 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeleoperated Robot Grasping in Virtual Reality Spaces
Jan 30, 2023

Despite recent advancement in virtual reality technology, teleoperating a high DoF robot to complete dexterous tasks in cluttered scenes remains difficult. In this work, we propose a system that allows the user to teleoperate a Fetch robot to perform grasping in an easy and intuitive way, through exploiting the rich environment information provided by the virtual reality space. Our system has the benefit of easy transferability to different robots and different tasks, and can be used without any expert knowledge. We tested the system on a real fetch robot, and a video demonstrating the effectiveness of our system can be seen at https://youtu.be/1-xW2Bx_Cms.
Multiple View Performers for Shape Completion
Sep 13, 2022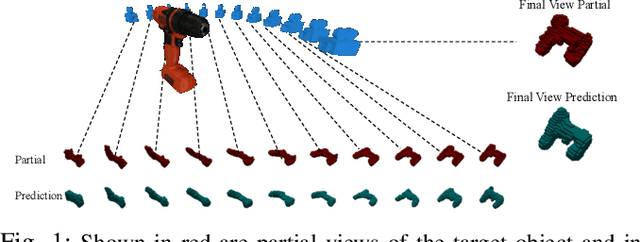
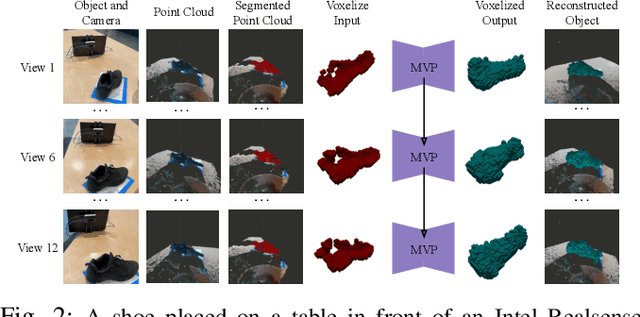
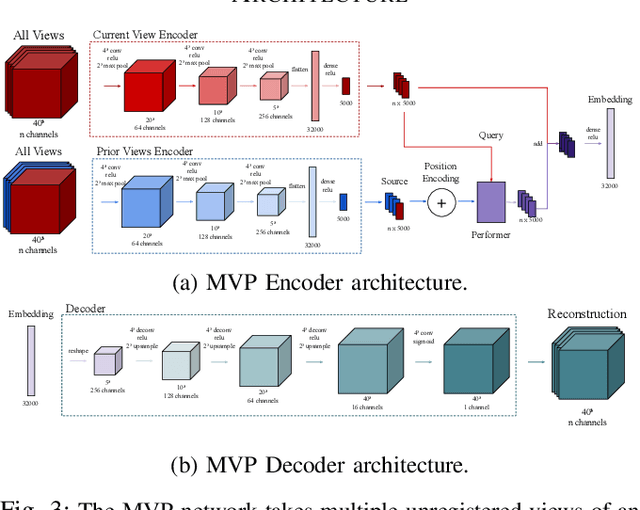
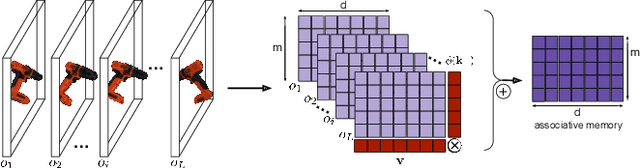
We propose the Multiple View Performer (MVP) - a new architecture for 3D shape completion from a series of temporally sequential views. MVP accomplishes this task by using linear-attention Transformers called Performers. Our model allows the current observation of the scene to attend to the previous ones for more accurate infilling. The history of past observations is compressed via the compact associative memory approximating modern continuous Hopfield memory, but crucially of size independent from the history length. We compare our model with several baselines for shape completion over time, demonstrating the generalization gains that MVP provides. To the best of our knowledge, MVP is the first multiple view voxel reconstruction method that does not require registration of multiple depth views and the first causal Transformer based model for 3D shape completion.
CLAMGen: Closed-Loop Arm Motion Generation via Multi-view Vision-Based RL
Mar 24, 2021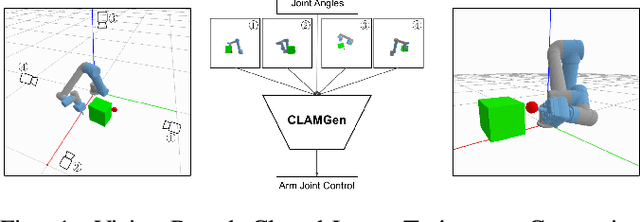
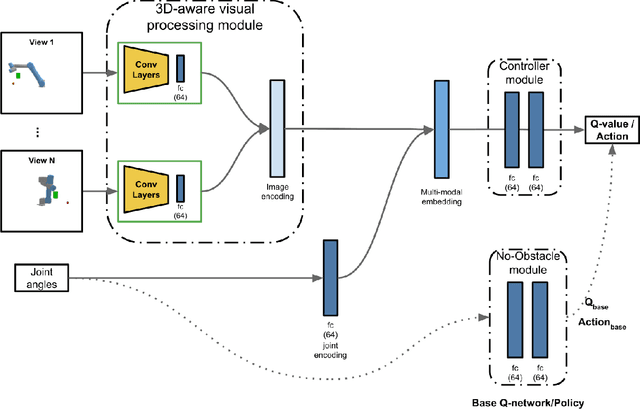
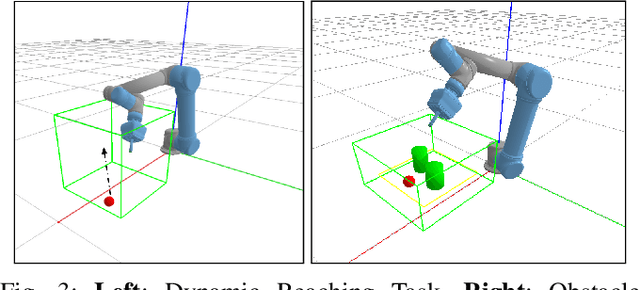

We propose a vision-based reinforcement learning (RL) approach for closed-loop trajectory generation in an arm reaching problem. Arm trajectory generation is a fundamental robotics problem which entails finding collision-free paths to move the robot's body (e.g. arm) in order to satisfy a goal (e.g. place end-effector at a point). While classical methods typically require the model of the environment to solve a planning, search or optimization problem, learning-based approaches hold the promise of directly mapping from observations to robot actions. However, learning a collision-avoidance policy using RL remains a challenge for various reasons, including, but not limited to, partial observability, poor exploration, low sample efficiency, and learning instabilities. To address these challenges, we present a residual-RL method that leverages a greedy goal-reaching RL policy as the base to improve exploration, and the base policy is augmented with residual state-action values and residual actions learned from images to avoid obstacles. Further more, we introduce novel learning objectives and techniques to improve 3D understanding from multiple image views and sample efficiency of our algorithm. Compared to RL baselines, our method achieves superior performance in terms of success rate.
Maximizing BCI Human Feedback using Active Learning
Aug 11, 2020
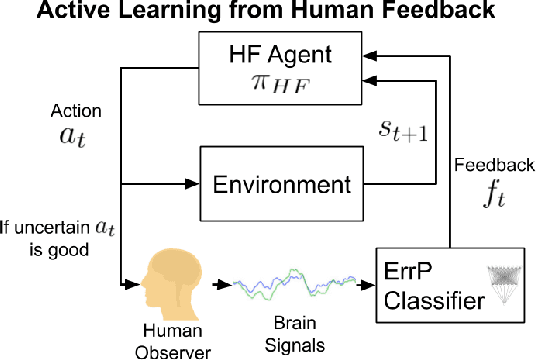
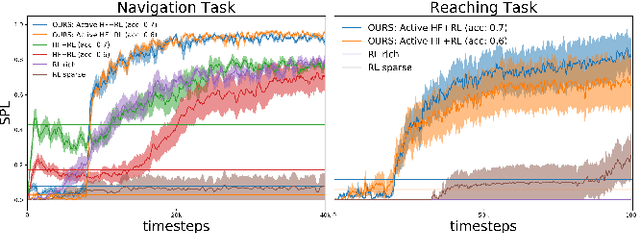
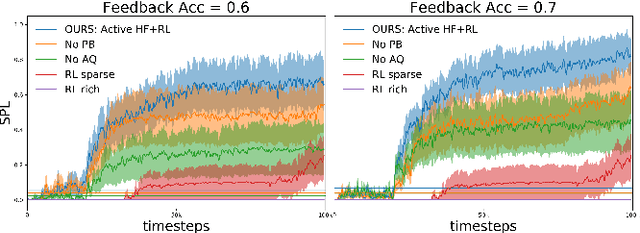
Recent advancements in \textit{Learning from Human Feedback} present an effective way to train robot agents via inputs from non-expert humans, without a need for a specially designed reward function. However, this approach needs a human to be present and attentive during robot learning to provide evaluative feedback. In addition, the amount of feedback needed grows with the level of task difficulty and the quality of human feedback might decrease over time because of fatigue. To overcome these limitations and enable learning more robot tasks with higher complexities, there is a need to maximize the quality of expensive feedback received and reduce the amount of human cognitive involvement required. In this work, we present an approach that uses active learning to smartly choose queries for the human supervisor based on the uncertainty of the robot and effectively reduces the amount of feedback needed to learn a given task. We also use a novel multiple buffer system to improve robustness to feedback noise and guard against catastrophic forgetting as the robot learning evolves. This makes it possible to learn tasks with more complexity using lesser amounts of human feedback compared to previous methods. We demonstrate the utility of our proposed method on a robot arm reaching task where the robot learns to reach a location in 3D without colliding with obstacles. Our approach is able to learn this task faster, with less human feedback and cognitive involvement, compared to previous methods that do not use active learning.
MAT: Multi-Fingered Adaptive Tactile Grasping via Deep Reinforcement Learning
Oct 10, 2019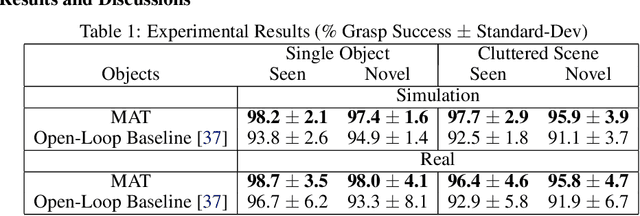

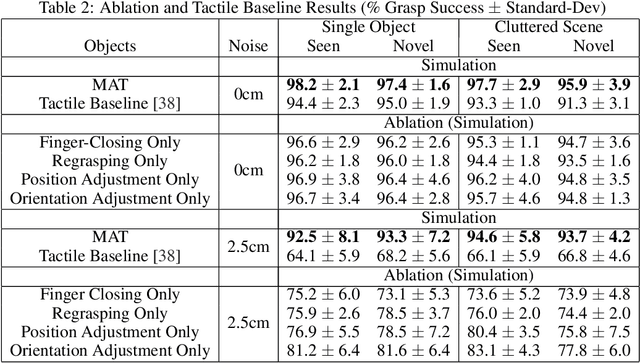

Vision-based grasping systems typically adopt an open-loop execution of a planned grasp. This policy can fail due to many reasons, including ubiquitous calibration error. Recovery from a failed grasp is further complicated by visual occlusion, as the hand is usually occluding the vision sensor as it attempts another open-loop regrasp. This work presents MAT, a tactile closed-loop method capable of realizing grasps provided by a coarse initial positioning of the hand above an object. Our algorithm is a deep reinforcement learning (RL) policy optimized through the clipped surrogate objective within a maximum entropy RL framework to balance exploitation and exploration. The method utilizes tactile and proprioceptive information to act through both fine finger motions and larger regrasp movements to execute stable grasps. A novel curriculum of action motion magnitude makes learning more tractable and helps turn common failure cases into successes. Careful selection of features that exhibit small sim-to-real gaps enables this tactile grasping policy, trained purely in simulation, to transfer well to real world environments without the need for additional learning. Experimentally, this methodology improves over a vision-only grasp success rate substantially on a multi-fingered robot hand. When this methodology is used to realize grasps from coarse initial positions provided by a vision-only planner, the system is made dramatically more robust to calibration errors in the camera-robot transform.
Accelerated Robot Learning via Human Brain Signals
Oct 01, 2019
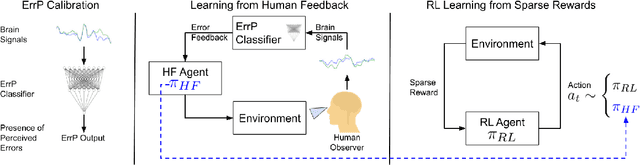
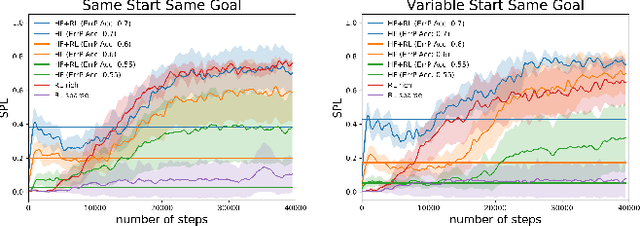

In reinforcement learning (RL), sparse rewards are a natural way to specify the task to be learned. However, most RL algorithms struggle to learn in this setting since the learning signal is mostly zeros. In contrast, humans are good at assessing and predicting the future consequences of actions and can serve as good reward/policy shapers to accelerate the robot learning process. Previous works have shown that the human brain generates an error-related signal, measurable using electroencephelography (EEG), when the human perceives the task being done erroneously. In this work, we propose a method that uses evaluative feedback obtained from human brain signals measured via scalp EEG to accelerate RL for robotic agents in sparse reward settings. As the robot learns the task, the EEG of a human observer watching the robot attempts is recorded and decoded into noisy error feedback signal. From this feedback, we use supervised learning to obtain a policy that subsequently augments the behavior policy and guides exploration in the early stages of RL. This bootstraps the RL learning process to enable learning from sparse reward. Using a robotic navigation task as a test bed, we show that our method achieves a stable obstacle-avoidance policy with high success rate, outperforming learning from sparse rewards only that struggles to achieve obstacle avoidance behavior or fails to advance to the goal.
Learning Your Way Without Map or Compass: Panoramic Target Driven Visual Navigation
Sep 20, 2019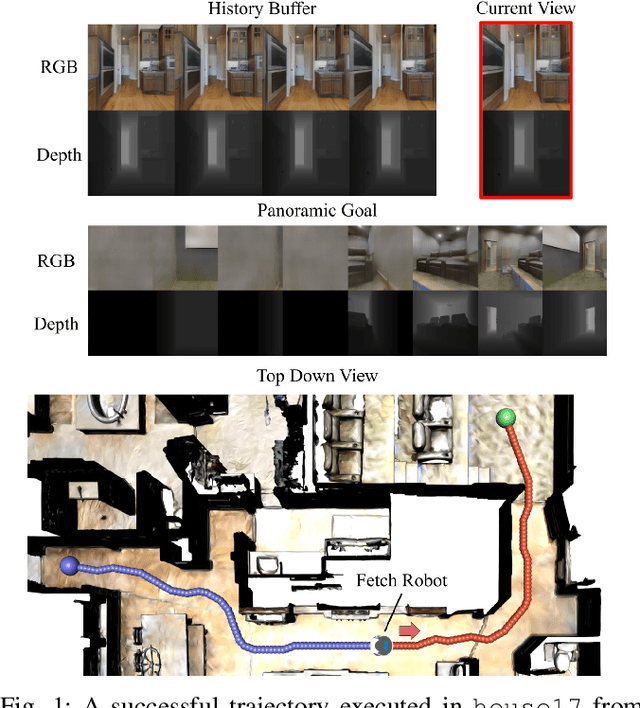
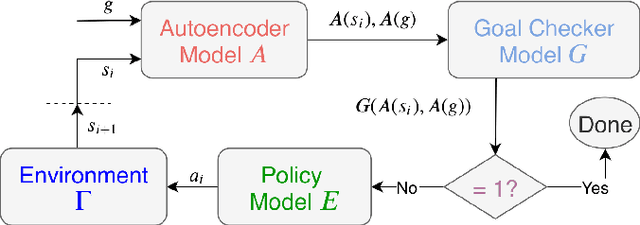

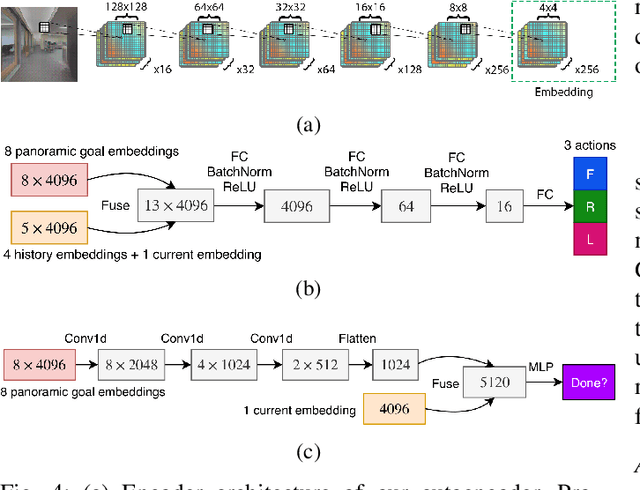
We present a robot navigation system that uses an imitation learning framework to successfully navigate in complex environments. Our framework takes a pre-built 3D scan of a real environment and trains an agent from pre-generated expert trajectories to navigate to any position given a panoramic view of the goal and the current visual input without relying on map, compass, odometry, GPS or relative position of the target at runtime. Our end-to-end trained agent uses RGB and depth (RGBD) information and can handle large environments (up to $1031m^2$) across multiple rooms (up to $40$) and generalizes to unseen targets. We show that when compared to several baselines using deep reinforcement learning and RGBD SLAM, our method (1) requires fewer training examples and less training time, (2) reaches the goal location with higher accuracy, (3) produces better solutions with shorter paths for long-range navigation tasks, and (4) generalizes to unseen environments given an RGBD map of the environment.
Multi-Modal Geometric Learning for Grasping and Manipulation
Feb 27, 2019
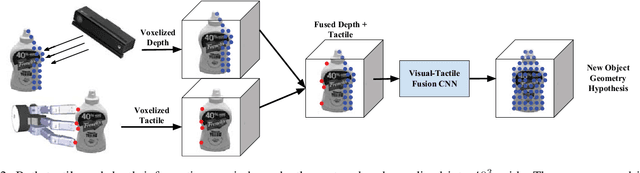
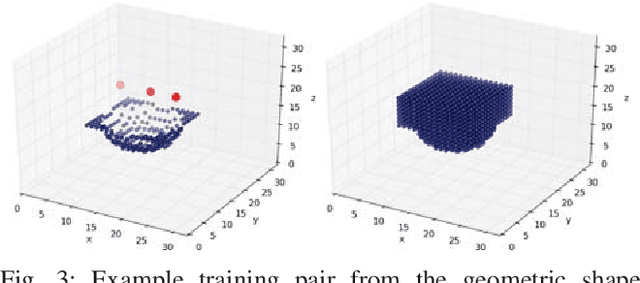

This work provides an architecture that incorporates depth and tactile information to create rich and accurate 3D models useful for robotic manipulation tasks. This is accomplished through the use of a 3D convolutional neural network (CNN). Offline, the network is provided with both depth and tactile information and trained to predict the object's geometry, thus filling in regions of occlusion. At runtime, the network is provided a partial view of an object. Tactile information is acquired to augment the captured depth information. The network can then reason about the object's geometry by utilizing both the collected tactile and depth information. We demonstrate that even small amounts of additional tactile information can be incredibly helpful in reasoning about object geometry. This is particularly true when information from depth alone fails to produce an accurate geometric prediction. Our method is benchmarked against and outperforms other visual-tactile approaches to general geometric reasoning. We also provide experimental results comparing grasping success with our method.
Human Robot Interface for Assistive Grasping
Apr 06, 2018
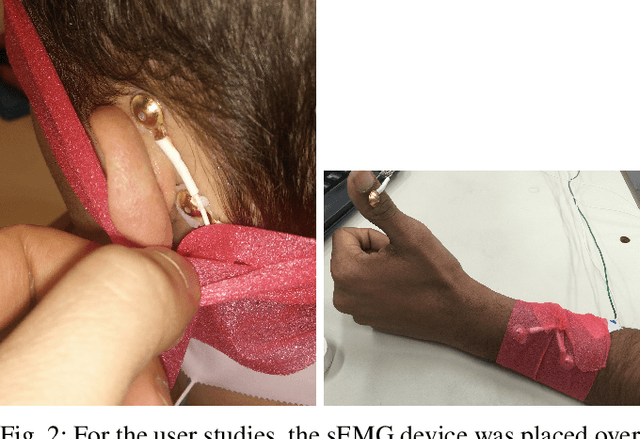

This work describes a new human-in-the-loop (HitL) assistive grasping system for individuals with varying levels of physical capabilities. We investigated the feasibility of using four potential input devices with our assistive grasping system interface, using able-bodied individuals to define a set of quantitative metrics that could be used to assess an assistive grasping system. We then took these measurements and created a generalized benchmark for evaluating the effectiveness of any arbitrary input device into a HitL grasping system. The four input devices were a mouse, a speech recognition device, an assistive switch, and a novel sEMG device developed by our group that was connected either to the forearm or behind the ear of the subject. These preliminary results provide insight into how different interface devices perform for generalized assistive grasping tasks and also highlight the potential of sEMG based control for severely disabled individuals.
Shape Completion Enabled Robotic Grasping
Mar 02, 2017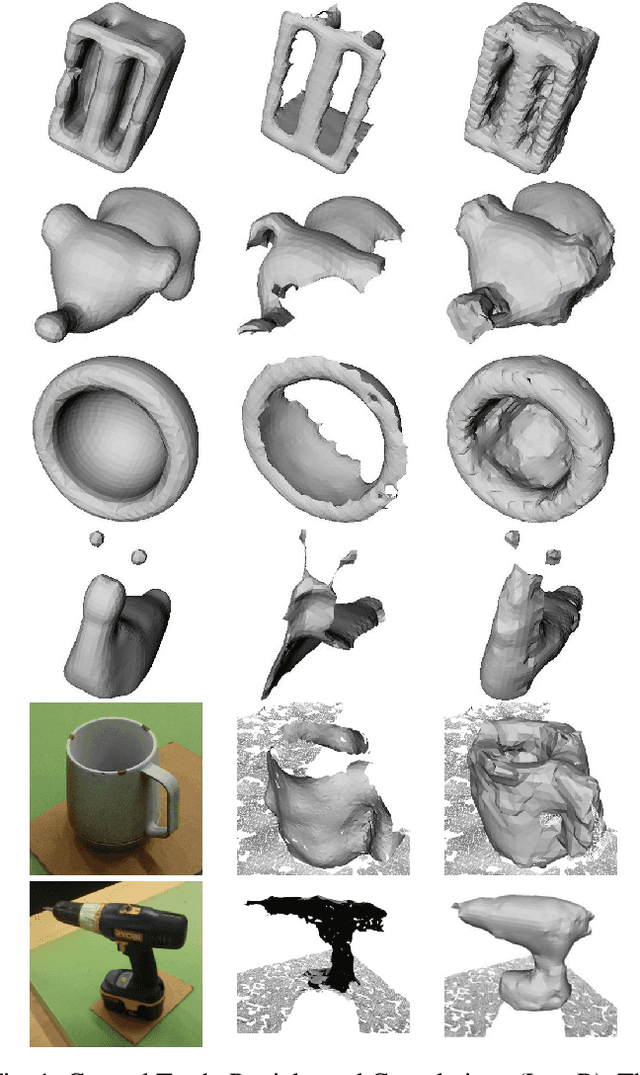
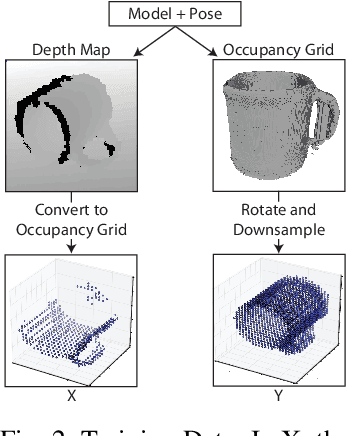
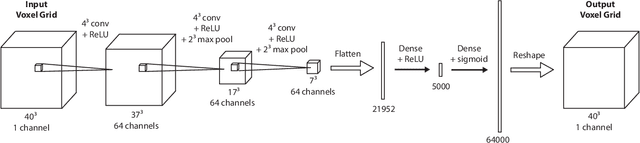

This work provides an architecture to enable robotic grasp planning via shape completion. Shape completion is accomplished through the use of a 3D convolutional neural network (CNN). The network is trained on our own new open source dataset of over 440,000 3D exemplars captured from varying viewpoints. At runtime, a 2.5D pointcloud captured from a single point of view is fed into the CNN, which fills in the occluded regions of the scene, allowing grasps to be planned and executed on the completed object. Runtime shape completion is very rapid because most of the computational costs of shape completion are borne during offline training. We explore how the quality of completions vary based on several factors. These include whether or not the object being completed existed in the training data and how many object models were used to train the network. We also look at the ability of the network to generalize to novel objects allowing the system to complete previously unseen objects at runtime. Finally, experimentation is done both in simulation and on actual robotic hardware to explore the relationship between completion quality and the utility of the completed mesh model for grasping.