 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
The Journey, Not the Destination: How Data Guides Diffusion Models
Dec 11, 2023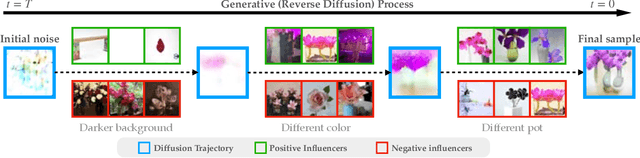
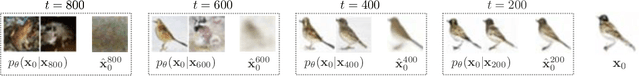

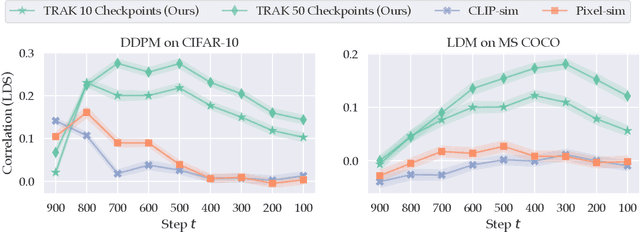
Diffusion models trained on large datasets can synthesize photo-realistic images of remarkable quality and diversity. However, attributing these images back to the training data-that is, identifying specific training examples which caused an image to be generated-remains a challenge. In this paper, we propose a framework that: (i) provides a formal notion of data attribution in the context of diffusion models, and (ii) allows us to counterfactually validate such attributions. Then, we provide a method for computing these attributions efficiently. Finally, we apply our method to find (and evaluate) such attributions for denoising diffusion probabilistic models trained on CIFAR-10 and latent diffusion models trained on MS COCO. We provide code at https://github.com/MadryLab/journey-TRAK .
OrthoNets: Orthogonal Channel Attention Networks
Nov 07, 2023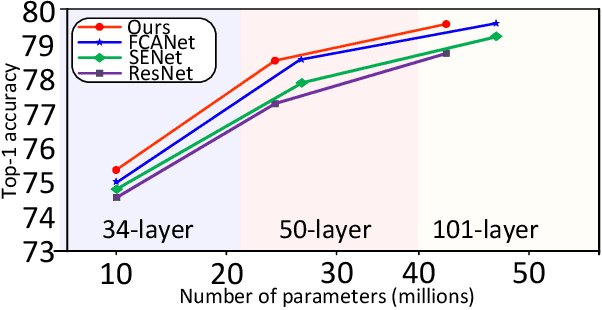
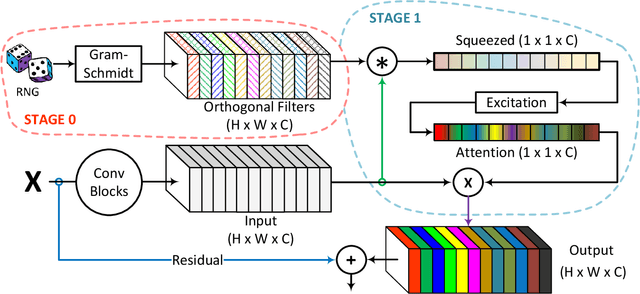
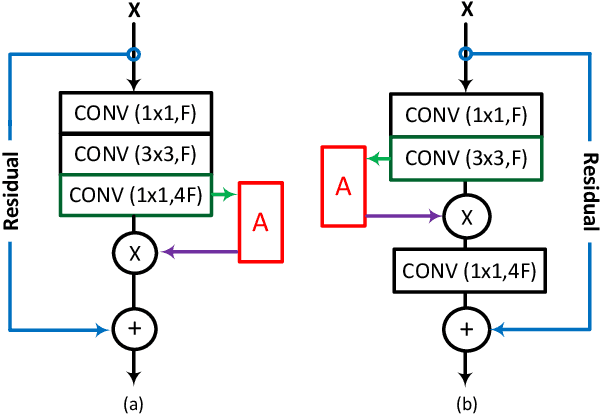
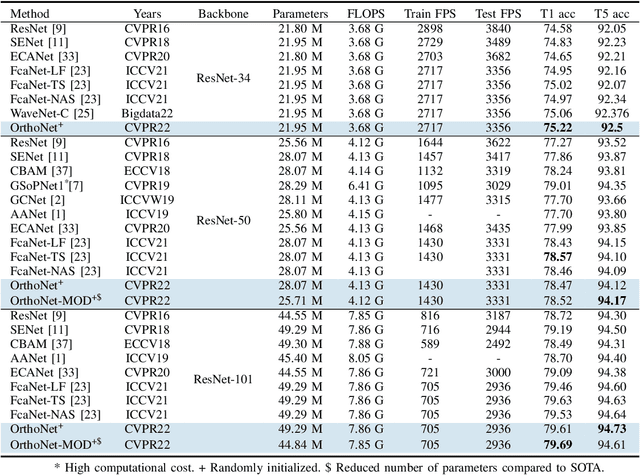
Designing an effective channel attention mechanism implores one to find a lossy-compression method allowing for optimal feature representation. Despite recent progress in the area, it remains an open problem. FcaNet, the current state-of-the-art channel attention mechanism, attempted to find such an information-rich compression using Discrete Cosine Transforms (DCTs). One drawback of FcaNet is that there is no natural choice of the DCT frequencies. To circumvent this issue, FcaNet experimented on ImageNet to find optimal frequencies. We hypothesize that the choice of frequency plays only a supporting role and the primary driving force for the effectiveness of their attention filters is the orthogonality of the DCT kernels. To test this hypothesis, we construct an attention mechanism using randomly initialized orthogonal filters. Integrating this mechanism into ResNet, we create OrthoNet. We compare OrthoNet to FcaNet (and other attention mechanisms) on Birds, MS-COCO, and Places356 and show superior performance. On the ImageNet dataset, our method competes with or surpasses the current state-of-the-art. Our results imply that an optimal choice of filter is elusive and generalization can be achieved with a sufficiently large number of orthogonal filters. We further investigate other general principles for implementing channel attention, such as its position in the network and channel groupings. Our code is publicly available at https://github.com/hady1011/OrthoNets/
* IEEE BigData 2023
Rethinking Backdoor Attacks
Jul 19, 2023



In a backdoor attack, an adversary inserts maliciously constructed backdoor examples into a training set to make the resulting model vulnerable to manipulation. Defending against such attacks typically involves viewing these inserted examples as outliers in the training set and using techniques from robust statistics to detect and remove them. In this work, we present a different approach to the backdoor attack problem. Specifically, we show that without structural information about the training data distribution, backdoor attacks are indistinguishable from naturally-occurring features in the data--and thus impossible to "detect" in a general sense. Then, guided by this observation, we revisit existing defenses against backdoor attacks and characterize the (often latent) assumptions they make and on which they depend. Finally, we explore an alternative perspective on backdoor attacks: one that assumes these attacks correspond to the strongest feature in the training data. Under this assumption (which we make formal) we develop a new primitive for detecting backdoor attacks. Our primitive naturally gives rise to a detection algorithm that comes with theoretical guarantees and is effective in practice.
FFCV: Accelerating Training by Removing Data Bottlenecks
Jun 21, 2023



We present FFCV, a library for easy and fast machine learning model training. FFCV speeds up model training by eliminating (often subtle) data bottlenecks from the training process. In particular, we combine techniques such as an efficient file storage format, caching, data pre-loading, asynchronous data transfer, and just-in-time compilation to (a) make data loading and transfer significantly more efficient, ensuring that GPUs can reach full utilization; and (b) offload as much data processing as possible to the CPU asynchronously, freeing GPU cycles for training. Using FFCV, we train ResNet-18 and ResNet-50 on the ImageNet dataset with competitive tradeoff between accuracy and training time. For example, we are able to train an ImageNet ResNet-50 model to 75\% in only 20 mins on a single machine. We demonstrate FFCV's performance, ease-of-use, extensibility, and ability to adapt to resource constraints through several case studies. Detailed installation instructions, documentation, and Slack support channel are available at https://ffcv.io/ .
Raising the Cost of Malicious AI-Powered Image Editing
Feb 13, 2023



We present an approach to mitigating the risks of malicious image editing posed by large diffusion models. The key idea is to immunize images so as to make them resistant to manipulation by these models. This immunization relies on injection of imperceptible adversarial perturbations designed to disrupt the operation of the targeted diffusion models, forcing them to generate unrealistic images. We provide two methods for crafting such perturbations, and then demonstrate their efficacy. Finally, we discuss a policy component necessary to make our approach fully effective and practical -- one that involves the organizations developing diffusion models, rather than individual users, to implement (and support) the immunization process.
WaveNets: Wavelet Channel Attention Networks
Nov 04, 2022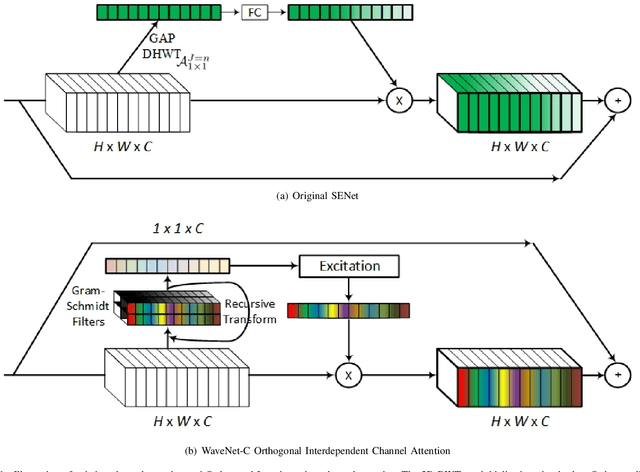

Channel Attention reigns supreme as an effective technique in the field of computer vision. However, the proposed channel attention by SENet suffers from information loss in feature learning caused by the use of Global Average Pooling (GAP) to represent channels as scalars. Thus, designing effective channel attention mechanisms requires finding a solution to enhance features preservation in modeling channel inter-dependencies. In this work, we utilize Wavelet transform compression as a solution to the channel representation problem. We first test wavelet transform as an Auto-Encoder model equipped with conventional channel attention module. Next, we test wavelet transform as a standalone channel compression method. We prove that global average pooling is equivalent to the recursive approximate Haar wavelet transform. With this proof, we generalize channel attention using Wavelet compression and name it WaveNet. Implementation of our method can be embedded within existing channel attention methods with a couple of lines of code. We test our proposed method using ImageNet dataset for image classification task. Our method outperforms the baseline SENet, and achieves the state-of-the-art results. Our code implementation is publicly available at https://github.com/hady1011/WaveNet-C.
A Data-Based Perspective on Transfer Learning
Jul 12, 2022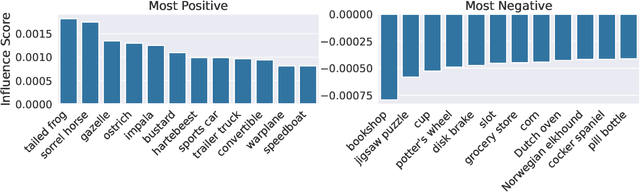
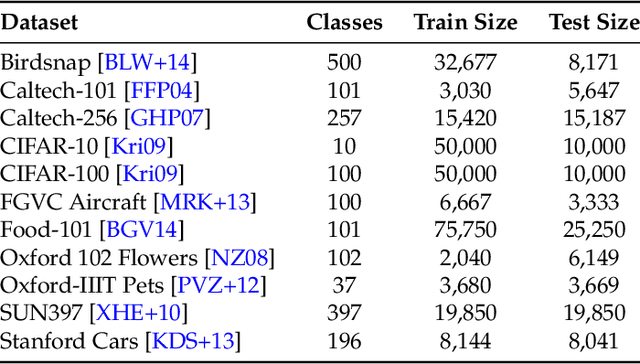
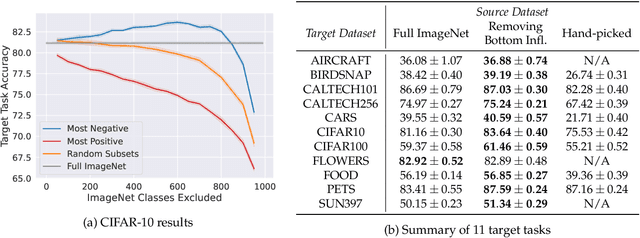
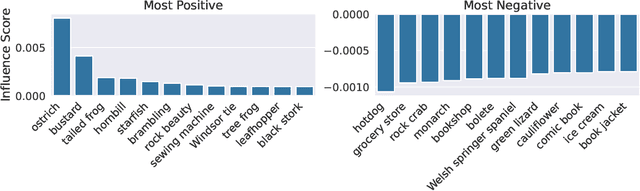
It is commonly believed that in transfer learning including more pre-training data translates into better performance. However, recent evidence suggests that removing data from the source dataset can actually help too. In this work, we take a closer look at the role of the source dataset's composition in transfer learning and present a framework for probing its impact on downstream performance. Our framework gives rise to new capabilities such as pinpointing transfer learning brittleness as well as detecting pathologies such as data-leakage and the presence of misleading examples in the source dataset. In particular, we demonstrate that removing detrimental datapoints identified by our framework improves transfer learning performance from ImageNet on a variety of target tasks. Code is available at https://github.com/MadryLab/data-transfer