 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Policy Gradient Arborescence for Quality Diversity Reinforcement Learning
Paper and Code
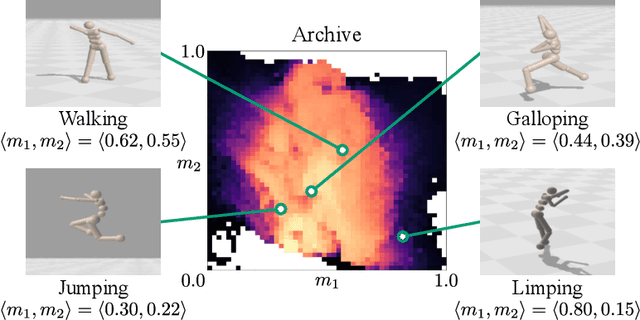
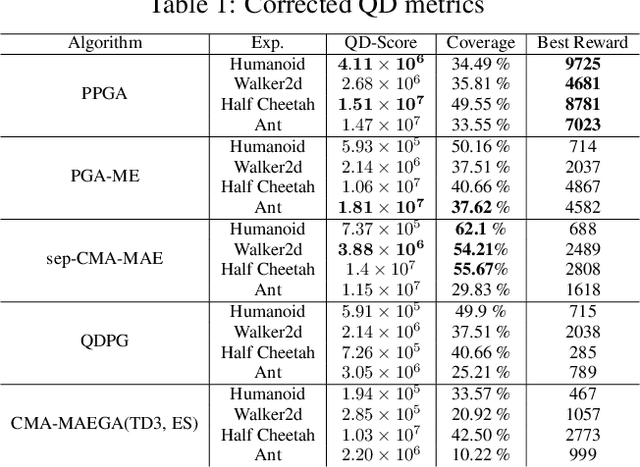
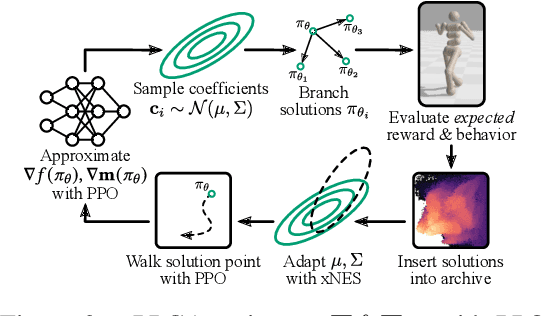
Training generally capable agents that perform well in unseen dynamic environments is a long-term goal of robot learning. Quality Diversity Reinforcement Learning (QD-RL) is an emerging class of reinforcement learning (RL) algorithms that blend insights from Quality Diversity (QD) and RL to produce a collection of high performing and behaviorally diverse policies with respect to a behavioral embedding. Existing QD-RL approaches have thus far taken advantage of sample-efficient off-policy RL algorithms. However, recent advances in high-throughput, massively parallelized robotic simulators have opened the door for algorithms that can take advantage of such parallelism, and it is unclear how to scale existing off-policy QD-RL methods to these new data-rich regimes. In this work, we take the first steps to combine on-policy RL methods, specifically Proximal Policy Optimization (PPO), that can leverage massive parallelism, with QD, and propose a new QD-RL method with these high-throughput simulators and on-policy training in mind. Our proposed Proximal Policy Gradient Arborescence (PPGA) algorithm yields a 4x improvement over baselines on the challenging humanoid domain.