 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyThermal: Towards Learning Universal Representations for Thermal Perception
Feb 05, 2026We present AnyThermal, a thermal backbone that captures robust task-agnostic thermal features suitable for a variety of tasks such as cross-modal place recognition, thermal segmentation, and monocular depth estimation using thermal images. Existing thermal backbones that follow task-specific training from small-scale data result in utility limited to a specific environment and task. Unlike prior methods, AnyThermal can be used for a wide range of environments (indoor, aerial, off-road, urban) and tasks, all without task-specific training. Our key insight is to distill the feature representations from visual foundation models such as DINOv2 into a thermal encoder using thermal data from these multiple environments. To bridge the diversity gap of the existing RGB-Thermal datasets, we introduce the TartanRGBT platform, the first open-source data collection platform with synced RGB-Thermal image acquisition. We use this payload to collect the TartanRGBT dataset - a diverse and balanced dataset collected in 4 environments. We demonstrate the efficacy of AnyThermal and TartanRGBT, achieving state-of-the-art results with improvements of up to 36% across diverse environments and downstream tasks on existing datasets.
ThermalDiffusion: Visual-to-Thermal Image-to-Image Translation for Autonomous Navigation
Jun 26, 2025Autonomous systems rely on sensors to estimate the environment around them. However, cameras, LiDARs, and RADARs have their own limitations. In nighttime or degraded environments such as fog, mist, or dust, thermal cameras can provide valuable information regarding the presence of objects of interest due to their heat signature. They make it easy to identify humans and vehicles that are usually at higher temperatures compared to their surroundings. In this paper, we focus on the adaptation of thermal cameras for robotics and automation, where the biggest hurdle is the lack of data. Several multi-modal datasets are available for driving robotics research in tasks such as scene segmentation, object detection, and depth estimation, which are the cornerstone of autonomous systems. However, they are found to be lacking in thermal imagery. Our paper proposes a solution to augment these datasets with synthetic thermal data to enable widespread and rapid adaptation of thermal cameras. We explore the use of conditional diffusion models to convert existing RGB images to thermal images using self-attention to learn the thermal properties of real-world objects.
UFM: A Simple Path towards Unified Dense Correspondence with Flow
Jun 10, 2025Dense image correspondence is central to many applications, such as visual odometry, 3D reconstruction, object association, and re-identification. Historically, dense correspondence has been tackled separately for wide-baseline scenarios and optical flow estimation, despite the common goal of matching content between two images. In this paper, we develop a Unified Flow & Matching model (UFM), which is trained on unified data for pixels that are co-visible in both source and target images. UFM uses a simple, generic transformer architecture that directly regresses the (u,v) flow. It is easier to train and more accurate for large flows compared to the typical coarse-to-fine cost volumes in prior work. UFM is 28% more accurate than state-of-the-art flow methods (Unimatch), while also having 62% less error and 6.7x faster than dense wide-baseline matchers (RoMa). UFM is the first to demonstrate that unified training can outperform specialized approaches across both domains. This result enables fast, general-purpose correspondence and opens new directions for multi-modal, long-range, and real-time correspondence tasks.
TartanGround: A Large-Scale Dataset for Ground Robot Perception and Navigation
May 15, 2025We present TartanGround, a large-scale, multi-modal dataset to advance the perception and autonomy of ground robots operating in diverse environments. This dataset, collected in various photorealistic simulation environments includes multiple RGB stereo cameras for 360-degree coverage, along with depth, optical flow, stereo disparity, LiDAR point clouds, ground truth poses, semantic segmented images, and occupancy maps with semantic labels. Data is collected using an integrated automatic pipeline, which generates trajectories mimicking the motion patterns of various ground robot platforms, including wheeled and legged robots. We collect 910 trajectories across 70 environments, resulting in 1.5 million samples. Evaluations on occupancy prediction and SLAM tasks reveal that state-of-the-art methods trained on existing datasets struggle to generalize across diverse scenes. TartanGround can serve as a testbed for training and evaluation of a broad range of learning-based tasks, including occupancy prediction, SLAM, neural scene representation, perception-based navigation, and more, enabling advancements in robotic perception and autonomy towards achieving robust models generalizable to more diverse scenarios. The dataset and codebase for data collection will be made publicly available upon acceptance. Webpage: https://tartanair.org/tartanground
STRIVE: Structured Representation Integrating VLM Reasoning for Efficient Object Navigation
May 10, 2025



Vision-Language Models (VLMs) have been increasingly integrated into object navigation tasks for their rich prior knowledge and strong reasoning abilities. However, applying VLMs to navigation poses two key challenges: effectively representing complex environment information and determining \textit{when and how} to query VLMs. Insufficient environment understanding and over-reliance on VLMs (e.g. querying at every step) can lead to unnecessary backtracking and reduced navigation efficiency, especially in continuous environments. To address these challenges, we propose a novel framework that constructs a multi-layer representation of the environment during navigation. This representation consists of viewpoint, object nodes, and room nodes. Viewpoints and object nodes facilitate intra-room exploration and accurate target localization, while room nodes support efficient inter-room planning. Building on this representation, we propose a novel two-stage navigation policy, integrating high-level planning guided by VLM reasoning with low-level VLM-assisted exploration to efficiently locate a goal object. We evaluated our approach on three simulated benchmarks (HM3D, RoboTHOR, and MP3D), and achieved state-of-the-art performance on both the success rate ($\mathord{\uparrow}\, 7.1\%$) and navigation efficiency ($\mathord{\uparrow}\, 12.5\%$). We further validate our method on a real robot platform, demonstrating strong robustness across 15 object navigation tasks in 10 different indoor environments. Project page is available at https://zwandering.github.io/STRIVE.github.io/ .
SORT3D: Spatial Object-centric Reasoning Toolbox for Zero-Shot 3D Grounding Using Large Language Models
Apr 25, 2025Interpreting object-referential language and grounding objects in 3D with spatial relations and attributes is essential for robots operating alongside humans. However, this task is often challenging due to the diversity of scenes, large number of fine-grained objects, and complex free-form nature of language references. Furthermore, in the 3D domain, obtaining large amounts of natural language training data is difficult. Thus, it is important for methods to learn from little data and zero-shot generalize to new environments. To address these challenges, we propose SORT3D, an approach that utilizes rich object attributes from 2D data and merges a heuristics-based spatial reasoning toolbox with the ability of large language models (LLMs) to perform sequential reasoning. Importantly, our method does not require text-to-3D data for training and can be applied zero-shot to unseen environments. We show that SORT3D achieves state-of-the-art performance on complex view-dependent grounding tasks on two benchmarks. We also implement the pipeline to run real-time on an autonomous vehicle and demonstrate that our approach can be used for object-goal navigation on previously unseen real-world environments. All source code for the system pipeline is publicly released at https://github.com/nzantout/SORT3D .
RayFronts: Open-Set Semantic Ray Frontiers for Online Scene Understanding and Exploration
Apr 09, 2025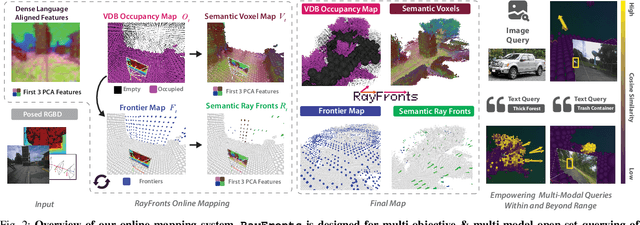
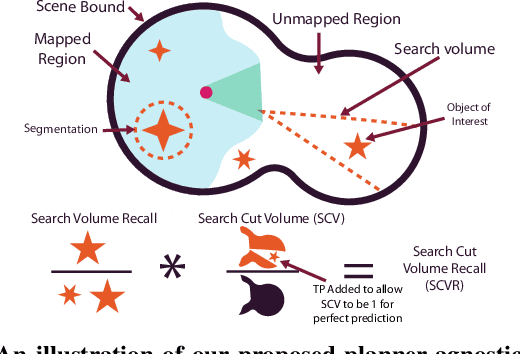
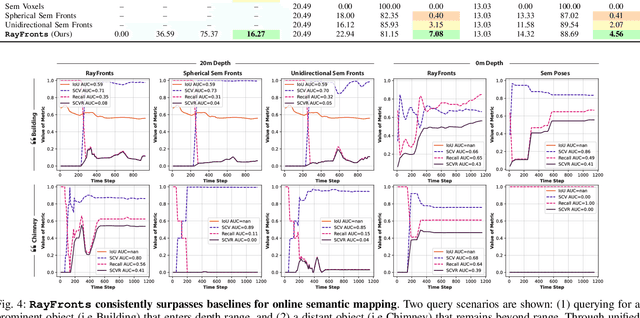
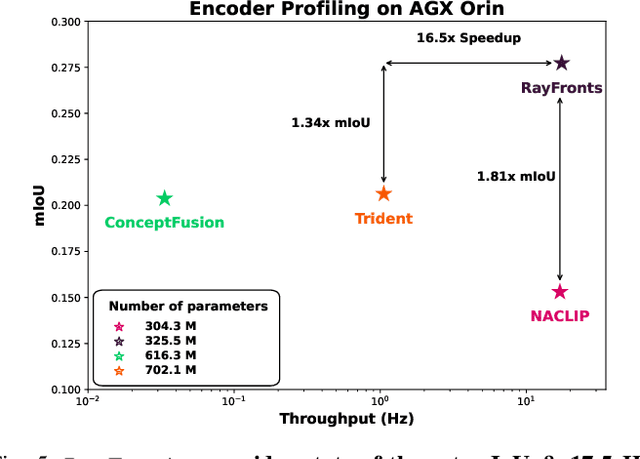
Open-set semantic mapping is crucial for open-world robots. Current mapping approaches either are limited by the depth range or only map beyond-range entities in constrained settings, where overall they fail to combine within-range and beyond-range observations. Furthermore, these methods make a trade-off between fine-grained semantics and efficiency. We introduce RayFronts, a unified representation that enables both dense and beyond-range efficient semantic mapping. RayFronts encodes task-agnostic open-set semantics to both in-range voxels and beyond-range rays encoded at map boundaries, empowering the robot to reduce search volumes significantly and make informed decisions both within & beyond sensory range, while running at 8.84 Hz on an Orin AGX. Benchmarking the within-range semantics shows that RayFronts's fine-grained image encoding provides 1.34x zero-shot 3D semantic segmentation performance while improving throughput by 16.5x. Traditionally, online mapping performance is entangled with other system components, complicating evaluation. We propose a planner-agnostic evaluation framework that captures the utility for online beyond-range search and exploration, and show RayFronts reduces search volume 2.2x more efficiently than the closest online baselines.
TrustRAG: An Information Assistant with Retrieval Augmented Generation
Feb 19, 2025\Ac{RAG} has emerged as a crucial technique for enhancing large models with real-time and domain-specific knowledge. While numerous improvements and open-source tools have been proposed to refine the \ac{RAG} framework for accuracy, relatively little attention has been given to improving the trustworthiness of generated results. To address this gap, we introduce TrustRAG, a novel framework that enhances \ac{RAG} from three perspectives: indexing, retrieval, and generation. Specifically, in the indexing stage, we propose a semantic-enhanced chunking strategy that incorporates hierarchical indexing to supplement each chunk with contextual information, ensuring semantic completeness. In the retrieval stage, we introduce a utility-based filtering mechanism to identify high-quality information, supporting answer generation while reducing input length. In the generation stage, we propose fine-grained citation enhancement, which detects opinion-bearing sentences in responses and infers citation relationships at the sentence-level, thereby improving citation accuracy. We open-source the TrustRAG framework and provide a demonstration studio designed for excerpt-based question answering tasks \footnote{https://huggingface.co/spaces/golaxy/TrustRAG}. Based on these, we aim to help researchers: 1) systematically enhancing the trustworthiness of \ac{RAG} systems and (2) developing their own \ac{RAG} systems with more reliable outputs.
HEC-GCN: Hypergraph Enhanced Cascading Graph Convolution Network for Multi-Behavior Recommendation
Dec 19, 2024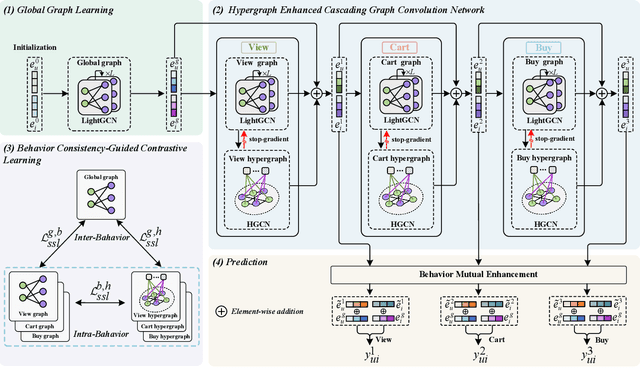
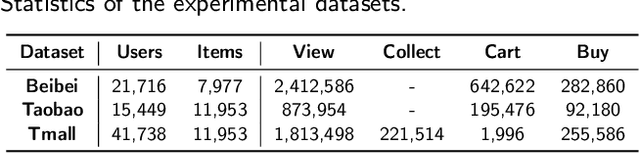
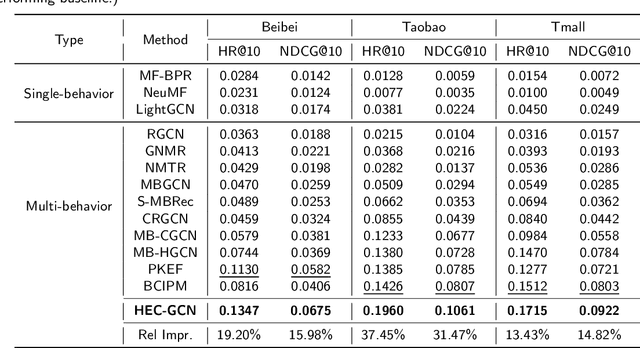
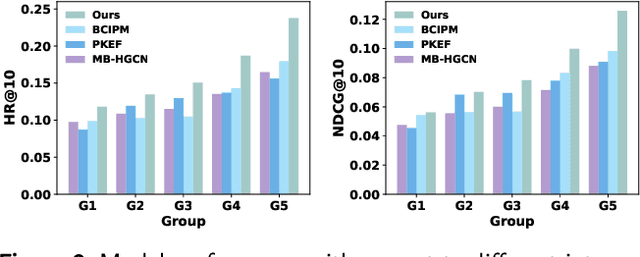
Multi-behavior recommendation (MBR) has garnered growing attention recently due to its ability to mitigate the sparsity issue by inferring user preferences from various auxiliary behaviors to improve predictions for the target behavior. Although existing research on MBR has yielded impressive results, they still face two major limitations. First, previous methods mainly focus on modeling fine-grained interaction information between users and items under each behavior, which may suffer from sparsity issue. Second, existing models usually concentrate on exploiting dependencies between two consecutive behaviors, leaving intra- and inter-behavior consistency largely unexplored. To the end, we propose a novel approach named Hypergraph Enhanced Cascading Graph Convolution Network for multi-behavior recommendation (HEC-GCN). To be specific, we first explore both fine- and coarse-grained correlations among users or items of each behavior by simultaneously modeling the behavior-specific interaction graph and its corresponding hypergraph in a cascaded manner. Then, we propose a behavior consistency-guided alignment strategy that ensures consistent representations between the interaction graph and its associated hypergraph for each behavior, while also maintaining representation consistency across different behaviors. Extensive experiments and analyses on three public benchmark datasets demonstrate that our proposed approach is consistently superior to previous state-of-the-art methods due to its capability to effectively attenuate the sparsity issue as well as preserve both intra- and inter-behavior consistencies. The code is available at https://github.com/marqu22/HEC-GCN.git.
SALON: Self-supervised Adaptive Learning for Off-road Navigation
Dec 10, 2024



Autonomous robot navigation in off-road environments presents a number of challenges due to its lack of structure, making it difficult to handcraft robust heuristics for diverse scenarios. While learned methods using hand labels or self-supervised data improve generalizability, they often require a tremendous amount of data and can be vulnerable to domain shifts. To improve generalization in novel environments, recent works have incorporated adaptation and self-supervision to develop autonomous systems that can learn from their own experiences online. However, current works often rely on significant prior data, for example minutes of human teleoperation data for each terrain type, which is difficult to scale with more environments and robots. To address these limitations, we propose SALON, a perception-action framework for fast adaptation of traversability estimates with minimal human input. SALON rapidly learns online from experience while avoiding out of distribution terrains to produce adaptive and risk-aware cost and speed maps. Within seconds of collected experience, our results demonstrate comparable navigation performance over kilometer-scale courses in diverse off-road terrain as methods trained on 100-1000x more data. We additionally show promising results on significantly different robots in different environments. Our code is available at https://theairlab.org/SALON.