 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Principled Evaluations of Sparse Autoencoders for Interpretability and Control
May 16, 2024



Disentangling model activations into meaningful features is a central problem in interpretability. However, the lack of ground-truth for these features in realistic scenarios makes the validation of recent approaches, such as sparse dictionary learning, elusive. To overcome this, we propose a framework to evaluate feature dictionaries in the context of specific tasks, by comparing them against \emph{supervised} feature dictionaries. First, we demonstrate that supervised dictionaries achieve excellent approximation, control and interpretability of model computations on the task. Second, we use the supervised dictionaries to develop and contextualize evaluations of unsupervised dictionaries along the same three axes. We apply this framework to the indirect object identification task (IOI) using GPT-2 Small, with sparse autoencoders (SAEs) trained on either the IOI or OpenWebText datasets. We find that these SAEs capture interpretable features for the IOI task, but they are not as successful as supervised features in controlling the model. Finally, we observe two qualitative phenomena in SAE training: feature occlusion (where a causally relevant concept is robustly overshadowed by even slightly higher-magnitude ones in the learned features), and feature over-splitting (where binary features split into many smaller features without clear interpretation). We hope that our framework will be a useful step towards more objective and grounded evaluations of sparse dictionary learning methods.
Is This the Subspace You Are Looking for? An Interpretability Illusion for Subspace Activation Patching
Dec 06, 2023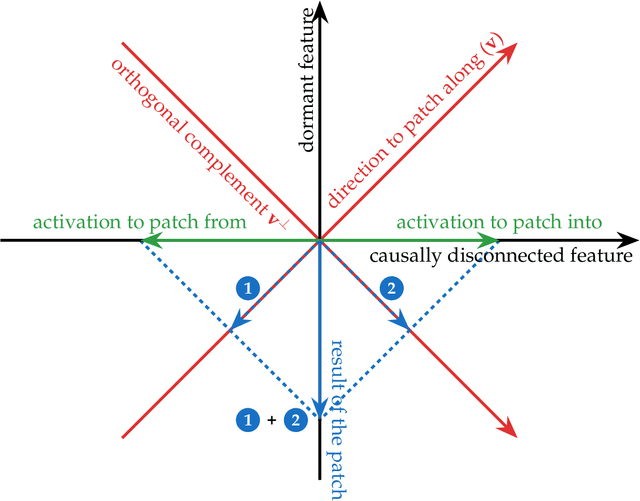
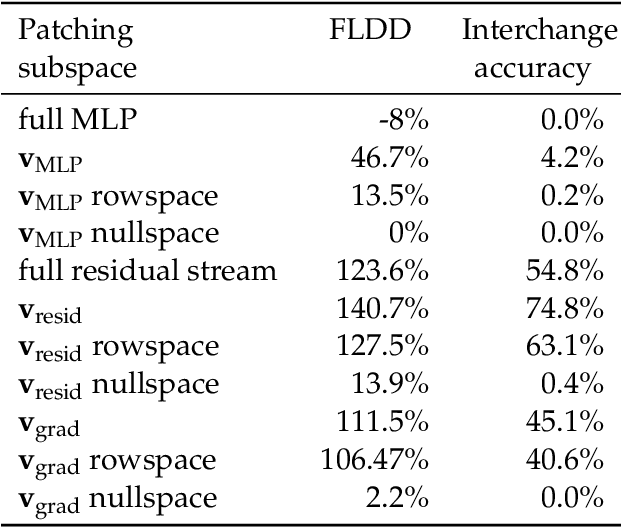
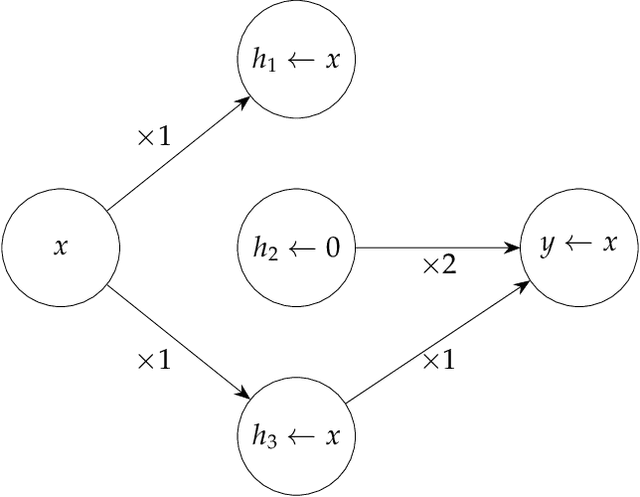
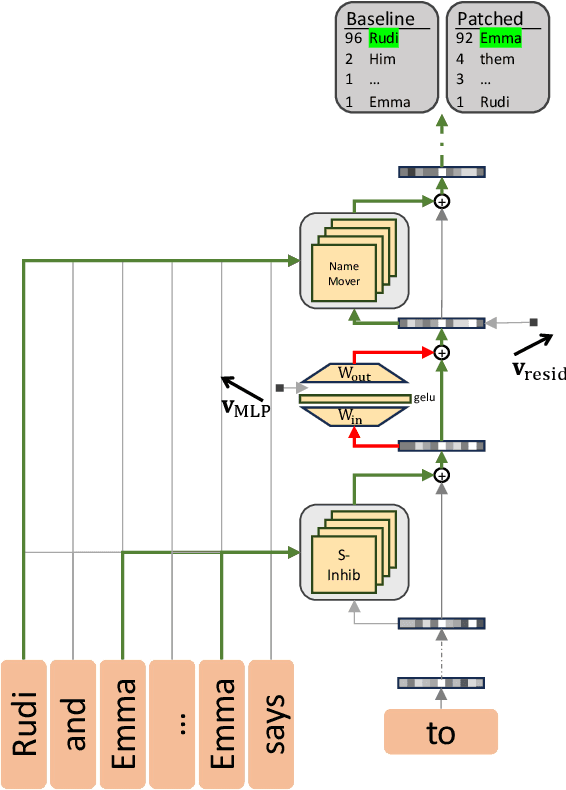
Mechanistic interpretability aims to understand model behaviors in terms of specific, interpretable features, often hypothesized to manifest as low-dimensional subspaces of activations. Specifically, recent studies have explored subspace interventions (such as activation patching) as a way to simultaneously manipulate model behavior and attribute the features behind it to given subspaces. In this work, we demonstrate that these two aims diverge, potentially leading to an illusory sense of interpretability. Counterintuitively, even if a subspace intervention makes the model's output behave as if the value of a feature was changed, this effect may be achieved by activating a dormant parallel pathway leveraging another subspace that is causally disconnected from model outputs. We demonstrate this phenomenon in a distilled mathematical example, in two real-world domains (the indirect object identification task and factual recall), and present evidence for its prevalence in practice. In the context of factual recall, we further show a link to rank-1 fact editing, providing a mechanistic explanation for previous work observing an inconsistency between fact editing performance and fact localization. However, this does not imply that activation patching of subspaces is intrinsically unfit for interpretability. To contextualize our findings, we also show what a success case looks like in a task (indirect object identification) where prior manual circuit analysis informs an understanding of the location of a feature. We explore the additional evidence needed to argue that a patched subspace is faithful.
Rethinking Backdoor Attacks
Jul 19, 2023



In a backdoor attack, an adversary inserts maliciously constructed backdoor examples into a training set to make the resulting model vulnerable to manipulation. Defending against such attacks typically involves viewing these inserted examples as outliers in the training set and using techniques from robust statistics to detect and remove them. In this work, we present a different approach to the backdoor attack problem. Specifically, we show that without structural information about the training data distribution, backdoor attacks are indistinguishable from naturally-occurring features in the data--and thus impossible to "detect" in a general sense. Then, guided by this observation, we revisit existing defenses against backdoor attacks and characterize the (often latent) assumptions they make and on which they depend. Finally, we explore an alternative perspective on backdoor attacks: one that assumes these attacks correspond to the strongest feature in the training data. Under this assumption (which we make formal) we develop a new primitive for detecting backdoor attacks. Our primitive naturally gives rise to a detection algorithm that comes with theoretical guarantees and is effective in practice.
Towards Deep Learning Models Resistant to Adversarial Attacks
Nov 09, 2017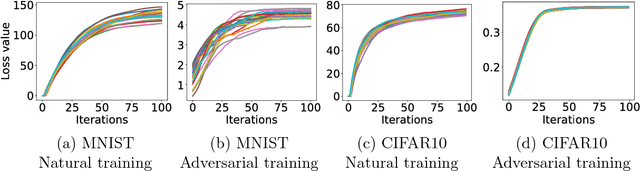

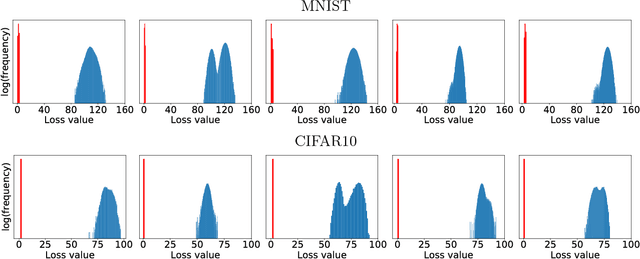
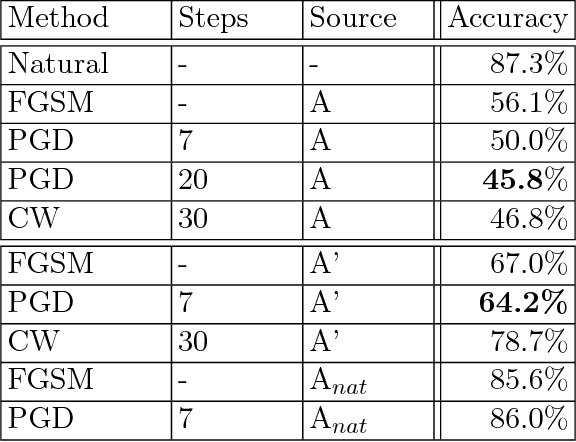
Recent work has demonstrated that neural networks are vulnerable to adversarial examples, i.e., inputs that are almost indistinguishable from natural data and yet classified incorrectly by the network. In fact, some of the latest findings suggest that the existence of adversarial attacks may be an inherent weakness of deep learning models. To address this problem, we study the adversarial robustness of neural networks through the lens of robust optimization. This approach provides us with a broad and unifying view on much of the prior work on this topic. Its principled nature also enables us to identify methods for both training and attacking neural networks that are reliable and, in a certain sense, universal. In particular, they specify a concrete security guarantee that would protect against any adversary. These methods let us train networks with significantly improved resistance to a wide range of adversarial attacks. They also suggest the notion of security against a first-order adversary as a natural and broad security guarantee. We believe that robustness against such well-defined classes of adversaries is an important stepping stone towards fully resistant deep learning models.