 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Rewarding High-Quality Data via Influence Functions
Aug 30, 2019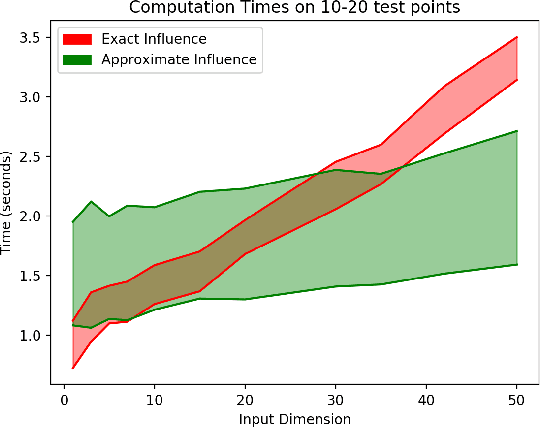
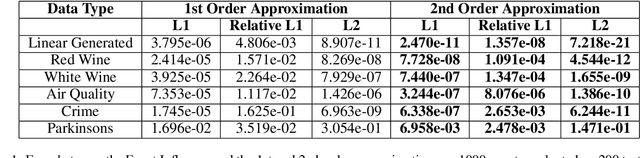
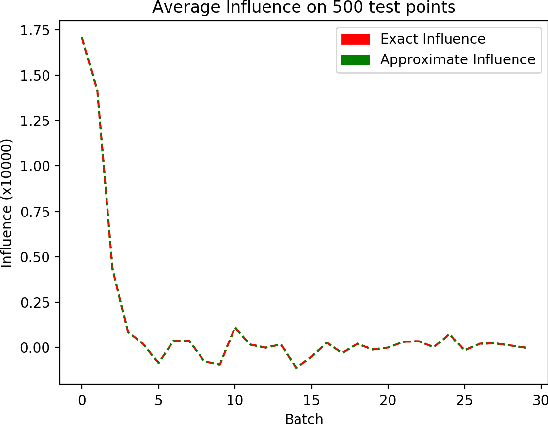
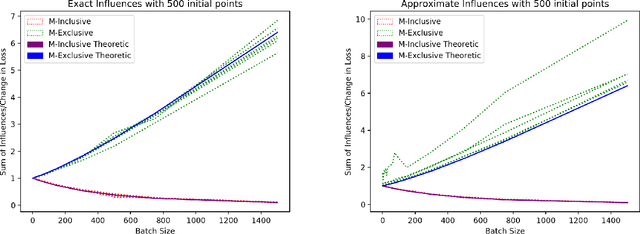
We consider a crowdsourcing data acquisition scenario, such as federated learning, where a Center collects data points from a set of rational Agents, with the aim of training a model. For linear regression models, we show how a payment structure can be designed to incentivize the agents to provide high-quality data as early as possible, based on a characterization of the influence that data points have on the loss function of the model. Our contributions can be summarized as follows: (a) we prove theoretically that this scheme ensures truthful data reporting as a game-theoretic equilibrium and further demonstrate its robustness against mixtures of truthful and heuristic data reports, (b) we design a procedure according to which the influence computation can be efficiently approximated and processed sequentially in batches over time, (c) we develop a theory that allows correcting the difference between the influence and the overall change in loss and (d) we evaluate our approach on real datasets, confirming our theoretical findings.
Shape Completion Enabled Robotic Grasping
Mar 02, 2017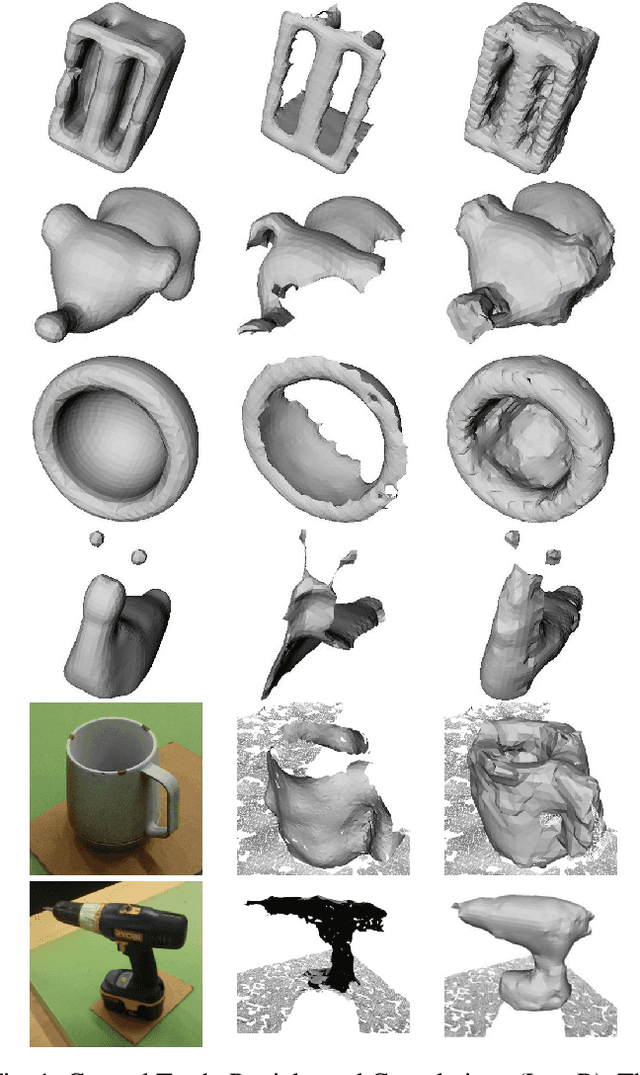
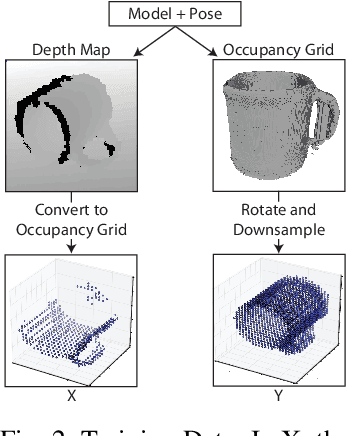
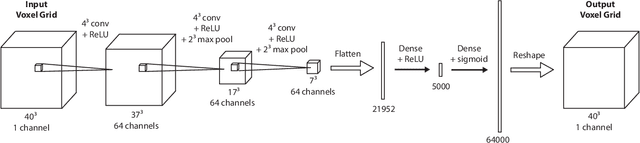

This work provides an architecture to enable robotic grasp planning via shape completion. Shape completion is accomplished through the use of a 3D convolutional neural network (CNN). The network is trained on our own new open source dataset of over 440,000 3D exemplars captured from varying viewpoints. At runtime, a 2.5D pointcloud captured from a single point of view is fed into the CNN, which fills in the occluded regions of the scene, allowing grasps to be planned and executed on the completed object. Runtime shape completion is very rapid because most of the computational costs of shape completion are borne during offline training. We explore how the quality of completions vary based on several factors. These include whether or not the object being completed existed in the training data and how many object models were used to train the network. We also look at the ability of the network to generalize to novel objects allowing the system to complete previously unseen objects at runtime. Finally, experimentation is done both in simulation and on actual robotic hardware to explore the relationship between completion quality and the utility of the completed mesh model for grasping.