 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Feb 06, 2026Being able to simulate the outcomes of actions in varied environments will revolutionize the development of generalist agents at scale. However, modeling these world dynamics, especially for dexterous robotics tasks, poses significant challenges due to limited data coverage and scarce action labels. As an endeavor towards this end, we introduce DreamDojo, a foundation world model that learns diverse interactions and dexterous controls from 44k hours of egocentric human videos. Our data mixture represents the largest video dataset to date for world model pretraining, spanning a wide range of daily scenarios with diverse objects and skills. To address the scarcity of action labels, we introduce continuous latent actions as unified proxy actions, enhancing interaction knowledge transfer from unlabeled videos. After post-training on small-scale target robot data, DreamDojo demonstrates a strong understanding of physics and precise action controllability. We also devise a distillation pipeline that accelerates DreamDojo to a real-time speed of 10.81 FPS and further improves context consistency. Our work enables several important applications based on generative world models, including live teleoperation, policy evaluation, and model-based planning. Systematic evaluation on multiple challenging out-of-distribution (OOD) benchmarks verifies the significance of our method for simulating open-world, contact-rich tasks, paving the way for general-purpose robot world models.
Meta-World+: An Improved, Standardized, RL Benchmark
May 16, 2025Meta-World is widely used for evaluating multi-task and meta-reinforcement learning agents, which are challenged to master diverse skills simultaneously. Since its introduction however, there have been numerous undocumented changes which inhibit a fair comparison of algorithms. This work strives to disambiguate these results from the literature, while also leveraging the past versions of Meta-World to provide insights into multi-task and meta-reinforcement learning benchmark design. Through this process we release a new open-source version of Meta-World (https://github.com/Farama-Foundation/Metaworld/) that has full reproducibility of past results, is more technically ergonomic, and gives users more control over the tasks that are included in a task set.
Guaranteed Trust Region Optimization via Two-Phase KL Penalization
Dec 08, 2023



On-policy reinforcement learning (RL) has become a popular framework for solving sequential decision problems due to its computational efficiency and theoretical simplicity. Some on-policy methods guarantee every policy update is constrained to a trust region relative to the prior policy to ensure training stability. These methods often require computationally intensive non-linear optimization or require a particular form of action distribution. In this work, we show that applying KL penalization alone is nearly sufficient to enforce such trust regions. Then, we show that introducing a "fixup" phase is sufficient to guarantee a trust region is enforced on every policy update while adding fewer than 5% additional gradient steps in practice. The resulting algorithm, which we call FixPO, is able to train a variety of policy architectures and action spaces, is easy to implement, and produces results competitive with other trust region methods.
Conditionally Combining Robot Skills using Large Language Models
Oct 25, 2023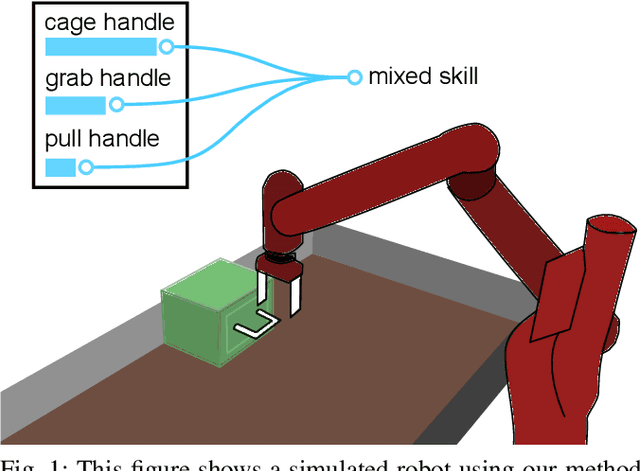
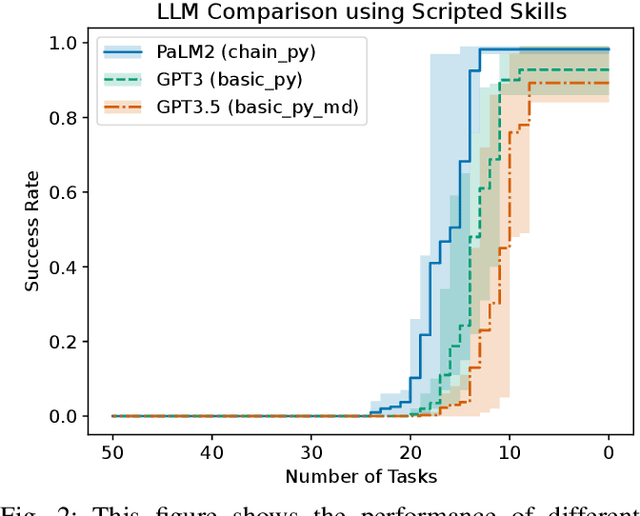

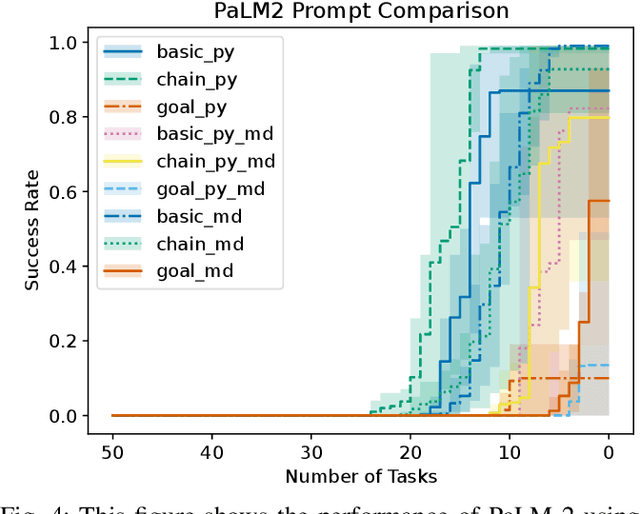
This paper combines two contributions. First, we introduce an extension of the Meta-World benchmark, which we call "Language-World," which allows a large language model to operate in a simulated robotic environment using semi-structured natural language queries and scripted skills described using natural language. By using the same set of tasks as Meta-World, Language-World results can be easily compared to Meta-World results, allowing for a point of comparison between recent methods using Large Language Models (LLMs) and those using Deep Reinforcement Learning. Second, we introduce a method we call Plan Conditioned Behavioral Cloning (PCBC), that allows finetuning the behavior of high-level plans using end-to-end demonstrations. Using Language-World, we show that PCBC is able to achieve strong performance in a variety of few-shot regimes, often achieving task generalization with as little as a single demonstration. We have made Language-World available as open-source software at https://github.com/krzentner/language-world/.
Generating Behaviorally Diverse Policies with Latent Diffusion Models
May 30, 2023Recent progress in Quality Diversity Reinforcement Learning (QD-RL) has enabled learning a collection of behaviorally diverse, high performing policies. However, these methods typically involve storing thousands of policies, which results in high space-complexity and poor scaling to additional behaviors. Condensing the archive into a single model while retaining the performance and coverage of the original collection of policies has proved challenging. In this work, we propose using diffusion models to distill the archive into a single generative model over policy parameters. We show that our method achieves a compression ratio of 13x while recovering 98% of the original rewards and 89% of the original coverage. Further, the conditioning mechanism of diffusion models allows for flexibly selecting and sequencing behaviors, including using language. Project website: https://sites.google.com/view/policydiffusion/home
A Simple Approach to Continual Learning by Transferring Skill Parameters
Oct 19, 2021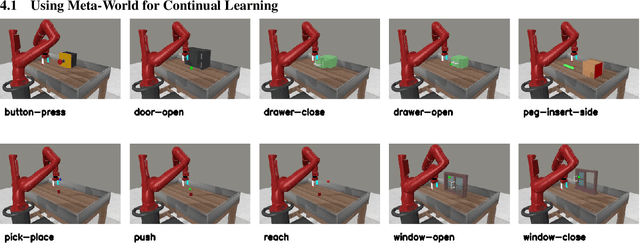
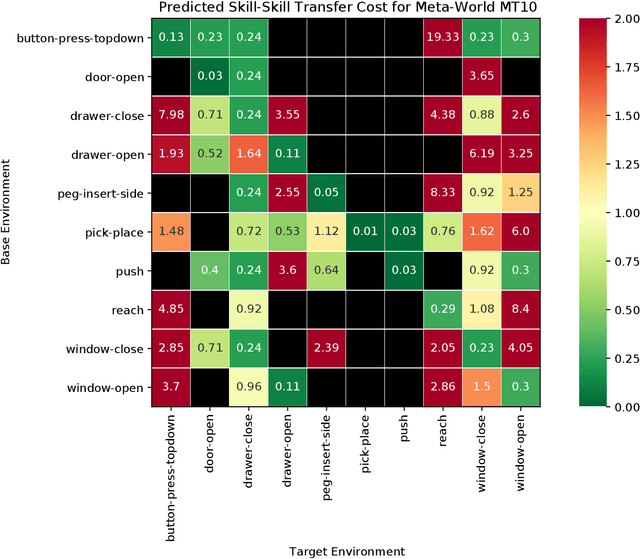
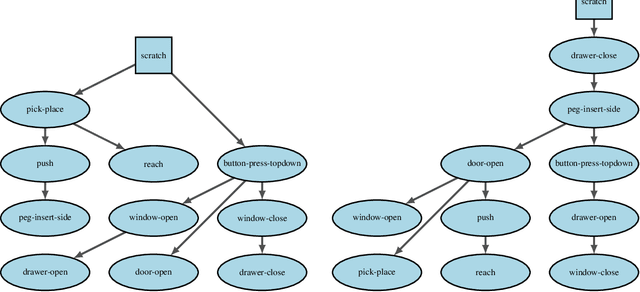
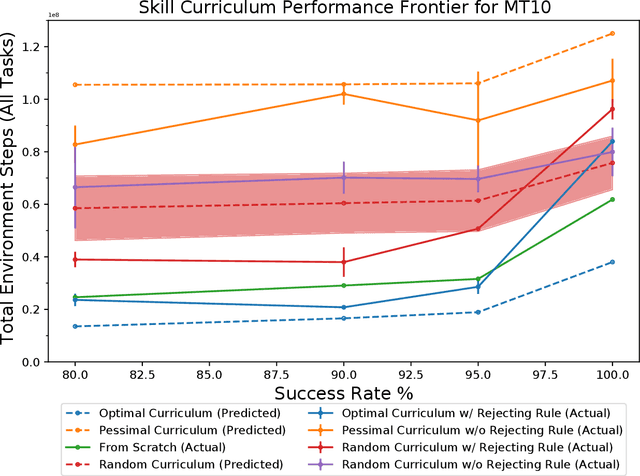
In order to be effective general purpose machines in real world environments, robots not only will need to adapt their existing manipulation skills to new circumstances, they will need to acquire entirely new skills on-the-fly. A great promise of continual learning is to endow robots with this ability, by using their accumulated knowledge and experience from prior skills. We take a fresh look at this problem, by considering a setting in which the robot is limited to storing that knowledge and experience only in the form of learned skill policies. We show that storing skill policies, careful pre-training, and appropriately choosing when to transfer those skill policies is sufficient to build a continual learner in the context of robotic manipulation. We analyze which conditions are needed to transfer skills in the challenging Meta-World simulation benchmark. Using this analysis, we introduce a pair-wise metric relating skills that allows us to predict the effectiveness of skill transfer between tasks, and use it to reduce the problem of continual learning to curriculum selection. Given an appropriate curriculum, we show how to continually acquire robotic manipulation skills without forgetting, and using far fewer samples than needed to train them from scratch.
Towards Exploiting Geometry and Time for Fast Off-Distribution Adaptation in Multi-Task Robot Learning
Jun 29, 2021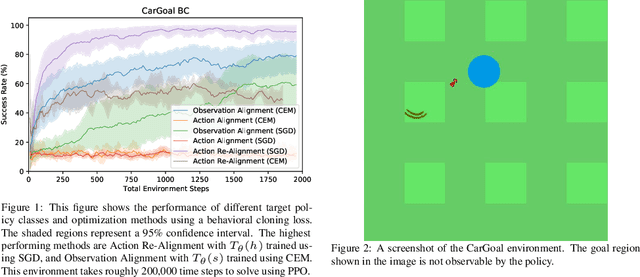
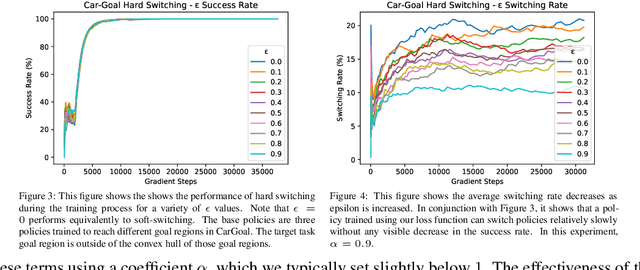
We explore possible methods for multi-task transfer learning which seek to exploit the shared physical structure of robotics tasks. Specifically, we train policies for a base set of pre-training tasks, then experiment with adapting to new off-distribution tasks, using simple architectural approaches for re-using these policies as black-box priors. These approaches include learning an alignment of either the observation space or action space from a base to a target task to exploit rigid body structure, and methods for learning a time-domain switching policy across base tasks which solves the target task, to exploit temporal coherence. We find that combining low-complexity target policy classes, base policies as black-box priors, and simple optimization algorithms allows us to acquire new tasks outside the base task distribution, using small amounts of offline training data.