 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAMMS: Graph based Adversarial Multiagent Modeling Simulator
Feb 04, 2026As intelligent systems and multi-agent coordination become increasingly central to real-world applications, there is a growing need for simulation tools that are both scalable and accessible. Existing high-fidelity simulators, while powerful, are often computationally expensive and ill-suited for rapid prototyping or large-scale agent deployments. We present GAMMS (Graph based Adversarial Multiagent Modeling Simulator), a lightweight yet extensible simulation framework designed to support fast development and evaluation of agent behavior in environments that can be represented as graphs. GAMMS emphasizes five core objectives: scalability, ease of use, integration-first architecture, fast visualization feedback, and real-world grounding. It enables efficient simulation of complex domains such as urban road networks and communication systems, supports integration with external tools (e.g., machine learning libraries, planning solvers), and provides built-in visualization with minimal configuration. GAMMS is agnostic to policy type, supporting heuristic, optimization-based, and learning-based agents, including those using large language models. By lowering the barrier to entry for researchers and enabling high-performance simulations on standard hardware, GAMMS facilitates experimentation and innovation in multi-agent systems, autonomous planning, and adversarial modeling. The framework is open-source and available at https://github.com/GAMMSim/GAMMS/
PIP-LLM: Integrating PDDL-Integer Programming with LLMs for Coordinating Multi-Robot Teams Using Natural Language
Oct 26, 2025Enabling robot teams to execute natural language commands requires translating high-level instructions into feasible, efficient multi-robot plans. While Large Language Models (LLMs) combined with Planning Domain Description Language (PDDL) offer promise for single-robot scenarios, existing approaches struggle with multi-robot coordination due to brittle task decomposition, poor scalability, and low coordination efficiency. We introduce PIP-LLM, a language-based coordination framework that consists of PDDL-based team-level planning and Integer Programming (IP) based robot-level planning. PIP-LLMs first decomposes the command by translating the command into a team-level PDDL problem and solves it to obtain a team-level plan, abstracting away robot assignment. Each team-level action represents a subtask to be finished by the team. Next, this plan is translated into a dependency graph representing the subtasks' dependency structure. Such a dependency graph is then used to guide the robot-level planning, in which each subtask node will be formulated as an IP-based task allocation problem, explicitly optimizing travel costs and workload while respecting robot capabilities and user-defined constraints. This separation of planning from assignment allows PIP-LLM to avoid the pitfalls of syntax-based decomposition and scale to larger teams. Experiments across diverse tasks show that PIP-LLM improves plan success rate, reduces maximum and average travel costs, and achieves better load balancing compared to state-of-the-art baselines.
Latent Weight Diffusion: Generating Policies from Trajectories
Oct 17, 2024With the increasing availability of open-source robotic data, imitation learning has emerged as a viable approach for both robot manipulation and locomotion. Currently, large generalized policies are trained to predict controls or trajectories using diffusion models, which have the desirable property of learning multimodal action distributions. However, generalizability comes with a cost - namely, larger model size and slower inference. Further, there is a known trade-off between performance and action horizon for Diffusion Policy (i.e., diffusing trajectories): fewer diffusion queries accumulate greater trajectory tracking errors. Thus, it is common practice to run these models at high inference frequency, subject to robot computational constraints. To address these limitations, we propose Latent Weight Diffusion (LWD), a method that uses diffusion to learn a distribution over policies for robotic tasks, rather than over trajectories. Our approach encodes demonstration trajectories into a latent space and then decodes them into policies using a hypernetwork. We employ a diffusion denoising model within this latent space to learn its distribution. We demonstrate that LWD can reconstruct the behaviors of the original policies that generated the trajectory dataset. LWD offers the benefits of considerably smaller policy networks during inference and requires fewer diffusion model queries. When tested on the Metaworld MT10 benchmark, LWD achieves a higher success rate compared to a vanilla multi-task policy, while using models up to ~18x smaller during inference. Additionally, since LWD generates closed-loop policies, we show that it outperforms Diffusion Policy in long action horizon settings, with reduced diffusion queries during rollout.
Zero-Shot Generalization of Vision-Based RL Without Data Augmentation
Oct 09, 2024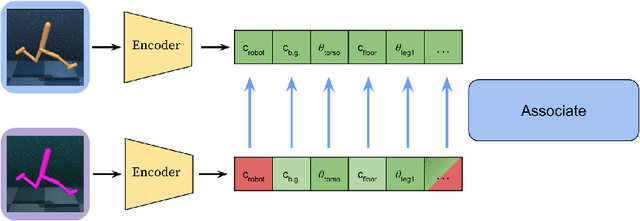
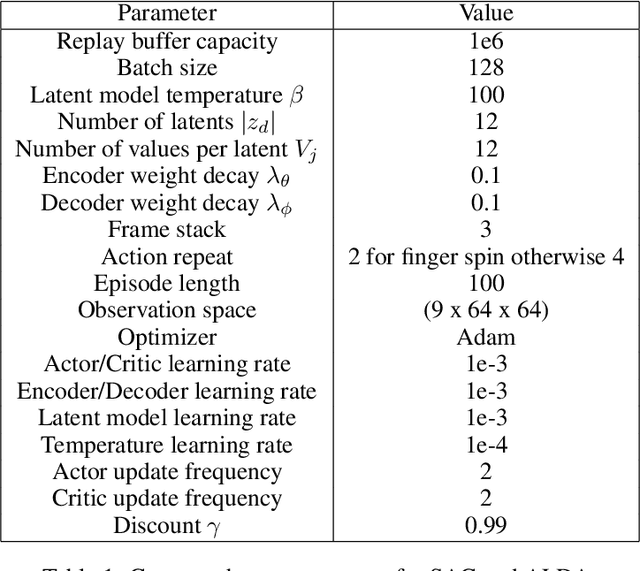
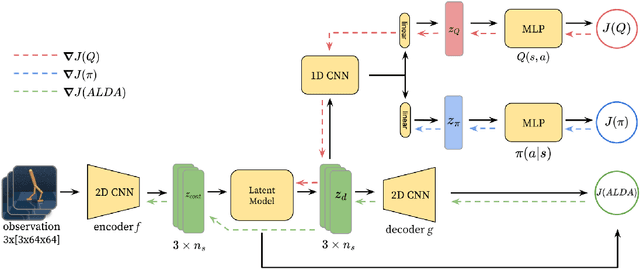
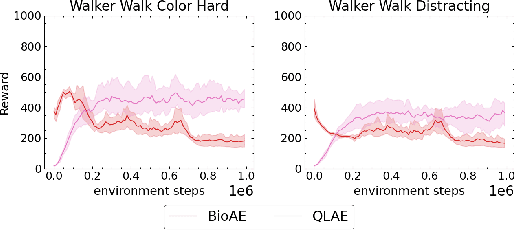
Generalizing vision-based reinforcement learning (RL) agents to novel environments remains a difficult and open challenge. Current trends are to collect large-scale datasets or use data augmentation techniques to prevent overfitting and improve downstream generalization. However, the computational and data collection costs increase exponentially with the number of task variations and can destabilize the already difficult task of training RL agents. In this work, we take inspiration from recent advances in computational neuroscience and propose a model, Associative Latent DisentAnglement (ALDA), that builds on standard off-policy RL towards zero-shot generalization. Specifically, we revisit the role of latent disentanglement in RL and show how combining it with a model of associative memory achieves zero-shot generalization on difficult task variations without relying on data augmentation. Finally, we formally show that data augmentation techniques are a form of weak disentanglement and discuss the implications of this insight.
Resilient and Adaptive Replanning for Multi-Robot Target Tracking with Sensing and Communication Danger Zones
Sep 17, 2024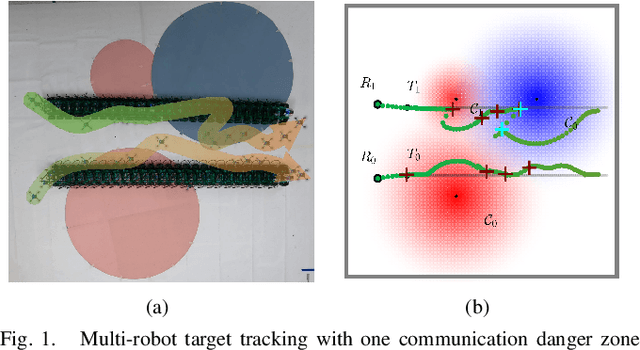
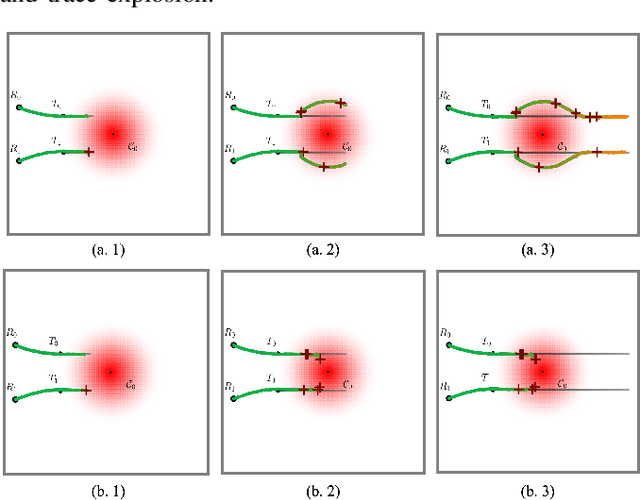
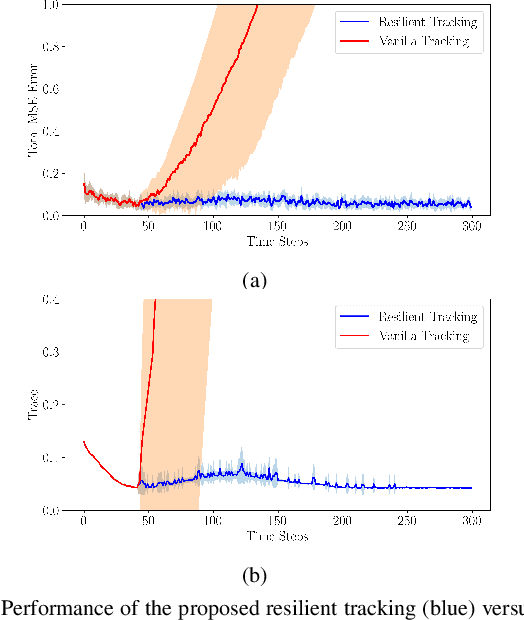
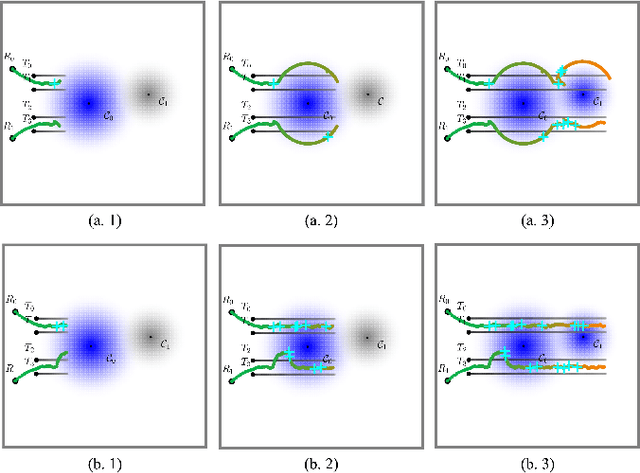
Multi-robot collaboration for target tracking presents significant challenges in hazardous environments, including addressing robot failures, dynamic priority changes, and other unpredictable factors. Moreover, these challenges are increased in adversarial settings if the environment is unknown. In this paper, we propose a resilient and adaptive framework for multi-robot, multi-target tracking in environments with unknown sensing and communication danger zones. The damages posed by these zones are temporary, allowing robots to track targets while accepting the risk of entering dangerous areas. We formulate the problem as an optimization with soft chance constraints, enabling real-time adjustments to robot behavior based on varying types of dangers and failures. An adaptive replanning strategy is introduced, featuring different triggers to improve group performance. This approach allows for dynamic prioritization of target tracking and risk aversion or resilience, depending on evolving resources and real-time conditions. To validate the effectiveness of the proposed method, we benchmark and evaluate it across multiple scenarios in simulation and conduct several real-world experiments.
AutoMate: Specialist and Generalist Assembly Policies over Diverse Geometries
Jul 10, 2024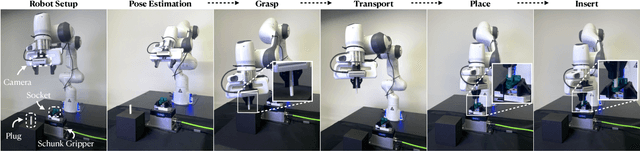

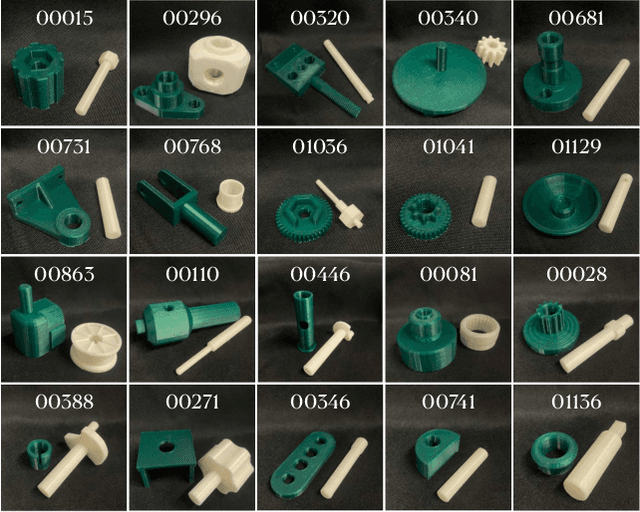

Robotic assembly for high-mixture settings requires adaptivity to diverse parts and poses, which is an open challenge. Meanwhile, in other areas of robotics, large models and sim-to-real have led to tremendous progress. Inspired by such work, we present AutoMate, a learning framework and system that consists of 4 parts: 1) a dataset of 100 assemblies compatible with simulation and the real world, along with parallelized simulation environments for policy learning, 2) a novel simulation-based approach for learning specialist (i.e., part-specific) policies and generalist (i.e., unified) assembly policies, 3) demonstrations of specialist policies that individually solve 80 assemblies with 80% or higher success rates in simulation, as well as a generalist policy that jointly solves 20 assemblies with an 80%+ success rate, and 4) zero-shot sim-to-real transfer that achieves similar (or better) performance than simulation, including on perception-initialized assembly. The key methodological takeaway is that a union of diverse algorithms from manufacturing engineering, character animation, and time-series analysis provides a generic and robust solution for a diverse range of robotic assembly problems.To our knowledge, AutoMate provides the first simulation-based framework for learning specialist and generalist policies over a wide range of assemblies, as well as the first system demonstrating zero-shot sim-to-real transfer over such a range.
Inverse Risk-sensitive Multi-Robot Task Allocation
Jun 14, 2024


We consider a new variant of the multi-robot task allocation problem - Inverse Risk-sensitive Multi-Robot Task Allocation (IR-MRTA). "Forward" MRTA - the process of deciding which robot should perform a task given the reward (cost)-related parameters, is widely studied in the multi-robot literature. In this setting, the reward (cost)-related parameters are assumed to be already known: parameters are first fixed offline by domain experts, followed by coordinating robots online. What if we need these parameters to be adjusted by non-expert human supervisors who oversee the robots during tasks to adapt to new situations? We are interested in the case where the human supervisor's perception of the allocation risk may change and suggest different allocations for robots compared to that from the MRTA algorithm. In such cases, the robots need to change the parameters of the allocation problem based on evolving human preferences. We study such problems through the lens of inverse task allocation, i.e., the process of finding parameters given solutions to the problem. Specifically, we propose a new formulation IR-MRTA, in which we aim to find a new set of parameters of the human behavioral risk model that minimally deviates from the current MRTA parameters and can make a greedy task allocation algorithm allocate robot resources in line with those suggested by humans. We show that even in the simple case such a problem is a non-convex optimization problem. We propose a Branch $\&$ Bound algorithm (BB-IR-MRTA) to solve such problems. In numerical simulations of a case study on multi-robot target capture, we demonstrate how to use BB-IR-MRTA and we show that the proposed algorithm achieves significant advantages in running time and peak memory usage compared to a brute-force baseline.
Active Signal Emitter Placement In Complex Environments
May 04, 2024Placement of electromagnetic signal emitting devices, such as light sources, has important usage in for signal coverage tasks. Automatic placement of these devices is challenging because of the complex interaction of the signal and environment due to reflection, refraction and scattering. In this work, we iteratively improve the placement of these devices by interleaving device placement and sensing actions, correcting errors in the model of the signal propagation. To this end, we propose a novel factor-graph based belief model which combines the measurements taken by the robot and an analytical light propagation model. This model allows accurately modelling the uncertainty of the light propagation with respect to the obstacles, which greatly improves the informative path planning routine. Additionally, we propose a method for determining when to re-plan the emitter placements to balance a trade-off between information about a specific configuration and frequent updating of the configuration. This method incorporates the uncertainty from belief model to adaptively determine when re-configuration is needed. We find that our system has a 9.8% median error reduction compared to a baseline system in simulations in the most difficult environment. We also run on-robot tests and determine that our system performs favorably compared to the baseline.
Multi-Robot Target Tracking with Sensing and Communication Danger Zones
Apr 11, 2024



Multi-robot target tracking finds extensive applications in different scenarios, such as environmental surveillance and wildfire management, which require the robustness of the practical deployment of multi-robot systems in uncertain and dangerous environments. Traditional approaches often focus on the performance of tracking accuracy with no modeling and assumption of the environments, neglecting potential environmental hazards which result in system failures in real-world deployments. To address this challenge, we investigate multi-robot target tracking in the adversarial environment considering sensing and communication attacks with uncertainty. We design specific strategies to avoid different danger zones and proposed a multi-agent tracking framework under the perilous environment. We approximate the probabilistic constraints and formulate practical optimization strategies to address computational challenges efficiently. We evaluate the performance of our proposed methods in simulations to demonstrate the ability of robots to adjust their risk-aware behaviors under different levels of environmental uncertainty and risk confidence. The proposed method is further validated via real-world robot experiments where a team of drones successfully track dynamic ground robots while being risk-aware of the sensing and/or communication danger zones.
From Words to Routes: Applying Large Language Models to Vehicle Routing
Mar 16, 2024



LLMs have shown impressive progress in robotics (e.g., manipulation and navigation) with natural language task descriptions. The success of LLMs in these tasks leads us to wonder: What is the ability of LLMs to solve vehicle routing problems (VRPs) with natural language task descriptions? In this work, we study this question in three steps. First, we construct a dataset with 21 types of single- or multi-vehicle routing problems. Second, we evaluate the performance of LLMs across four basic prompt paradigms of text-to-code generation, each involving different types of text input. We find that the basic prompt paradigm, which generates code directly from natural language task descriptions, performs the best for GPT-4, achieving 56% feasibility, 40% optimality, and 53% efficiency. Third, based on the observation that LLMs may not be able to provide correct solutions at the initial attempt, we propose a framework that enables LLMs to refine solutions through self-reflection, including self-debugging and self-verification. With GPT-4, our proposed framework achieves a 16% increase in feasibility, a 7% increase in optimality, and a 15% increase in efficiency. Moreover, we examine the sensitivity of GPT-4 to task descriptions, specifically focusing on how its performance changes when certain details are omitted from the task descriptions, yet the core meaning is preserved. Our findings reveal that such omissions lead to a notable decrease in performance: 4% in feasibility, 4% in optimality, and 5% in efficiency. Website: https://sites.google.com/view/words-to-routes/