 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRed-Teaming Vision-Language-Action Models via Quality Diversity Prompt Generation for Robust Robot Policies
Mar 12, 2026Vision-Language-Action (VLA) models have significant potential to enable general-purpose robotic systems for a range of vision-language tasks. However, the performance of VLA-based robots is highly sensitive to the precise wording of language instructions, and it remains difficult to predict when such robots will fail. To improve the robustness of VLAs to different wordings, we present Q-DIG (Quality Diversity for Diverse Instruction Generation), which performs red-teaming by scalably identifying diverse natural language task descriptions that induce failures while remaining task-relevant. Q-DIG integrates Quality Diversity (QD) techniques with Vision-Language Models (VLMs) to generate a broad spectrum of adversarial instructions that expose meaningful vulnerabilities in VLA behavior. Our results across multiple simulation benchmarks show that Q-DIG finds more diverse and meaningful failure modes compared to baseline methods, and that fine-tuning VLAs on the generated instructions improves task success rates. Furthermore, results from a user study highlight that Q-DIG generates prompts judged to be more natural and human-like than those from baselines. Finally, real-world evaluations of Q-DIG prompts show results consistent with simulation, and fine-tuning VLAs on the generated prompts further success rates on unseen instructions. Together, these findings suggest that Q-DIG is a promising approach for identifying vulnerabilities and improving the robustness of VLA-based robots. Our anonymous project website is at qdigvla.github.io.
Discount Model Search for Quality Diversity Optimization in High-Dimensional Measure Spaces
Jan 03, 2026Quality diversity (QD) optimization searches for a collection of solutions that optimize an objective while attaining diverse outputs of a user-specified, vector-valued measure function. Contemporary QD algorithms focus on low-dimensional measures because high-dimensional measures are prone to distortion, where many solutions found by the QD algorithm map to similar measures. For example, the CMA-MAE algorithm guides measure space exploration with a histogram in measure space that records so-called discount values. However, CMA-MAE stagnates in domains with high-dimensional measure spaces because solutions with similar measures fall into the same histogram cell and thus receive identical discount values. To address these limitations, we propose Discount Model Search (DMS), which guides exploration with a model that provides a smooth, continuous representation of discount values. In high-dimensional measure spaces, this model enables DMS to distinguish between solutions with similar measures and thus continue exploration. We show that DMS facilitates new QD applications by introducing two domains where the measure space is the high-dimensional space of images, which enables users to specify their desired measures by providing a dataset of images rather than hand-designing the measure function. Results in these domains and on high-dimensional benchmarks show that DMS outperforms CMA-MAE and other black-box QD algorithms.
Density Descent for Diversity Optimization
Dec 18, 2023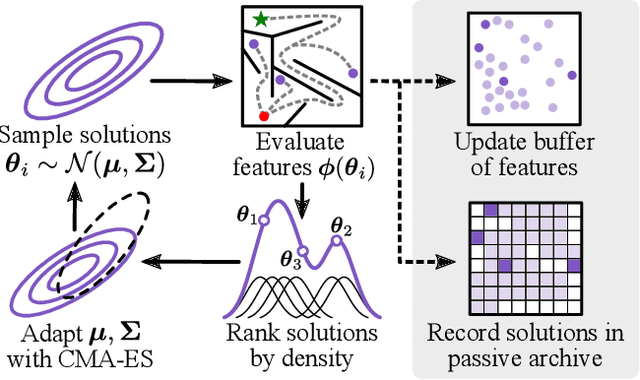
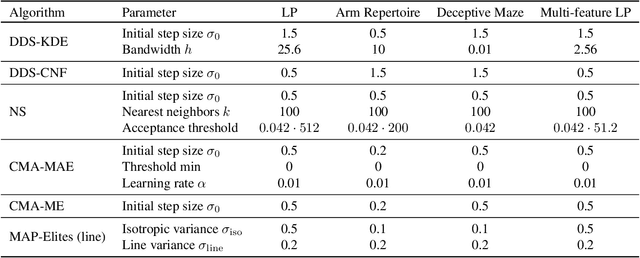
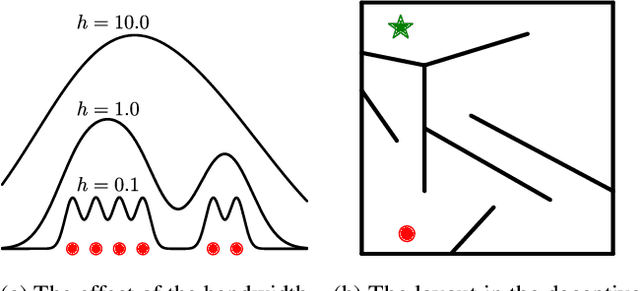
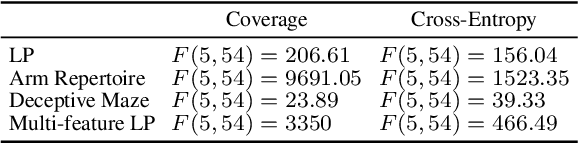
Diversity optimization seeks to discover a set of solutions that elicit diverse features. Prior work has proposed Novelty Search (NS), which, given a current set of solutions, seeks to expand the set by finding points in areas of low density in the feature space. However, to estimate density, NS relies on a heuristic that considers the k-nearest neighbors of the search point in the feature space, which yields a weaker stability guarantee. We propose Density Descent Search (DDS), an algorithm that explores the feature space via gradient descent on a continuous density estimate of the feature space that also provides stronger stability guarantee. We experiment with DDS and two density estimation methods: kernel density estimation (KDE) and continuous normalizing flow (CNF). On several standard diversity optimization benchmarks, DDS outperforms NS, the recently proposed MAP-Annealing algorithm, and other state-of-the-art baselines. Additionally, we prove that DDS with KDE provides stronger stability guarantees than NS, making it more suitable for adaptive optimizers. Furthermore, we prove that NS is a special case of DDS that descends a KDE of the feature space.
Proximal Policy Gradient Arborescence for Quality Diversity Reinforcement Learning
May 23, 2023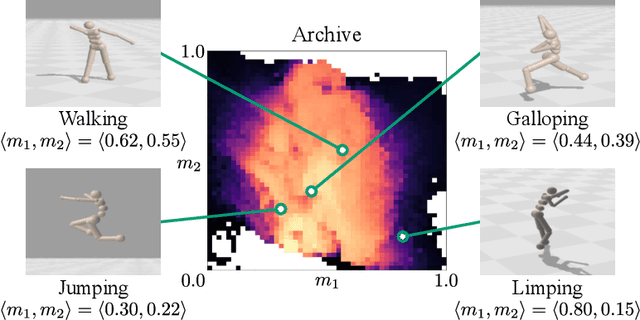
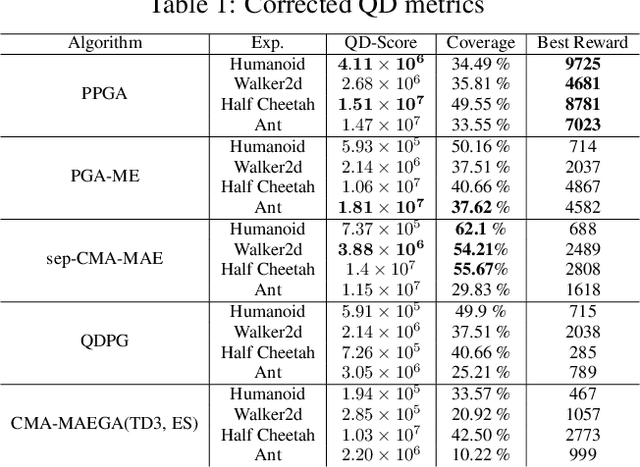
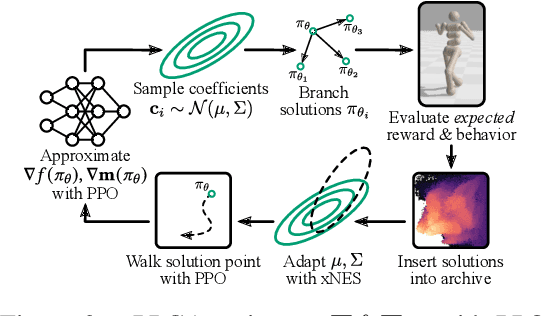
Training generally capable agents that perform well in unseen dynamic environments is a long-term goal of robot learning. Quality Diversity Reinforcement Learning (QD-RL) is an emerging class of reinforcement learning (RL) algorithms that blend insights from Quality Diversity (QD) and RL to produce a collection of high performing and behaviorally diverse policies with respect to a behavioral embedding. Existing QD-RL approaches have thus far taken advantage of sample-efficient off-policy RL algorithms. However, recent advances in high-throughput, massively parallelized robotic simulators have opened the door for algorithms that can take advantage of such parallelism, and it is unclear how to scale existing off-policy QD-RL methods to these new data-rich regimes. In this work, we take the first steps to combine on-policy RL methods, specifically Proximal Policy Optimization (PPO), that can leverage massive parallelism, with QD, and propose a new QD-RL method with these high-throughput simulators and on-policy training in mind. Our proposed Proximal Policy Gradient Arborescence (PPGA) algorithm yields a 4x improvement over baselines on the challenging humanoid domain.
Surrogate Assisted Generation of Human-Robot Interaction Scenarios
May 11, 2023



As human-robot interaction (HRI) systems advance, so does the difficulty of evaluating and understanding the strengths and limitations of these systems in different environments and with different users. To this end, previous methods have algorithmically generated diverse scenarios that reveal system failures in a shared control teleoperation task. However, these methods require directly evaluating generated scenarios by simulating robot policies and human actions. The computational cost of these evaluations limits their applicability in more complex domains. Thus, we propose augmenting scenario generation systems with surrogate models that predict both human and robot behaviors. In the shared control teleoperation domain and a more complex shared workspace collaboration task, we show that surrogate assisted scenario generation efficiently synthesizes diverse datasets of challenging scenarios. We demonstrate that these failures are reproducible in real-world interactions.
pyribs: A Bare-Bones Python Library for Quality Diversity Optimization
Mar 01, 2023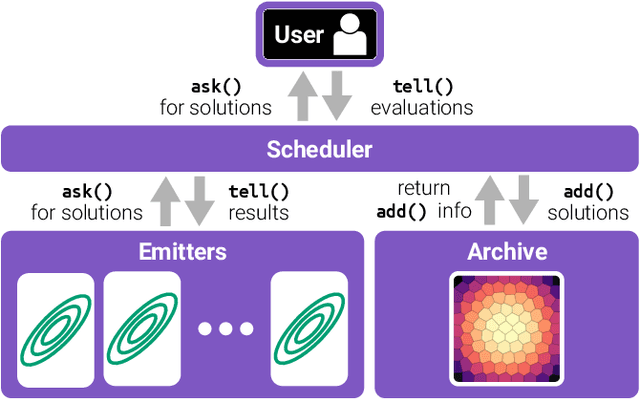
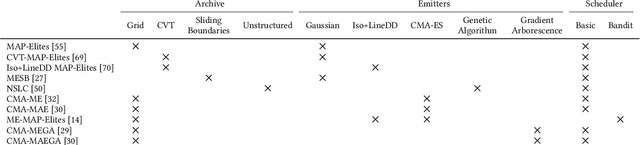
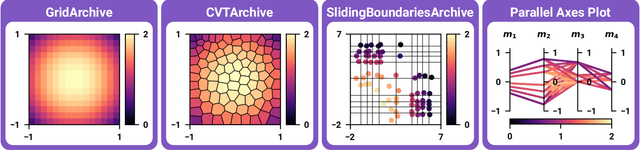
Recent years have seen a rise in the popularity of quality diversity (QD) optimization, a branch of optimization that seeks to find a collection of diverse, high-performing solutions to a given problem. To grow further, we believe the QD community faces two challenges: developing a framework to represent the field's growing array of algorithms, and implementing that framework in software that supports a range of researchers and practitioners. To address these challenges, we have developed pyribs, a library built on a highly modular conceptual QD framework. By replacing components in the conceptual framework, and hence in pyribs, users can compose algorithms from across the QD literature; equally important, they can identify unexplored algorithm variations. Furthermore, pyribs makes this framework simple, flexible, and accessible, with a user-friendly API supported by extensive documentation and tutorials. This paper overviews the creation of pyribs, focusing on the conceptual framework that it implements and the design principles that have guided the library's development.
Training Diverse High-Dimensional Controllers by Scaling Covariance Matrix Adaptation MAP-Annealing
Oct 06, 2022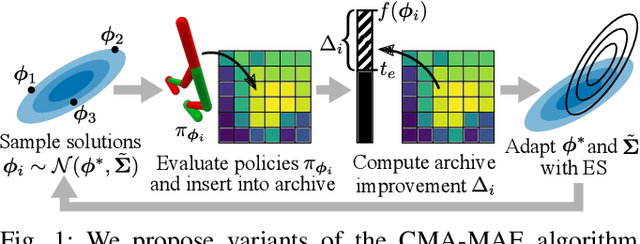

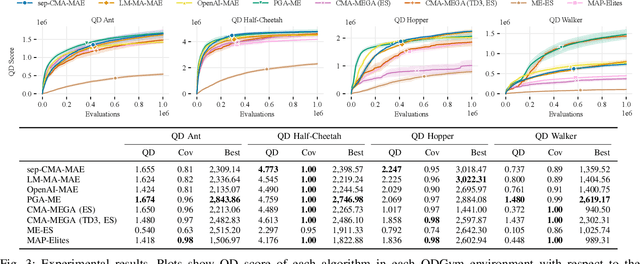
Pre-training a diverse set of robot controllers in simulation has enabled robots to adapt online to damage in robot locomotion tasks. However, finding diverse, high-performing controllers requires specialized hardware and extensive tuning of a large number of hyperparameters. On the other hand, the Covariance Matrix Adaptation MAP-Annealing algorithm, an evolution strategies (ES)-based quality diversity algorithm, does not have these limitations and has been shown to achieve state-of-the-art performance in standard benchmark domains. However, CMA-MAE cannot scale to modern neural network controllers due to its quadratic complexity. We leverage efficient approximation methods in ES to propose three new CMA-MAE variants that scale to very high dimensions. Our experiments show that the variants outperform ES-based baselines in benchmark robotic locomotion tasks, while being comparable with state-of-the-art deep reinforcement learning-based quality diversity algorithms. Source code and videos are available at https://scalingcmamae.github.io
Deep Surrogate Assisted Generation of Environments
Jun 14, 2022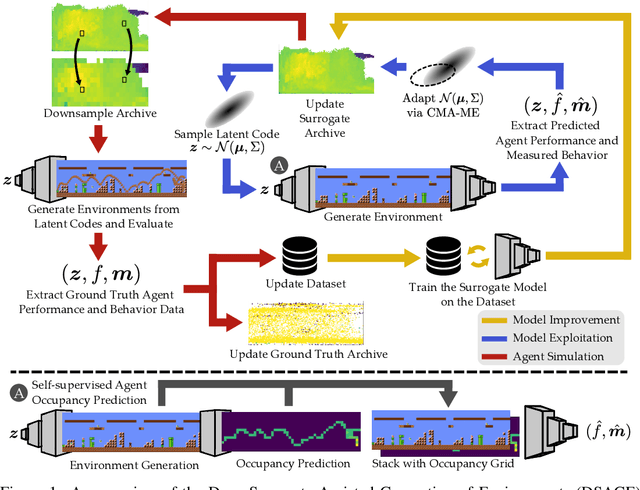
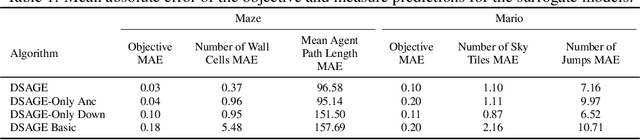
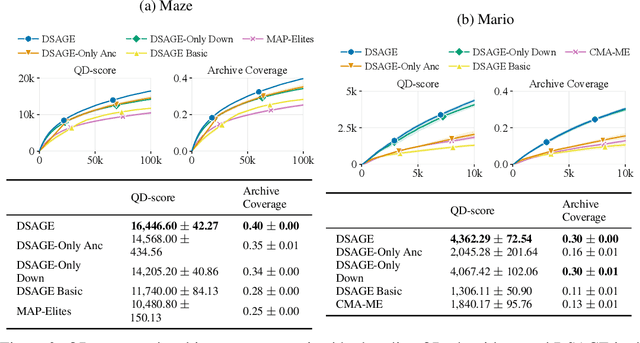

Recent progress in reinforcement learning (RL) has started producing generally capable agents that can solve a distribution of complex environments. These agents are typically tested on fixed, human-authored environments. On the other hand, quality diversity (QD) optimization has been proven to be an effective component of environment generation algorithms, which can generate collections of high-quality environments that are diverse in the resulting agent behaviors. However, these algorithms require potentially expensive simulations of agents on newly generated environments. We propose Deep Surrogate Assisted Generation of Environments (DSAGE), a sample-efficient QD environment generation algorithm that maintains a deep surrogate model for predicting agent behaviors in new environments. Results in two benchmark domains show that DSAGE significantly outperforms existing QD environment generation algorithms in discovering collections of environments that elicit diverse behaviors of a state-of-the-art RL agent and a planning agent.
Approximating Gradients for Differentiable Quality Diversity in Reinforcement Learning
Feb 08, 2022

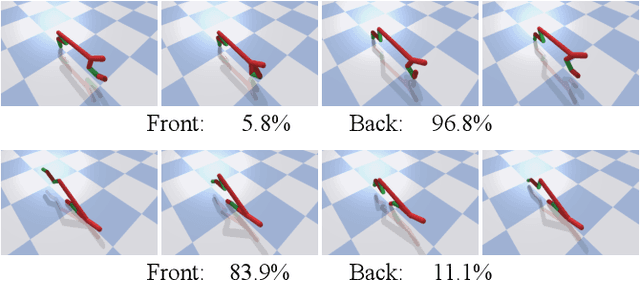

Consider a walking agent that must adapt to damage. To approach this task, we can train a collection of policies and have the agent select a suitable policy when damaged. Training this collection may be viewed as a quality diversity (QD) optimization problem, where we search for solutions (policies) which maximize an objective (walking forward) while spanning a set of measures (measurable characteristics). Recent work shows that differentiable quality diversity (DQD) algorithms greatly accelerate QD optimization when exact gradients are available for the objective and measures. However, such gradients are typically unavailable in RL settings due to non-differentiable environments. To apply DQD in RL settings, we propose to approximate objective and measure gradients with evolution strategies and actor-critic methods. We develop two variants of the DQD algorithm CMA-MEGA, each with different gradient approximations, and evaluate them on four simulated walking tasks. One variant achieves comparable performance (QD score) with the state-of-the-art PGA-MAP-Elites in two tasks. The other variant performs comparably in all tasks but is less efficient than PGA-MAP-Elites in two tasks. These results provide insight into the limitations of CMA-MEGA in domains that require rigorous optimization of the objective and where exact gradients are unavailable.
On the Importance of Environments in Human-Robot Coordination
Jun 28, 2021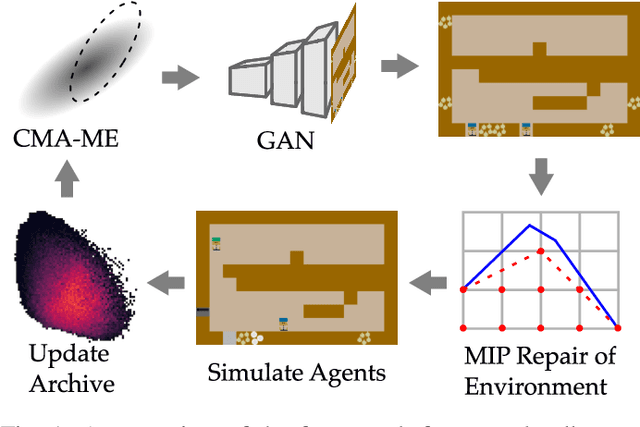


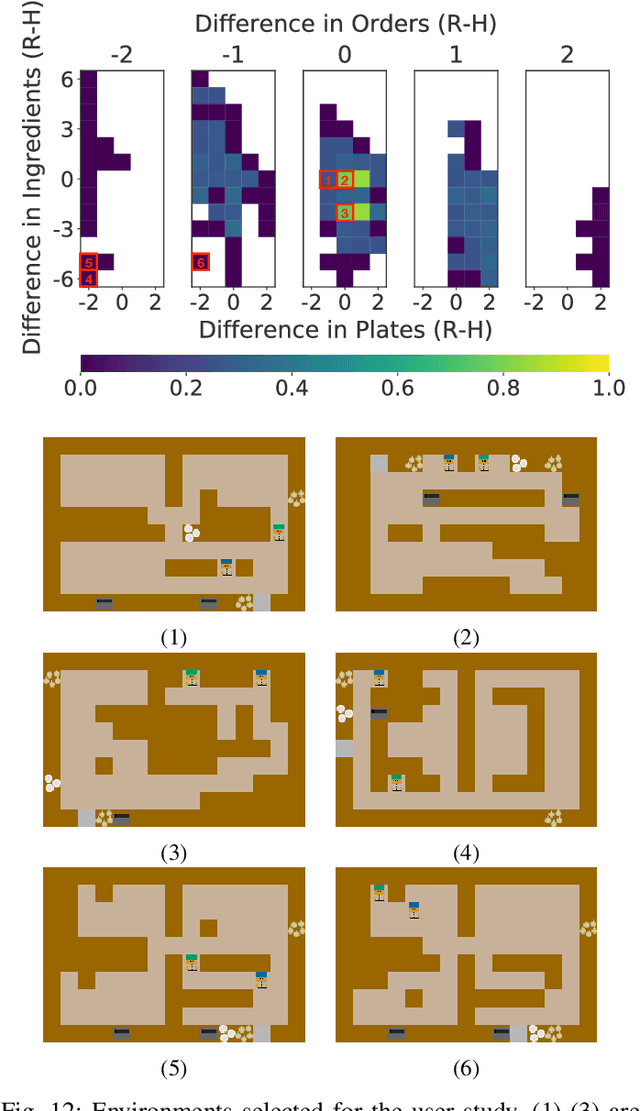
When studying robots collaborating with humans, much of the focus has been on robot policies that coordinate fluently with human teammates in collaborative tasks. However, less emphasis has been placed on the effect of the environment on coordination behaviors. To thoroughly explore environments that result in diverse behaviors, we propose a framework for procedural generation of environments that are (1) stylistically similar to human-authored environments, (2) guaranteed to be solvable by the human-robot team, and (3) diverse with respect to coordination measures. We analyze the procedurally generated environments in the Overcooked benchmark domain via simulation and an online user study. Results show that the environments result in qualitatively different emerging behaviors and statistically significant differences in collaborative fluency metrics, even when the robot runs the same planning algorithm.