 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctional Force-Aware Retargeting from Virtual Human Demos to Soft Robot Policies
Apr 01, 2026We introduce SoftAct, a framework for teaching soft robot hands to perform human-like manipulation skills by explicitly reasoning about contact forces. Leveraging immersive virtual reality, our system captures rich human demonstrations, including hand kinematics, object motion, dense contact patches, and detailed contact force information. Unlike conventional approaches that retarget human joint trajectories, SoftAct employs a two-stage, force-aware retargeting algorithm. The first stage attributes demonstrated contact forces to individual human fingers and allocates robot fingers proportionally, establishing a force-balanced mapping between human and robot hands. The second stage performs online retargeting by combining baseline end-effector pose tracking with geodesic-weighted contact refinements, using contact geometry and force magnitude to adjust robot fingertip targets in real time. This formulation enables soft robotic hands to reproduce the functional intent of human demonstrations while naturally accommodating extreme embodiment mismatch and nonlinear compliance. We evaluate SoftAct on a suite of contact-rich manipulation tasks using a custom non-anthropomorphic pneumatic soft robot hand. SoftAct's controller reduces fingertip trajectory tracking RMSE by up to 55 percent and reduces tracking variance by up to 69 percent compared to kinematic and learning-based baselines. At the policy level, SoftAct achieves consistently higher success in zero-shot real-world deployment and in simulation. These results demonstrate that explicitly modeling contact geometry and force distribution is essential for effective skill transfer to soft robotic hands, and cannot be recovered through kinematic imitation alone. Project videos and additional details are available at https://soft-act.github.io/.
TokenDial: Continuous Attribute Control in Text-to-Video via Spatiotemporal Token Offsets
Mar 29, 2026We present TokenDial, a framework for continuous, slider-style attribute control in pretrained text-to-video generation models. While modern generators produce strong holistic videos, they offer limited control over how much an attribute changes (e.g., effect intensity or motion magnitude) without drifting identity, background, or temporal coherence. TokenDial is built on the observation: additive offsets in the intermediate spatiotemporal visual patch-token space form a semantic control direction, where adjusting the offset magnitude yields coherent, predictable edits for both appearance and motion dynamics. We learn attribute-specific token offsets without retraining the backbone, using pretrained understanding signals: semantic direction matching for appearance and motion-magnitude scaling for motion. We demonstrate TokenDial's effectiveness on diverse attributes and prompts, achieving stronger controllability and higher-quality edits than state-of-the-art baselines, supported by extensive quantitative evaluation and human studies.
SOFTMAP: Sim2Real Soft Robot Forward Modeling via Topological Mesh Alignment and Physics Prior
Mar 19, 2026While soft robot manipulators offer compelling advantages over rigid counterparts, including inherent compliance, safe human-robot interaction, and the ability to conform to complex geometries, accurate forward modeling from low-dimensional actuation commands remains an open challenge due to nonlinear material phenomena such as hysteresis and manufacturing variability. We present SOFTMAP, a sim-to-real learning framework for real-time 3D forward modeling of tendon-actuated soft finger manipulators. SOFTMAP combines four components: (1) As-Rigid-As-Possible (ARAP)-based topological alignment that projects simulated and real point clouds into a shared, topologically consistent vertex space; (2) a lightweight MLP forward model pretrained on simulation data to map servo commands to full 3D finger geometry; (3) a residual correction network trained on a small set of real observations to predict per-vertex displacement fields that compensate for sim-to-real discrepancies; and (4) a closed-form linear actuation calibration layer enabling real-time inference at 30 FPS. We evaluate SOFTMAP on both simulated and physical hardware, achieving state-of-the-art shape prediction accuracy with a Chamfer distance of 0.389 mm in simulation and 3.786 mm on hardware, millimeter-level fingertip trajectory tracking across multiple target paths, and a 36.5% improvement in teleoperation task success over the baseline. Our results show that SOFTMAP provides a data-efficient approach for 3D forward modeling and control of soft manipulators.
Evaluating Demographic Misrepresentation in Image-to-Image Portrait Editing
Feb 18, 2026Demographic bias in text-to-image (T2I) generation is well studied, yet demographic-conditioned failures in instruction-guided image-to-image (I2I) editing remain underexplored. We examine whether identical edit instructions yield systematically different outcomes across subject demographics in open-weight I2I editors. We formalize two failure modes: Soft Erasure, where edits are silently weakened or ignored in the output image, and Stereotype Replacement, where edits introduce unrequested, stereotype-consistent attributes. We introduce a controlled benchmark that probes demographic-conditioned behavior by generating and editing portraits conditioned on race, gender, and age using a diagnostic prompt set, and evaluate multiple editors with vision-language model (VLM) scoring and human evaluation. Our analysis shows that identity preservation failures are pervasive, demographically uneven, and shaped by implicit social priors, including occupation-driven gender inference. Finally, we demonstrate that a prompt-level identity constraint, without model updates, can substantially reduce demographic change for minority groups while leaving majority-group portraits largely unchanged, revealing asymmetric identity priors in current editors. Together, our findings establish identity preservation as a central and demographically uneven failure mode in I2I editing and motivate demographic-robust editing systems. Project page: https://seochan99.github.io/i2i-demographic-bias
InterPReT: Interactive Policy Restructuring and Training Enable Effective Imitation Learning from Laypersons
Feb 04, 2026Imitation learning has shown success in many tasks by learning from expert demonstrations. However, most existing work relies on large-scale demonstrations from technical professionals and close monitoring of the training process. These are challenging for a layperson when they want to teach the agent new skills. To lower the barrier of teaching AI agents, we propose Interactive Policy Restructuring and Training (InterPReT), which takes user instructions to continually update the policy structure and optimize its parameters to fit user demonstrations. This enables end-users to interactively give instructions and demonstrations, monitor the agent's performance, and review the agent's decision-making strategies. A user study (N=34) on teaching an AI agent to drive in a racing game confirms that our approach yields more robust policies without impairing system usability, compared to a generic imitation learning baseline, when a layperson is responsible for both giving demonstrations and determining when to stop. This shows that our method is more suitable for end-users without much technical background in machine learning to train a dependable policy
LongComp: Long-Tail Compositional Zero-Shot Generalization for Robust Trajectory Prediction
Nov 13, 2025Methods for trajectory prediction in Autonomous Driving must contend with rare, safety-critical scenarios that make reliance on real-world data collection alone infeasible. To assess robustness under such conditions, we propose new long-tail evaluation settings that repartition datasets to create challenging out-of-distribution (OOD) test sets. We first introduce a safety-informed scenario factorization framework, which disentangles scenarios into discrete ego and social contexts. Building on analogies to compositional zero-shot image-labeling in Computer Vision, we then hold out novel context combinations to construct challenging closed-world and open-world settings. This process induces OOD performance gaps in future motion prediction of 5.0% and 14.7% in closed-world and open-world settings, respectively, relative to in-distribution performance for a state-of-the-art baseline. To improve generalization, we extend task-modular gating networks to operate within trajectory prediction models, and develop an auxiliary, difficulty-prediction head to refine internal representations. Our strategies jointly reduce the OOD performance gaps to 2.8% and 11.5% in the two settings, respectively, while still improving in-distribution performance.
Geodesic Tracing-Based Kinematic Integration of Rolling and Sliding Contact on Manifold Meshes for Dexterous In-Hand Manipulation
Aug 17, 2025
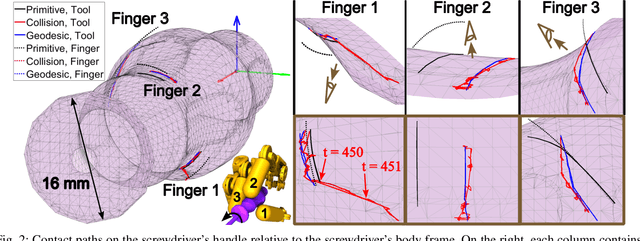

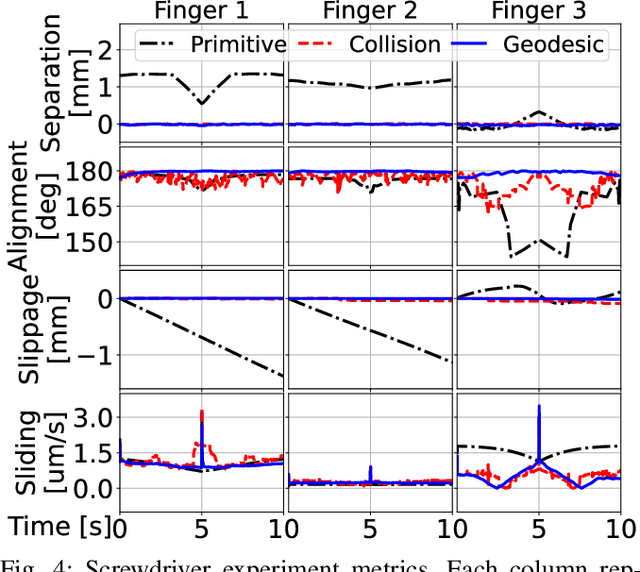
Reasoning about rolling and sliding contact, or roll-slide contact for short, is critical for dexterous manipulation tasks that involve intricate geometries. But existing works on roll-slide contact mostly focus on continuous shapes with differentiable parametrizations. This work extends roll-slide contact modeling to manifold meshes. Specifically, we present an integration scheme based on geodesic tracing to first-order time-integrate roll-slide contact directly on meshes, enabling dexterous manipulation to reason over high-fidelity discrete representations of an object's true geometry. Using our method, we planned dexterous motions of a multi-finger robotic hand manipulating five objects in-hand in simulation. The planning was achieved with a least-squares optimizer that strives to maintain the most stable instantaneous grasp by minimizing contact sliding and spinning. Then, we evaluated our method against a baseline using collision detection and a baseline using primitive shapes. The results show that our method performed the best in accuracy and precision, even for coarse meshes. We conclude with a future work discussion on incorporating multiple contacts and contact forces to achieve accurate and robust mesh-based surface contact modeling.
STRIVE: Structured Representation Integrating VLM Reasoning for Efficient Object Navigation
May 10, 2025



Vision-Language Models (VLMs) have been increasingly integrated into object navigation tasks for their rich prior knowledge and strong reasoning abilities. However, applying VLMs to navigation poses two key challenges: effectively representing complex environment information and determining \textit{when and how} to query VLMs. Insufficient environment understanding and over-reliance on VLMs (e.g. querying at every step) can lead to unnecessary backtracking and reduced navigation efficiency, especially in continuous environments. To address these challenges, we propose a novel framework that constructs a multi-layer representation of the environment during navigation. This representation consists of viewpoint, object nodes, and room nodes. Viewpoints and object nodes facilitate intra-room exploration and accurate target localization, while room nodes support efficient inter-room planning. Building on this representation, we propose a novel two-stage navigation policy, integrating high-level planning guided by VLM reasoning with low-level VLM-assisted exploration to efficiently locate a goal object. We evaluated our approach on three simulated benchmarks (HM3D, RoboTHOR, and MP3D), and achieved state-of-the-art performance on both the success rate ($\mathord{\uparrow}\, 7.1\%$) and navigation efficiency ($\mathord{\uparrow}\, 12.5\%$). We further validate our method on a real robot platform, demonstrating strong robustness across 15 object navigation tasks in 10 different indoor environments. Project page is available at https://zwandering.github.io/STRIVE.github.io/ .
MOSAIC: Generating Consistent, Privacy-Preserving Scenes from Multiple Depth Views in Multi-Room Environments
Mar 18, 2025We introduce a novel diffusion-based approach for generating privacy-preserving digital twins of multi-room indoor environments from depth images only. Central to our approach is a novel Multi-view Overlapped Scene Alignment with Implicit Consistency (MOSAIC) model that explicitly considers cross-view dependencies within the same scene in the probabilistic sense. MOSAIC operates through a novel inference-time optimization that avoids error accumulation common in sequential or single-room constraint in panorama-based approaches. MOSAIC scales to complex scenes with zero extra training and provably reduces the variance during denoising processes when more overlapping views are added, leading to improved generation quality. Experiments show that MOSAIC outperforms state-of-the-art baselines on image fidelity metrics in reconstructing complex multi-room environments. Project page is available at: https://mosaic-cmubig.github.io
ShapeShift: Towards Text-to-Shape Arrangement Synthesis with Content-Aware Geometric Constraints
Mar 18, 2025



While diffusion-based models excel at generating photorealistic images from text, a more nuanced challenge emerges when constrained to using only a fixed set of rigid shapes, akin to solving tangram puzzles or arranging real-world objects to match semantic descriptions. We formalize this problem as shape-based image generation, a new text-guided image-to-image translation task that requires rearranging the input set of rigid shapes into non-overlapping configurations and visually communicating the target concept. Unlike pixel-manipulation approaches, our method, ShapeShift, explicitly parameterizes each shape within a differentiable vector graphics pipeline, iteratively optimizing placement and orientation through score distillation sampling from pretrained diffusion models. To preserve arrangement clarity, we introduce a content-aware collision resolution mechanism that applies minimal semantically coherent adjustments when overlaps occur, ensuring smooth convergence toward physically valid configurations. By bridging diffusion-based semantic guidance with explicit geometric constraints, our approach yields interpretable compositions where spatial relationships clearly embody the textual prompt. Extensive experiments demonstrate compelling results across diverse scenarios, with quantitative and qualitative advantages over alternative techniques.