 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Visual Generalization in Robot Manipulation
May 16, 2025Training vision-based manipulation policies that are robust across diverse visual environments remains an important and unresolved challenge in robot learning. Current approaches often sidestep the problem by relying on invariant representations such as point clouds and depth, or by brute-forcing generalization through visual domain randomization and/or large, visually diverse datasets. Disentangled representation learning - especially when combined with principles of associative memory - has recently shown promise in enabling vision-based reinforcement learning policies to be robust to visual distribution shifts. However, these techniques have largely been constrained to simpler benchmarks and toy environments. In this work, we scale disentangled representation learning and associative memory to more visually and dynamically complex manipulation tasks and demonstrate zero-shot adaptability to visual perturbations in both simulation and on real hardware. We further extend this approach to imitation learning, specifically Diffusion Policy, and empirically show significant gains in visual generalization compared to state-of-the-art imitation learning methods. Finally, we introduce a novel technique adapted from the model equivariance literature that transforms any trained neural network policy into one invariant to 2D planar rotations, making our policy not only visually robust but also resilient to certain camera perturbations. We believe that this work marks a significant step towards manipulation policies that are not only adaptable out of the box, but also robust to the complexities and dynamical nature of real-world deployment. Supplementary videos are available at https://sites.google.com/view/vis-gen-robotics/home.
Zero-Shot Generalization of Vision-Based RL Without Data Augmentation
Oct 09, 2024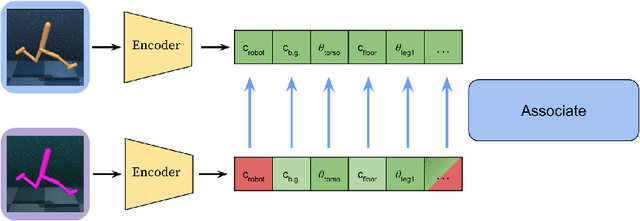
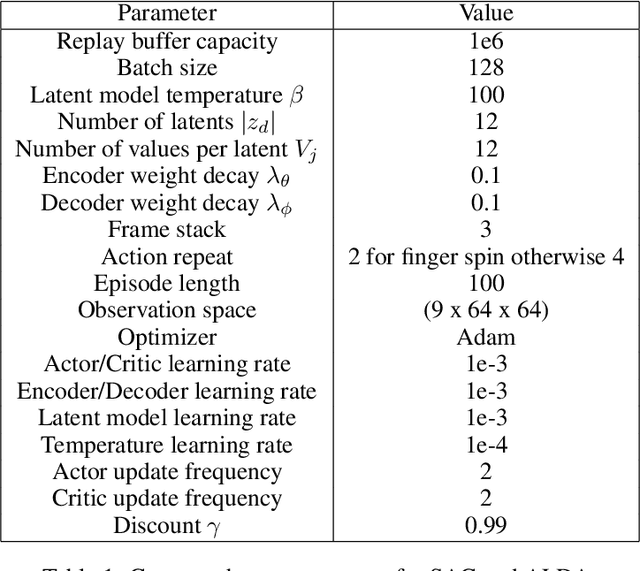
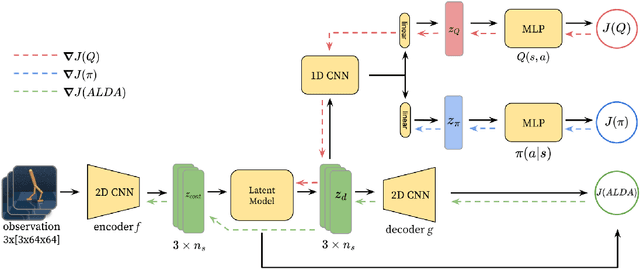
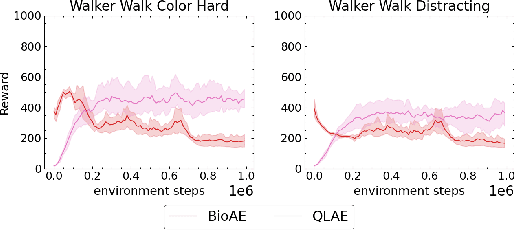
Generalizing vision-based reinforcement learning (RL) agents to novel environments remains a difficult and open challenge. Current trends are to collect large-scale datasets or use data augmentation techniques to prevent overfitting and improve downstream generalization. However, the computational and data collection costs increase exponentially with the number of task variations and can destabilize the already difficult task of training RL agents. In this work, we take inspiration from recent advances in computational neuroscience and propose a model, Associative Latent DisentAnglement (ALDA), that builds on standard off-policy RL towards zero-shot generalization. Specifically, we revisit the role of latent disentanglement in RL and show how combining it with a model of associative memory achieves zero-shot generalization on difficult task variations without relying on data augmentation. Finally, we formally show that data augmentation techniques are a form of weak disentanglement and discuss the implications of this insight.
Collision Avoidance and Navigation for a Quadrotor Swarm Using End-to-end Deep Reinforcement Learning
Sep 23, 2023End-to-end deep reinforcement learning (DRL) for quadrotor control promises many benefits -- easy deployment, task generalization and real-time execution capability. Prior end-to-end DRL-based methods have showcased the ability to deploy learned controllers onto single quadrotors or quadrotor teams maneuvering in simple, obstacle-free environments. However, the addition of obstacles increases the number of possible interactions exponentially, thereby increasing the difficulty of training RL policies. In this work, we propose an end-to-end DRL approach to control quadrotor swarms in environments with obstacles. We provide our agents a curriculum and a replay buffer of the clipped collision episodes to improve performance in obstacle-rich environments. We implement an attention mechanism to attend to the neighbor robots and obstacle interactions - the first successful demonstration of this mechanism on policies for swarm behavior deployed on severely compute-constrained hardware. Our work is the first work that demonstrates the possibility of learning neighbor-avoiding and obstacle-avoiding control policies trained with end-to-end DRL that transfers zero-shot to real quadrotors. Our approach scales to 32 robots with 80% obstacle density in simulation and 8 robots with 20% obstacle density in physical deployment. Video demonstrations are available on the project website at: https://sites.google.com/view/obst-avoid-swarm-rl.
QuadSwarm: A Modular Multi-Quadrotor Simulator for Deep Reinforcement Learning with Direct Thrust Control
Jun 15, 2023Reinforcement learning (RL) has shown promise in creating robust policies for robotics tasks. However, contemporary RL algorithms are data-hungry, often requiring billions of environment transitions to train successful policies. This necessitates the use of fast and highly-parallelizable simulators. In addition to speed, such simulators need to model the physics of the robots and their interaction with the environment to a level acceptable for transferring policies learned in simulation to reality. We present QuadSwarm, a fast, reliable simulator for research in single and multi-robot RL for quadrotors that addresses both issues. QuadSwarm, with fast forward-dynamics propagation decoupled from rendering, is designed to be highly parallelizable such that throughput scales linearly with additional compute. It provides multiple components tailored toward multi-robot RL, including diverse training scenarios, and provides domain randomization to facilitate the development and sim2real transfer of multi-quadrotor control policies. Initial experiments suggest that QuadSwarm achieves over 48,500 simulation samples per second (SPS) on a single quadrotor and over 62,000 SPS on eight quadrotors on a 16-core CPU. The code can be found in https://github.com/Zhehui-Huang/quad-swarm-rl.
Generating Behaviorally Diverse Policies with Latent Diffusion Models
May 30, 2023Recent progress in Quality Diversity Reinforcement Learning (QD-RL) has enabled learning a collection of behaviorally diverse, high performing policies. However, these methods typically involve storing thousands of policies, which results in high space-complexity and poor scaling to additional behaviors. Condensing the archive into a single model while retaining the performance and coverage of the original collection of policies has proved challenging. In this work, we propose using diffusion models to distill the archive into a single generative model over policy parameters. We show that our method achieves a compression ratio of 13x while recovering 98% of the original rewards and 89% of the original coverage. Further, the conditioning mechanism of diffusion models allows for flexibly selecting and sequencing behaviors, including using language. Project website: https://sites.google.com/view/policydiffusion/home
Proximal Policy Gradient Arborescence for Quality Diversity Reinforcement Learning
May 23, 2023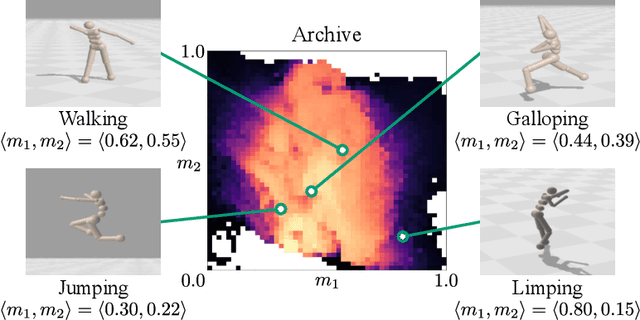
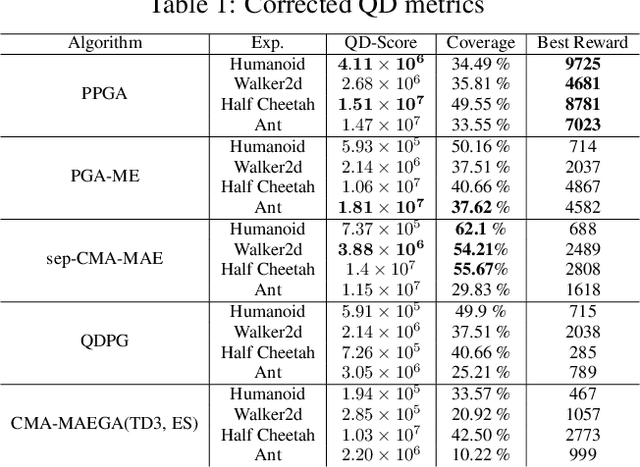
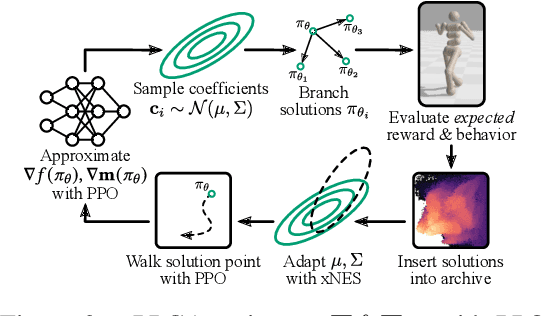
Training generally capable agents that perform well in unseen dynamic environments is a long-term goal of robot learning. Quality Diversity Reinforcement Learning (QD-RL) is an emerging class of reinforcement learning (RL) algorithms that blend insights from Quality Diversity (QD) and RL to produce a collection of high performing and behaviorally diverse policies with respect to a behavioral embedding. Existing QD-RL approaches have thus far taken advantage of sample-efficient off-policy RL algorithms. However, recent advances in high-throughput, massively parallelized robotic simulators have opened the door for algorithms that can take advantage of such parallelism, and it is unclear how to scale existing off-policy QD-RL methods to these new data-rich regimes. In this work, we take the first steps to combine on-policy RL methods, specifically Proximal Policy Optimization (PPO), that can leverage massive parallelism, with QD, and propose a new QD-RL method with these high-throughput simulators and on-policy training in mind. Our proposed Proximal Policy Gradient Arborescence (PPGA) algorithm yields a 4x improvement over baselines on the challenging humanoid domain.
Decentralized Control of Quadrotor Swarms with End-to-end Deep Reinforcement Learning
Sep 16, 2021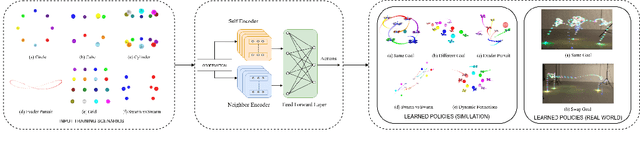
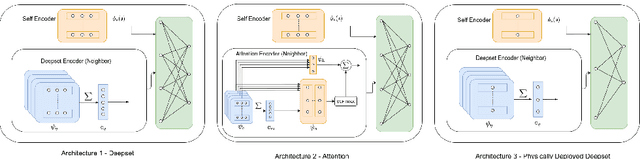

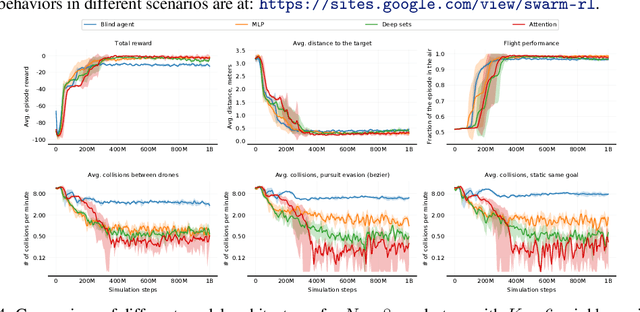
We demonstrate the possibility of learning drone swarm controllers that are zero-shot transferable to real quadrotors via large-scale multi-agent end-to-end reinforcement learning. We train policies parameterized by neural networks that are capable of controlling individual drones in a swarm in a fully decentralized manner. Our policies, trained in simulated environments with realistic quadrotor physics, demonstrate advanced flocking behaviors, perform aggressive maneuvers in tight formations while avoiding collisions with each other, break and re-establish formations to avoid collisions with moving obstacles, and efficiently coordinate in pursuit-evasion tasks. We analyze, in simulation, how different model architectures and parameters of the training regime influence the final performance of neural swarms. We demonstrate the successful deployment of the model learned in simulation to highly resource-constrained physical quadrotors performing stationkeeping and goal swapping behaviors. Code and video demonstrations are available at the project website https://sites.google.com/view/swarm-rl.
Augmented Reality for Human-Swarm Interaction in a Swarm-Robotic Chemistry Simulation
Dec 02, 2019


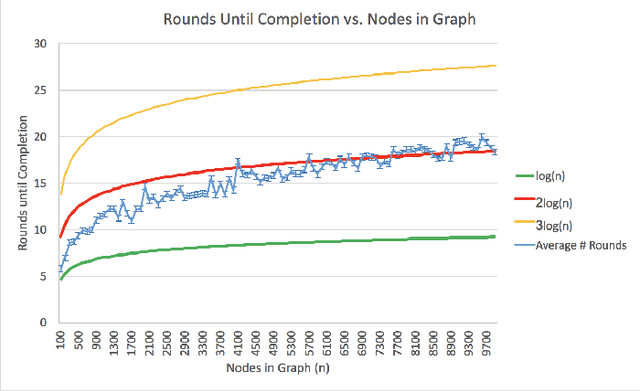
We present a method to register individual members of a robotic swarm in an augmented reality display while showing relevant information about swarm dynamics to the user that would be otherwise hidden. Individual swarm members and clusters of the same group are identified by their color, and by blinking at a specific time interval that is distinct from the time interval at which their neighbors blink. We show that this problem is an instance of the graph coloring problem, which can be solved in a distributed manner in O(log(n)) time. We demonstrate our approach using a swarm chemistry simulation in which robots simulate individual atoms that form molecules following the rules of chemistry. Augmented reality is then used to display information about the internal state of individual swarm members as well as their topological relationship, corresponding to molecular bonds.