 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARR: Simulation-based Policies with Asymmetric Real-world Residuals for Assembly
Feb 26, 2026Robotic assembly presents a long-standing challenge due to its requirement for precise, contact-rich manipulation. While simulation-based learning has enabled the development of robust assembly policies, their performance often degrades when deployed in real-world settings due to the sim-to-real gap. Conversely, real-world reinforcement learning (RL) methods avoid the sim-to-real gap, but rely heavily on human supervision and lack generalization ability to environmental changes. In this work, we propose a hybrid approach that combines a simulation-trained base policy with a real-world residual policy to efficiently adapt to real-world variations. The base policy, trained in simulation using low-level state observations and dense rewards, provides strong priors for initial behavior. The residual policy, learned in the real world using visual observations and sparse rewards, compensates for discrepancies in dynamics and sensor noise. Extensive real-world experiments demonstrate that our method, SPARR, achieves near-perfect success rates across diverse two-part assembly tasks. Compared to the state-of-the-art zero-shot sim-to-real methods, SPARR improves success rates by 38.4% while reducing cycle time by 29.7%. Moreover, SPARR requires no human expertise, in contrast to the state-of-the-art real-world RL approaches that depend heavily on human supervision.
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
The Reality Gap in Robotics: Challenges, Solutions, and Best Practices
Oct 23, 2025Machine learning has facilitated significant advancements across various robotics domains, including navigation, locomotion, and manipulation. Many such achievements have been driven by the extensive use of simulation as a critical tool for training and testing robotic systems prior to their deployment in real-world environments. However, simulations consist of abstractions and approximations that inevitably introduce discrepancies between simulated and real environments, known as the reality gap. These discrepancies significantly hinder the successful transfer of systems from simulation to the real world. Closing this gap remains one of the most pressing challenges in robotics. Recent advances in sim-to-real transfer have demonstrated promising results across various platforms, including locomotion, navigation, and manipulation. By leveraging techniques such as domain randomization, real-to-sim transfer, state and action abstractions, and sim-real co-training, many works have overcome the reality gap. However, challenges persist, and a deeper understanding of the reality gap's root causes and solutions is necessary. In this survey, we present a comprehensive overview of the sim-to-real landscape, highlighting the causes, solutions, and evaluation metrics for the reality gap and sim-to-real transfer.
MatchMaker: Automated Asset Generation for Robotic Assembly
Mar 07, 2025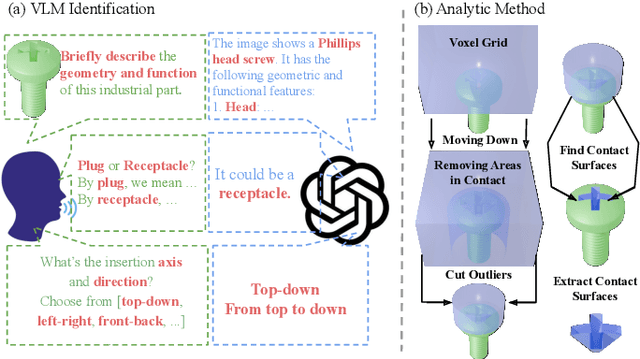
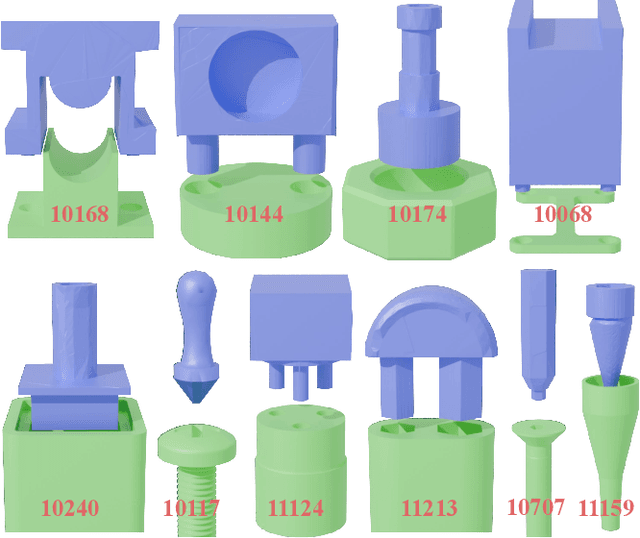
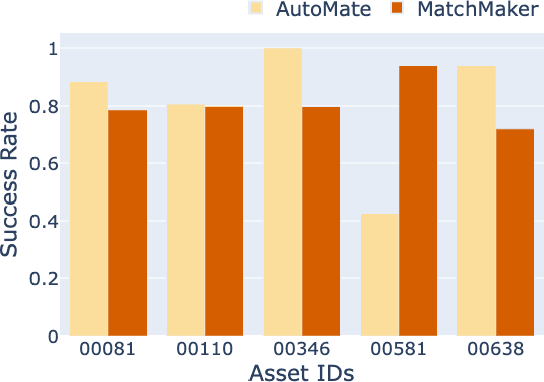
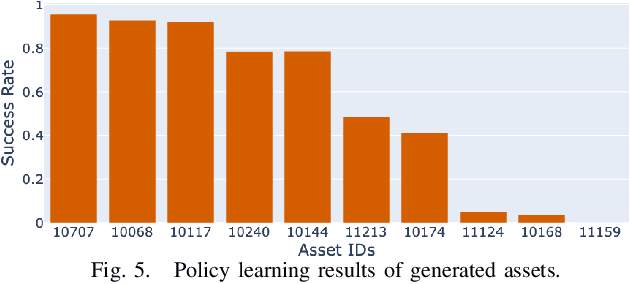
Robotic assembly remains a significant challenge due to complexities in visual perception, functional grasping, contact-rich manipulation, and performing high-precision tasks. Simulation-based learning and sim-to-real transfer have led to recent success in solving assembly tasks in the presence of object pose variation, perception noise, and control error; however, the development of a generalist (i.e., multi-task) agent for a broad range of assembly tasks has been limited by the need to manually curate assembly assets, which greatly constrains the number and diversity of assembly problems that can be used for policy learning. Inspired by recent success of using generative AI to scale up robot learning, we propose MatchMaker, a pipeline to automatically generate diverse, simulation-compatible assembly asset pairs to facilitate learning assembly skills. Specifically, MatchMaker can 1) take a simulation-incompatible, interpenetrating asset pair as input, and automatically convert it into a simulation-compatible, interpenetration-free pair, 2) take an arbitrary single asset as input, and generate a geometrically-mating asset to create an asset pair, 3) automatically erode contact surfaces from (1) or (2) according to a user-specified clearance parameter to generate realistic parts. We demonstrate that data generated by MatchMaker outperforms previous work in terms of diversity and effectiveness for downstream assembly skill learning. For videos and additional details, please see our project website: https://wangyian-me.github.io/MatchMaker/.
SRSA: Skill Retrieval and Adaptation for Robotic Assembly Tasks
Mar 06, 2025



Enabling robots to learn novel tasks in a data-efficient manner is a long-standing challenge. Common strategies involve carefully leveraging prior experiences, especially transition data collected on related tasks. Although much progress has been made for general pick-and-place manipulation, far fewer studies have investigated contact-rich assembly tasks, where precise control is essential. We introduce SRSA (Skill Retrieval and Skill Adaptation), a novel framework designed to address this problem by utilizing a pre-existing skill library containing policies for diverse assembly tasks. The challenge lies in identifying which skill from the library is most relevant for fine-tuning on a new task. Our key hypothesis is that skills showing higher zero-shot success rates on a new task are better suited for rapid and effective fine-tuning on that task. To this end, we propose to predict the transfer success for all skills in the skill library on a novel task, and then use this prediction to guide the skill retrieval process. We establish a framework that jointly captures features of object geometry, physical dynamics, and expert actions to represent the tasks, allowing us to efficiently learn the transfer success predictor. Extensive experiments demonstrate that SRSA significantly outperforms the leading baseline. When retrieving and fine-tuning skills on unseen tasks, SRSA achieves a 19% relative improvement in success rate, exhibits 2.6x lower standard deviation across random seeds, and requires 2.4x fewer transition samples to reach a satisfactory success rate, compared to the baseline. Furthermore, policies trained with SRSA in simulation achieve a 90% mean success rate when deployed in the real world. Please visit our project webpage https://srsa2024.github.io/.
TacSL: A Library for Visuotactile Sensor Simulation and Learning
Aug 12, 2024



For both humans and robots, the sense of touch, known as tactile sensing, is critical for performing contact-rich manipulation tasks. Three key challenges in robotic tactile sensing are 1) interpreting sensor signals, 2) generating sensor signals in novel scenarios, and 3) learning sensor-based policies. For visuotactile sensors, interpretation has been facilitated by their close relationship with vision sensors (e.g., RGB cameras). However, generation is still difficult, as visuotactile sensors typically involve contact, deformation, illumination, and imaging, all of which are expensive to simulate; in turn, policy learning has been challenging, as simulation cannot be leveraged for large-scale data collection. We present \textbf{TacSL} (\textit{taxel}), a library for GPU-based visuotactile sensor simulation and learning. \textbf{TacSL} can be used to simulate visuotactile images and extract contact-force distributions over $200\times$ faster than the prior state-of-the-art, all within the widely-used Isaac Gym simulator. Furthermore, \textbf{TacSL} provides a learning toolkit containing multiple sensor models, contact-intensive training environments, and online/offline algorithms that can facilitate policy learning for sim-to-real applications. On the algorithmic side, we introduce a novel online reinforcement-learning algorithm called asymmetric actor-critic distillation (\sysName), designed to effectively and efficiently learn tactile-based policies in simulation that can transfer to the real world. Finally, we demonstrate the utility of our library and algorithms by evaluating the benefits of distillation and multimodal sensing for contact-rich manip ulation tasks, and most critically, performing sim-to-real transfer. Supplementary videos and results are at \url{https://iakinola23.github.io/tacsl/}.
FORGE: Force-Guided Exploration for Robust Contact-Rich Manipulation under Uncertainty
Aug 08, 2024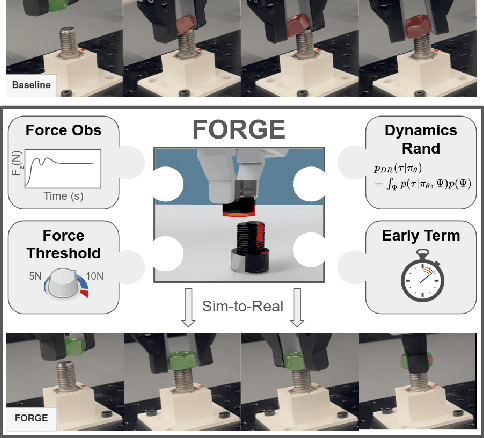

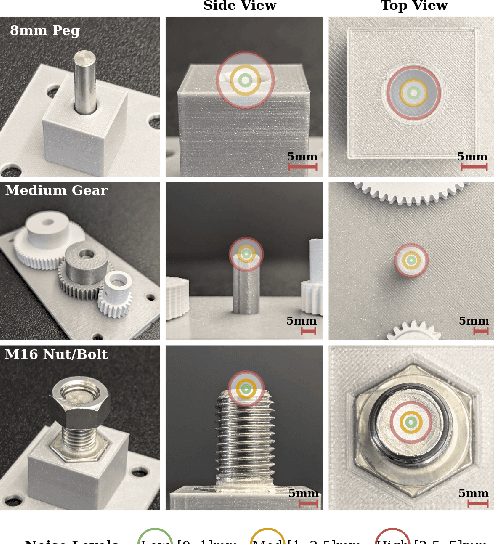
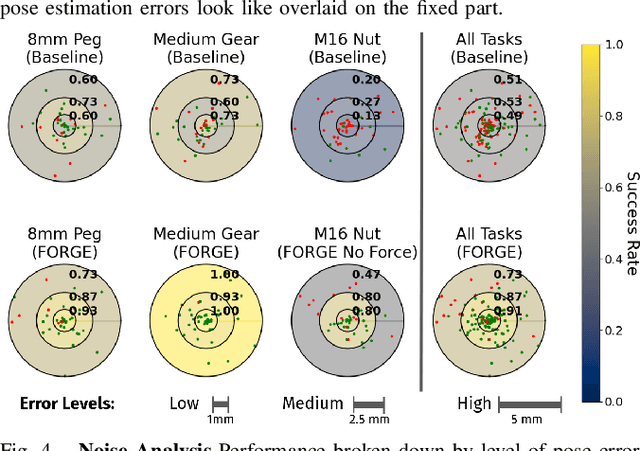
We present FORGE, a method that enables sim-to-real transfer of contact-rich manipulation policies in the presence of significant pose uncertainty. FORGE combines a force threshold mechanism with a dynamics randomization scheme during policy learning in simulation, to enable the robust transfer of the learned policies to the real robot. At deployment, FORGE policies, conditioned on a maximum allowable force, adaptively perform contact-rich tasks while respecting the specified force threshold, regardless of the controller gains. Additionally, FORGE autonomously predicts a termination action once the task has succeeded. We demonstrate that FORGE can be used to learn a variety of robust contact-rich policies, enabling multi-stage assembly of a planetary gear system, which requires success across three assembly tasks: nut-threading, insertion, and gear meshing. Project website can be accessed at https://noseworm.github.io/forge/.
AutoMate: Specialist and Generalist Assembly Policies over Diverse Geometries
Jul 10, 2024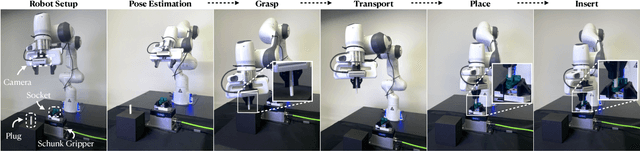

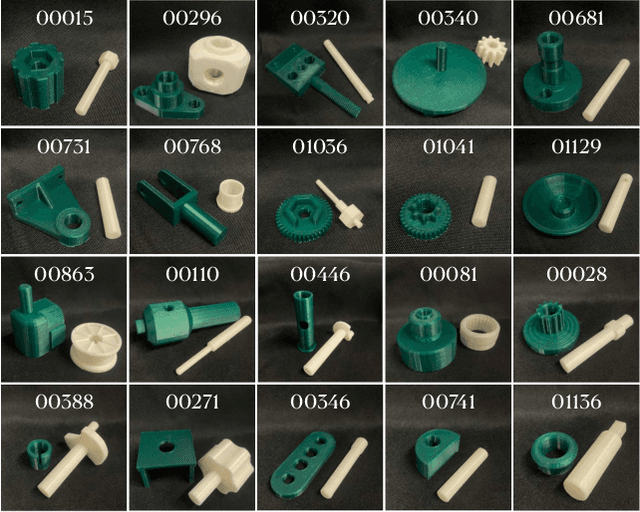

Robotic assembly for high-mixture settings requires adaptivity to diverse parts and poses, which is an open challenge. Meanwhile, in other areas of robotics, large models and sim-to-real have led to tremendous progress. Inspired by such work, we present AutoMate, a learning framework and system that consists of 4 parts: 1) a dataset of 100 assemblies compatible with simulation and the real world, along with parallelized simulation environments for policy learning, 2) a novel simulation-based approach for learning specialist (i.e., part-specific) policies and generalist (i.e., unified) assembly policies, 3) demonstrations of specialist policies that individually solve 80 assemblies with 80% or higher success rates in simulation, as well as a generalist policy that jointly solves 20 assemblies with an 80%+ success rate, and 4) zero-shot sim-to-real transfer that achieves similar (or better) performance than simulation, including on perception-initialized assembly. The key methodological takeaway is that a union of diverse algorithms from manufacturing engineering, character animation, and time-series analysis provides a generic and robust solution for a diverse range of robotic assembly problems.To our knowledge, AutoMate provides the first simulation-based framework for learning specialist and generalist policies over a wide range of assemblies, as well as the first system demonstrating zero-shot sim-to-real transfer over such a range.
Signatures Meet Dynamic Programming: Generalizing Bellman Equations for Trajectory Following
Dec 09, 2023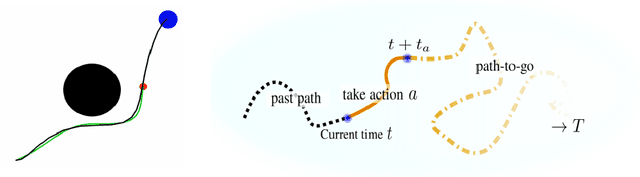
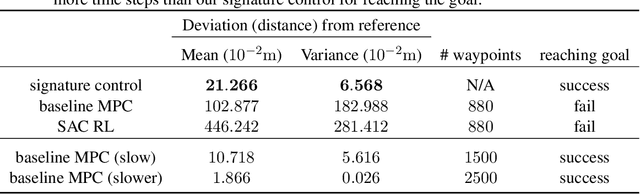
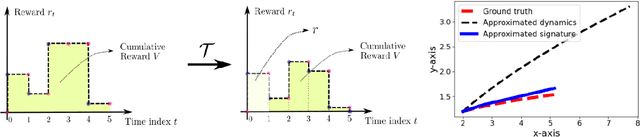
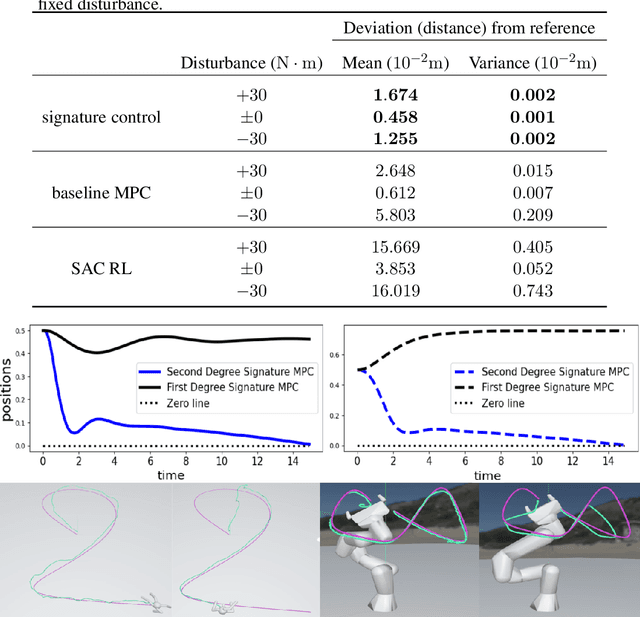
Path signatures have been proposed as a powerful representation of paths that efficiently captures the path's analytic and geometric characteristics, having useful algebraic properties including fast concatenation of paths through tensor products. Signatures have recently been widely adopted in machine learning problems for time series analysis. In this work we establish connections between value functions typically used in optimal control and intriguing properties of path signatures. These connections motivate our novel control framework with signature transforms that efficiently generalizes the Bellman equation to the space of trajectories. We analyze the properties and advantages of the framework, termed signature control. In particular, we demonstrate that (i) it can naturally deal with varying/adaptive time steps; (ii) it propagates higher-level information more efficiently than value function updates; (iii) it is robust to dynamical system misspecification over long rollouts. As a specific case of our framework, we devise a model predictive control method for path tracking. This method generalizes integral control, being suitable for problems with unknown disturbances. The proposed algorithms are tested in simulation, with differentiable physics models including typical control and robotics tasks such as point-mass, curve following for an ant model, and a robotic manipulator.
MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations
Oct 26, 2023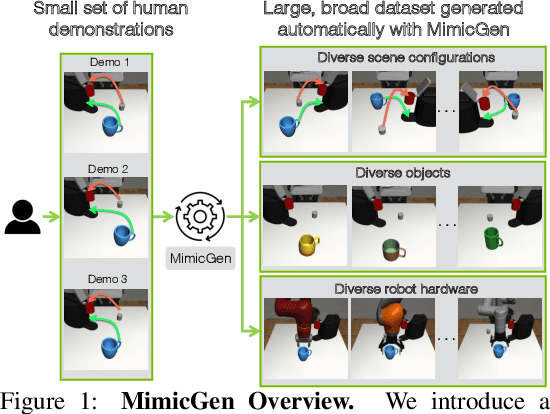
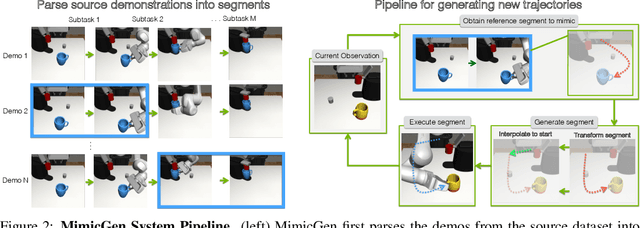

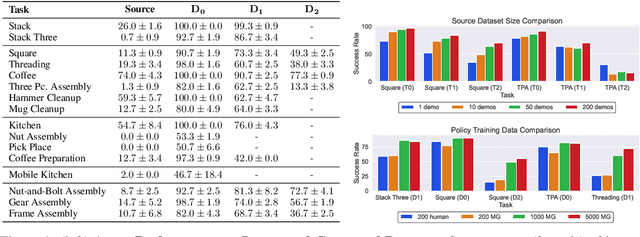
Imitation learning from a large set of human demonstrations has proved to be an effective paradigm for building capable robot agents. However, the demonstrations can be extremely costly and time-consuming to collect. We introduce MimicGen, a system for automatically synthesizing large-scale, rich datasets from only a small number of human demonstrations by adapting them to new contexts. We use MimicGen to generate over 50K demonstrations across 18 tasks with diverse scene configurations, object instances, and robot arms from just ~200 human demonstrations. We show that robot agents can be effectively trained on this generated dataset by imitation learning to achieve strong performance in long-horizon and high-precision tasks, such as multi-part assembly and coffee preparation, across broad initial state distributions. We further demonstrate that the effectiveness and utility of MimicGen data compare favorably to collecting additional human demonstrations, making it a powerful and economical approach towards scaling up robot learning. Datasets, simulation environments, videos, and more at https://mimicgen.github.io .