 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpline-FRIDA: Towards Diverse, Humanlike Robot Painting Styles with a Sample-Efficient, Differentiable Brush Stroke Model
Nov 30, 2024A painting is more than just a picture on a wall; a painting is a process comprised of many intentional brush strokes, the shapes of which are an important component of a painting's overall style and message. Prior work in modeling brush stroke trajectories either does not work with real-world robotics or is not flexible enough to capture the complexity of human-made brush strokes. In this work, we introduce Spline-FRIDA which can model complex human brush stroke trajectories. This is achieved by recording artists drawing using motion capture, modeling the extracted trajectories with an autoencoder, and introducing a novel brush stroke dynamics model to the existing robotic painting platform FRIDA. We conducted a survey and found that our open-source Spline-FRIDA approach successfully captures the stroke styles in human drawings and that Spline-FRIDA's brush strokes are more human-like, improve semantic planning, and are more artistic compared to existing robot painting systems with restrictive B\'ezier curve strokes.
Learning Robot Skills with Temporal Variational Inference
Jun 29, 2020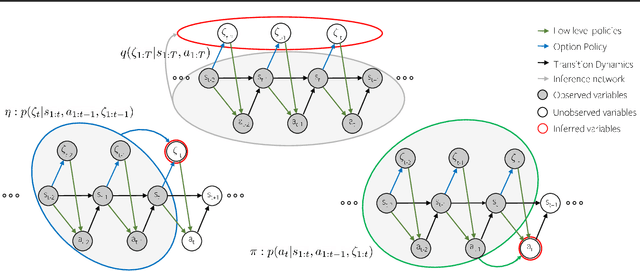

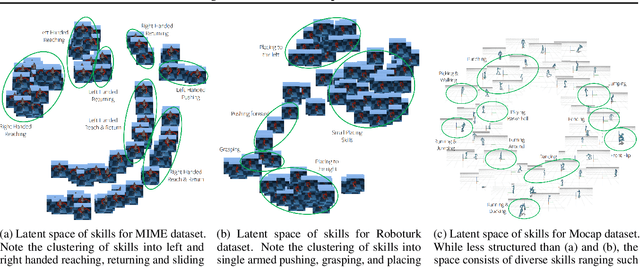

In this paper, we address the discovery of robotic options from demonstrations in an unsupervised manner. Specifically, we present a framework to jointly learn low-level control policies and higher-level policies of how to use them from demonstrations of a robot performing various tasks. By representing options as continuous latent variables, we frame the problem of learning these options as latent variable inference. We then present a temporal formulation of variational inference based on a temporal factorization of trajectory likelihoods,that allows us to infer options in an unsupervised manner. We demonstrate the ability of our framework to learn such options across three robotic demonstration datasets.
Learning Neural Parsers with Deterministic Differentiable Imitation Learning
Sep 19, 2018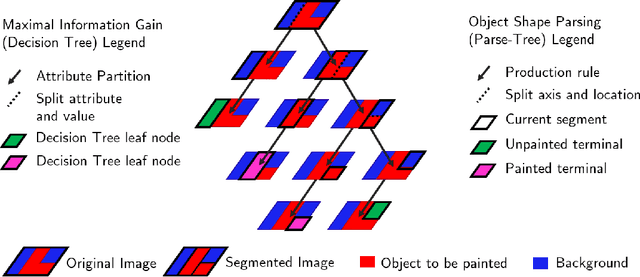


We explore the problem of learning to decompose spatial tasks into segments, as exemplified by the problem of a painting robot covering a large object. Inspired by the ability of classical decision tree algorithms to construct structured partitions of their input spaces, we formulate the problem of decomposing objects into segments as a parsing approach. We make the insight that the derivation of a parse-tree that decomposes the object into segments closely resembles a decision tree constructed by ID3, which can be done when the ground-truth available. We learn to imitate an expert parsing oracle, such that our neural parser can generalize to parse natural images without ground truth. We introduce a novel deterministic policy gradient update, DRAG (i.e., DeteRministically AGgrevate) in the form of a deterministic actor-critic variant of AggreVaTeD, to train our neural parser. From another perspective, our approach is a variant of the Deterministic Policy Gradient suitable for the imitation learning setting. The deterministic policy representation offered by training our neural parser with DRAG allows it to outperform state of the art imitation and reinforcement learning approaches.
Learning to Sequence Robot Behaviors for Visual Navigation
Mar 26, 2018

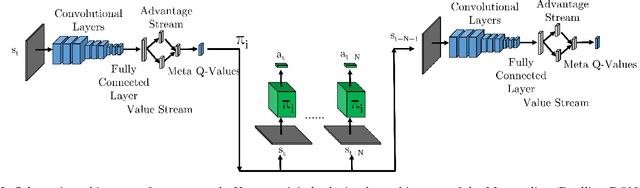

Recent literature in the robotics community has focused on learning robot behaviors that abstract out lower-level details of robot control. To fully leverage the efficacy of such behaviors, it is necessary to select and sequence them to achieve a given task. In this paper, we present an approach to both learn and sequence robot behaviors, applied to the problem of visual navigation of mobile robots. We construct a layered representation of control policies composed of low- level behaviors and a meta-level policy. The low-level behaviors enable the robot to locomote in a particular environment while avoiding obstacles, and the meta-level policy actively selects the low-level behavior most appropriate for the current situation based purely on visual feedback. We demonstrate the effectiveness of our method on three simulated robot navigation tasks: a legged hexapod robot which must successfully traverse varying terrain, a wheeled robot which must navigate a maze-like course while avoiding obstacles, and finally a wheeled robot navigating in the presence of dynamic obstacles. We show that by learning control policies in a layered manner, we gain the ability to successfully traverse new compound environments composed of distinct sub-environments, and outperform both the low-level behaviors in their respective sub-environments, as well as a hand-crafted selection of low-level policies on these compound environments.
Reinforcement Learning via Recurrent Convolutional Neural Networks
Jan 09, 2017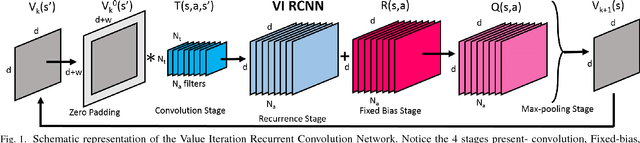
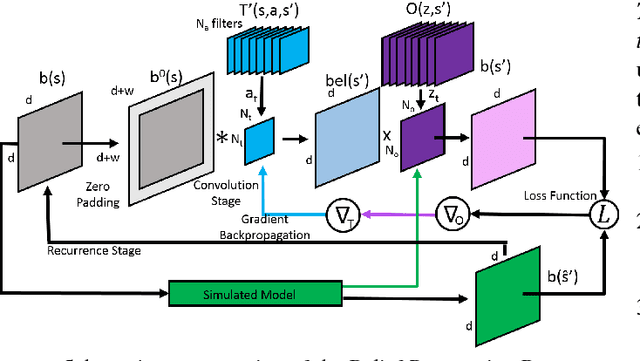
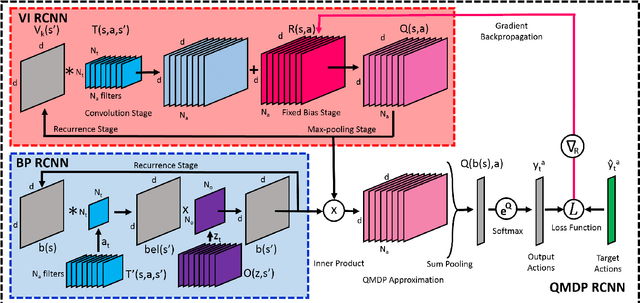
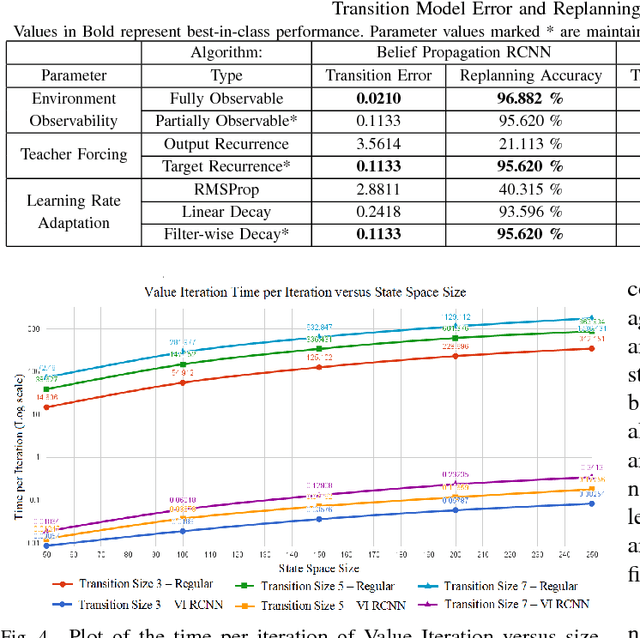
Deep Reinforcement Learning has enabled the learning of policies for complex tasks in partially observable environments, without explicitly learning the underlying model of the tasks. While such model-free methods achieve considerable performance, they often ignore the structure of task. We present a natural representation of to Reinforcement Learning (RL) problems using Recurrent Convolutional Neural Networks (RCNNs), to better exploit this inherent structure. We define 3 such RCNNs, whose forward passes execute an efficient Value Iteration, propagate beliefs of state in partially observable environments, and choose optimal actions respectively. Backpropagating gradients through these RCNNs allows the system to explicitly learn the Transition Model and Reward Function associated with the underlying MDP, serving as an elegant alternative to classical model-based RL. We evaluate the proposed algorithms in simulation, considering a robot planning problem. We demonstrate the capability of our framework to reduce the cost of replanning, learn accurate MDP models, and finally re-plan with learnt models to achieve near-optimal policies.