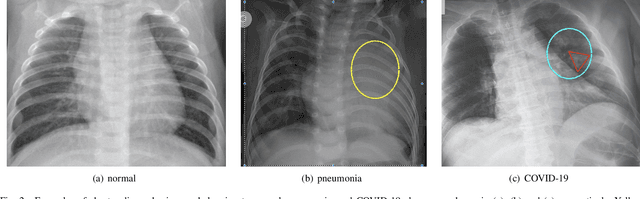
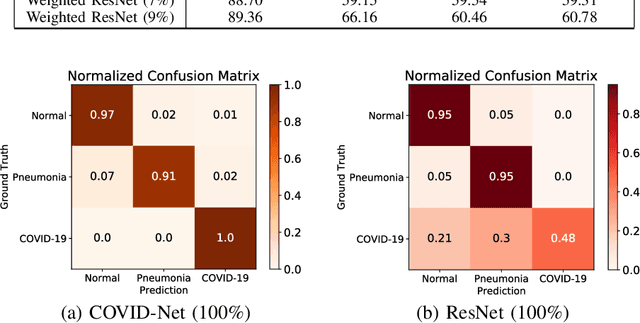
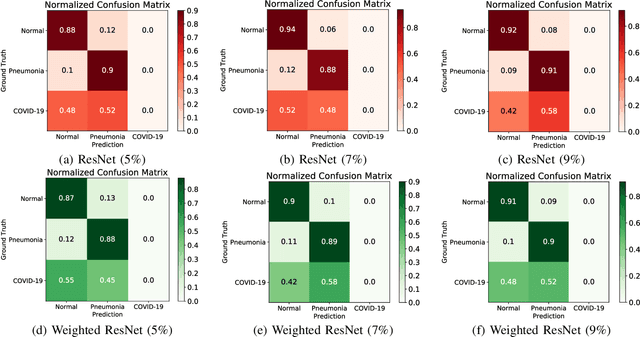
Coronavirus disease 2019 (COVID-19) is an ongoing global pandemic in over 200 countries and territories, which has resulted in a great public health concern across the international community. Analysis of X-ray imaging data can play a critical role in timely and accurate screening and fighting against COVID-19. Supervised deep learning has been successfully applied to recognize COVID-19 pathology from X-ray imaging datasets. However, it requires a substantial amount of annotated X-ray images to train models, which is often not applicable to data analysis for emerging events such as COVID-19 outbreak, especially in the early stage of the outbreak. To address this challenge, this paper proposes a two-path semi-supervised deep learning model, ssResNet, based on Residual Neural Network (ResNet) for COVID-19 image classification, where two paths refer to a supervised path and an unsupervised path, respectively. Moreover, we design a weighted supervised loss that assigns higher weight for the minority classes in the training process to resolve the data imbalance. Experimental results on a large-scale of X-ray image dataset COVIDx demonstrate that the proposed model can achieve promising performance even when trained on very few labeled training images.
Computation Offloading in Multi-Access Edge Computing Networks: A Multi-Task Learning Approach
Jun 29, 2020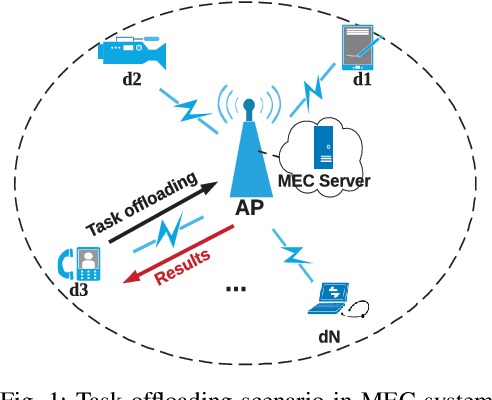
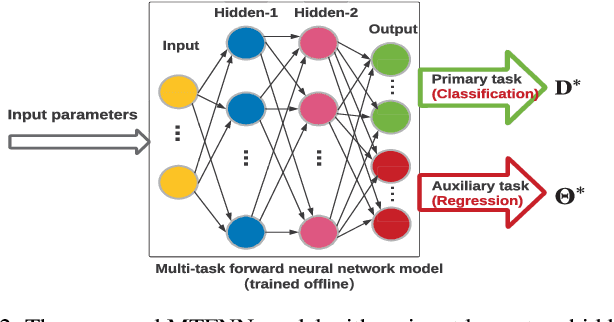
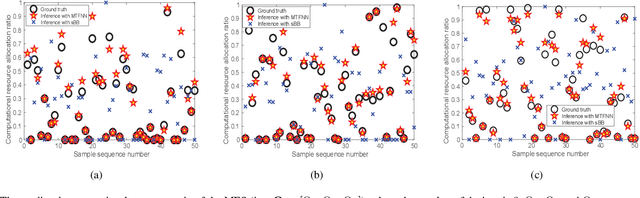
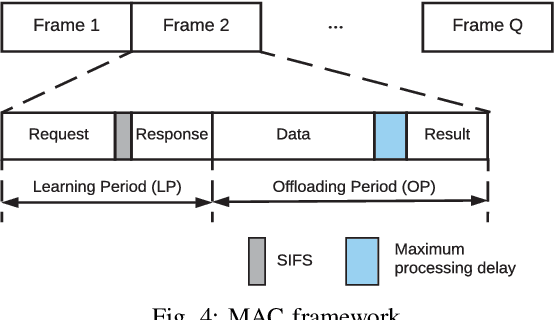
Multi-access edge computing (MEC) has already shown the potential in enabling mobile devices to bear the computation-intensive applications by offloading some tasks to a nearby access point (AP) integrated with a MEC server (MES). However, due to the varying network conditions and limited computation resources of the MES, the offloading decisions taken by a mobile device and the computational resources allocated by the MES may not be efficiently achieved with the lowest cost. In this paper, we propose a dynamic offloading framework for the MEC network, in which the uplink non-orthogonal multiple access (NOMA) is used to enable multiple devices to upload their tasks via the same frequency band. We formulate the offloading decision problem as a multiclass classification problem and formulate the MES computational resource allocation problem as a regression problem. Then a multi-task learning based feedforward neural network (MTFNN) model is designed to jointly optimize the offloading decision and computational resource allocation. Numerical results illustrate that the proposed MTFNN outperforms the conventional optimization method in terms of inference accuracy and computation complexity.
Lessons Learned from Accident of Autonomous Vehicle Testing: An Edge Learning-aided Offloading Framework
Jun 27, 2020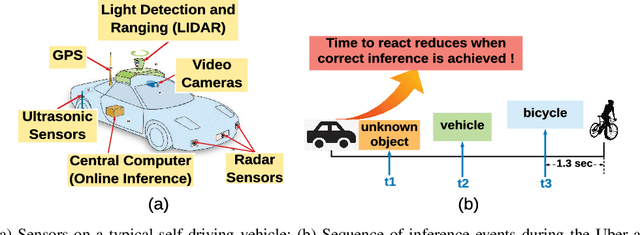
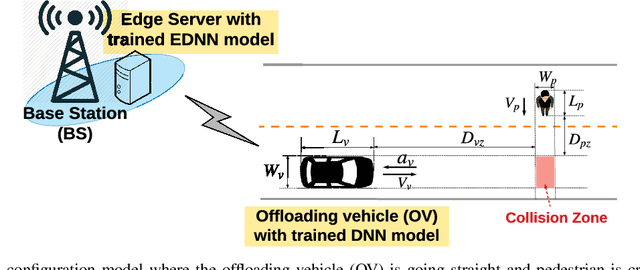
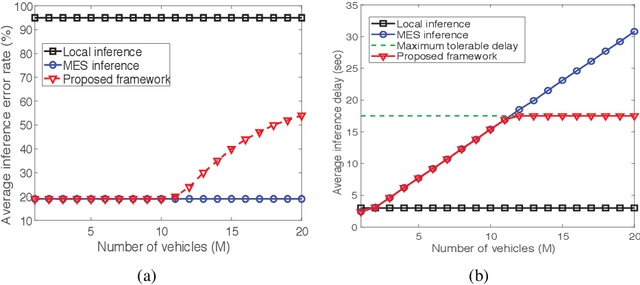
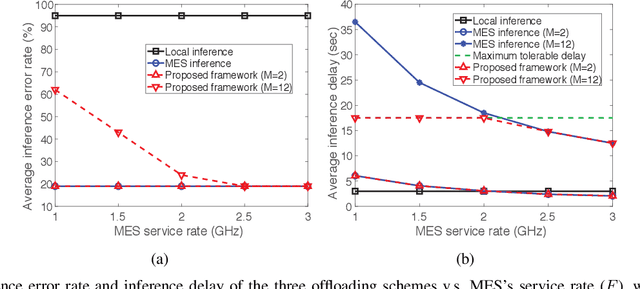
This letter proposes an edge learning-based offloading framework for autonomous driving, where the deep learning tasks can be offloaded to the edge server to improve the inference accuracy while meeting the latency constraint. Since the delay and the inference accuracy are incurred by wireless communications and computing, an optimization problem is formulated to maximize the inference accuracy subject to the offloading probability, the pre-braking probability, and data quality. Simulations demonstrate the superiority of the proposed offloading framework.
Cell Type Identification from Single-Cell Transcriptomic Data via Semi-supervised Learning
May 06, 2020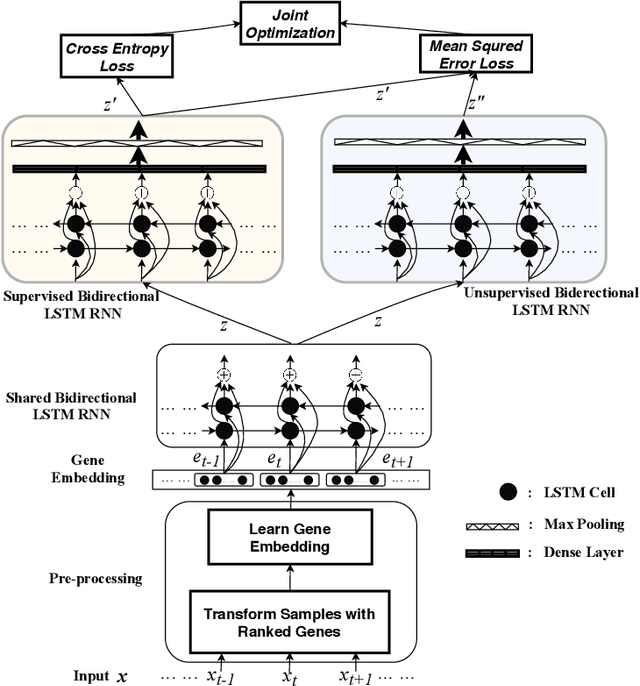

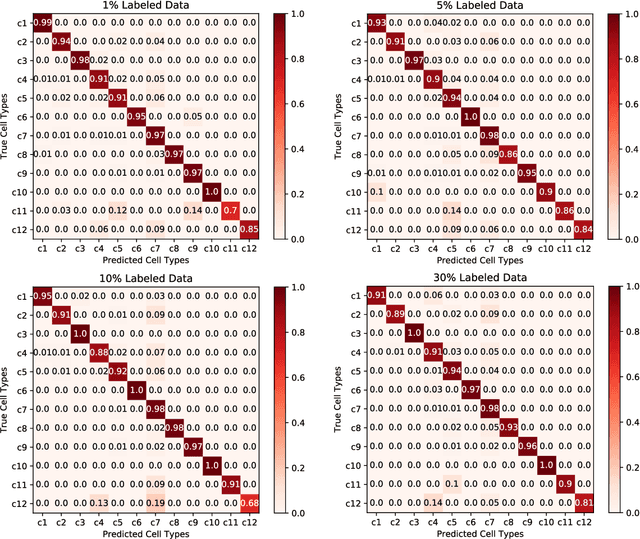

Cell type identification from single-cell transcriptomic data is a common goal of single-cell RNA sequencing (scRNAseq) data analysis. Neural networks have been employed to identify cell types from scRNAseq data with high performance. However, it requires a large mount of individual cells with accurate and unbiased annotated types to build the identification models. Unfortunately, labeling the scRNAseq data is cumbersome and time-consuming as it involves manual inspection of marker genes. To overcome this challenge, we propose a semi-supervised learning model to use unlabeled scRNAseq cells and limited amount of labeled scRNAseq cells to implement cell identification. Firstly, we transform the scRNAseq cells to "gene sentences", which is inspired by similarities between natural language system and gene system. Then genes in these sentences are represented as gene embeddings to reduce data sparsity. With these embeddings, we implement a semi-supervised learning model based on recurrent convolutional neural networks (RCNN), which includes a shared network, a supervised network and an unsupervised network. The proposed model is evaluated on macosko2015, a large scale single-cell transcriptomic dataset with ground truth of individual cell types. It is observed that the proposed model is able to achieve encouraging performance by learning on very limited amount of labeled scRNAseq cells together with a large number of unlabeled scRNAseq cells.
Device Authentication Codes based on RF Fingerprinting using Deep Learning
Apr 19, 2020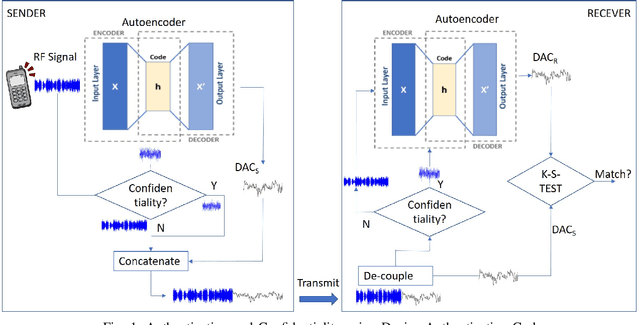
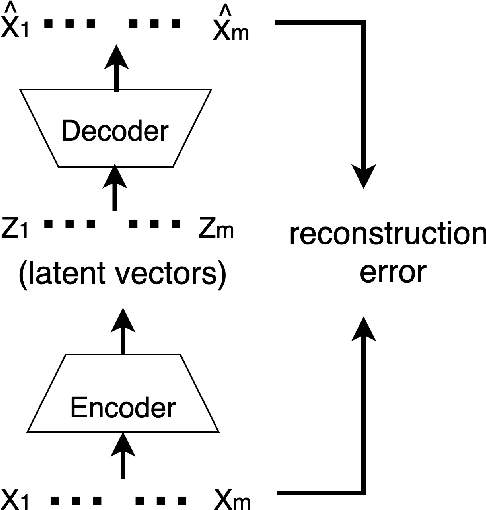
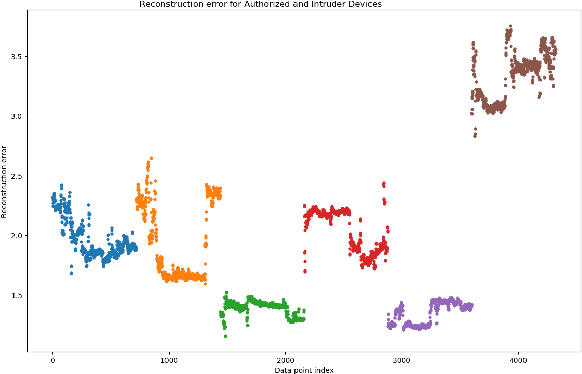
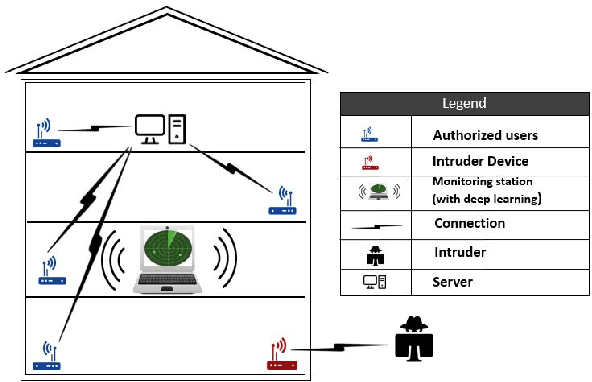
In this paper, we propose Device Authentication Code (DAC), a novel method for authenticating IoT devices with wireless interface by exploiting their radio frequency (RF) signatures. The proposed DAC is based on RF fingerprinting, information theoretic method, feature learning, and discriminatory power of deep learning. Specifically, an autoencoder is used to automatically extract features from the RF traces, and the reconstruction error is used as the DAC and this DAC is unique to the device and the particular message of interest. Then Kolmogorov-Smirnov (K-S) test is used to match the distribution of the reconstruction error generated by the autoencoder and the received message, and the result will determine whether the device of interest belongs to an authorized user. We validate this concept on two experimentally collected RF traces from six ZigBee and five universal software defined radio peripheral (USRP) devices, respectively. The traces span a range of Signalto- Noise Ratio by varying locations and mobility of the devices and channel interference and noise to ensure robustness of the model. Experimental results demonstrate that DAC is able to prevent device impersonation by extracting salient features that are unique to any wireless device of interest and can be used to identify RF devices. Furthermore, the proposed method does not need the RF traces of the intruder during model training yet be able to identify devices not seen during training, which makes it practical.