 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM Fine-tuning for Text-to-SQLs by SQL Quality Measurement
Oct 02, 2024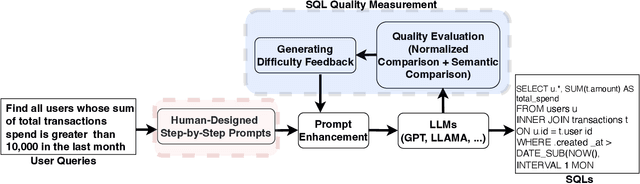
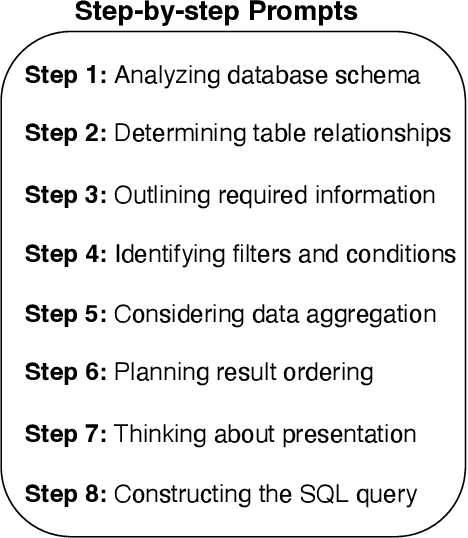
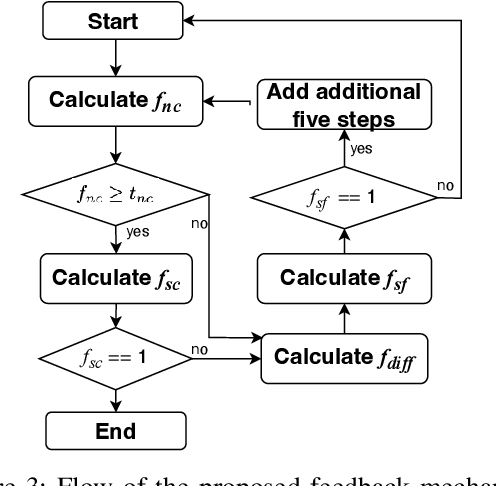
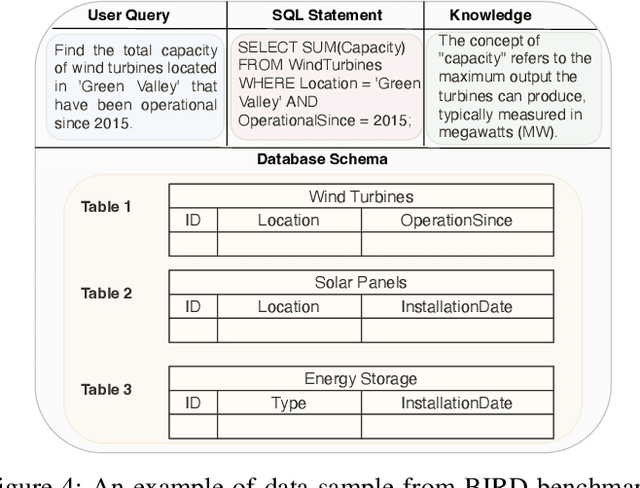
Text-to-SQLs enables non-expert users to effortlessly retrieve desired information from relational databases using natural language queries. While recent advancements, particularly with Large Language Models (LLMs) like GPT and T5, have shown impressive performance on large-scale benchmarks such as BIRD, current state-of-the-art (SOTA) LLM-based Text-to-SQLs models often require significant efforts to develop auxiliary tools like SQL classifiers to achieve high performance. This paper proposed a novel approach that only needs SQL Quality Measurement to enhance LLMs-based Text-to-SQLs performance. It establishes a SQL quality evaluation mechanism to assess the generated SQL queries against predefined criteria and actual database responses. This feedback loop enables continuous learning and refinement of model outputs based on both syntactic correctness and semantic accuracy. The proposed method undergoes comprehensive validation on the BIRD benchmark, assessing Execution Accuracy (EX) and Valid Efficiency Score (VES) across various Text-to-SQLs difficulty levels. Experimental results reveal competitive performance in both EX and VES compared to SOTA models like GPT4 and T5.
Enhancing Deep Knowledge Tracing via Diffusion Models for Personalized Adaptive Learning
Apr 25, 2024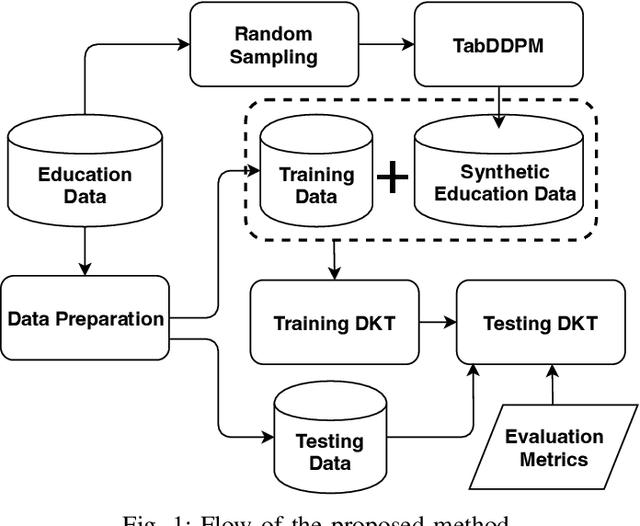
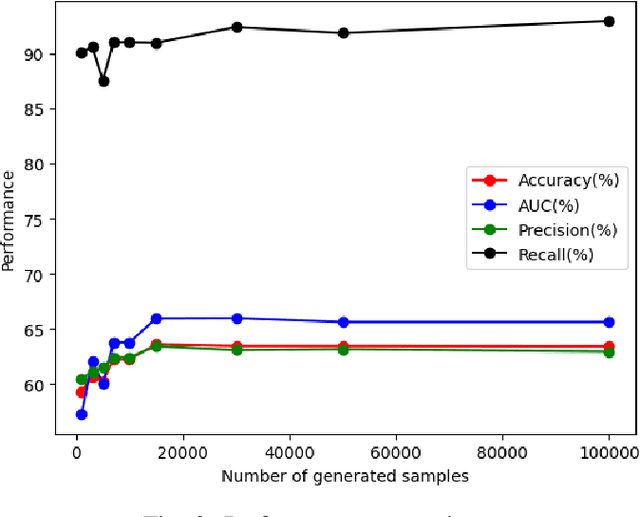
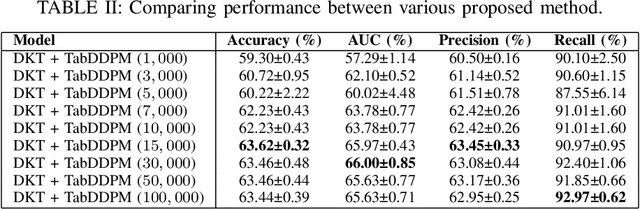
In contrast to pedagogies like evidence-based teaching, personalized adaptive learning (PAL) distinguishes itself by closely monitoring the progress of individual students and tailoring the learning path to their unique knowledge and requirements. A crucial technique for effective PAL implementation is knowledge tracing, which models students' evolving knowledge to predict their future performance. Based on these predictions, personalized recommendations for resources and learning paths can be made to meet individual needs. Recent advancements in deep learning have successfully enhanced knowledge tracking through Deep Knowledge Tracing (DKT). This paper introduces generative AI models to further enhance DKT. Generative AI models, rooted in deep learning, are trained to generate synthetic data, addressing data scarcity challenges in various applications across fields such as natural language processing (NLP) and computer vision (CV). This study aims to tackle data shortage issues in student learning records to enhance DKT performance for PAL. Specifically, it employs TabDDPM, a diffusion model, to generate synthetic educational records to augment training data for enhancing DKT. The proposed method's effectiveness is validated through extensive experiments on ASSISTments datasets. The experimental results demonstrate that the AI-generated data by TabDDPM significantly improves DKT performance, particularly in scenarios with small data for training and large data for testing.
Medical Data Augmentation via ChatGPT: A Case Study on Medication Identification and Medication Event Classification
Jun 10, 2023



The identification of key factors such as medications, diseases, and relationships within electronic health records and clinical notes has a wide range of applications in the clinical field. In the N2C2 2022 competitions, various tasks were presented to promote the identification of key factors in electronic health records (EHRs) using the Contextualized Medication Event Dataset (CMED). Pretrained large language models (LLMs) demonstrated exceptional performance in these tasks. This study aims to explore the utilization of LLMs, specifically ChatGPT, for data augmentation to overcome the limited availability of annotated data for identifying the key factors in EHRs. Additionally, different pre-trained BERT models, initially trained on extensive datasets like Wikipedia and MIMIC, were employed to develop models for identifying these key variables in EHRs through fine-tuning on augmented datasets. The experimental results of two EHR analysis tasks, namely medication identification and medication event classification, indicate that data augmentation based on ChatGPT proves beneficial in improving performance for both medication identification and medication event classification.