 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscount Model Search for Quality Diversity Optimization in High-Dimensional Measure Spaces
Jan 03, 2026Quality diversity (QD) optimization searches for a collection of solutions that optimize an objective while attaining diverse outputs of a user-specified, vector-valued measure function. Contemporary QD algorithms focus on low-dimensional measures because high-dimensional measures are prone to distortion, where many solutions found by the QD algorithm map to similar measures. For example, the CMA-MAE algorithm guides measure space exploration with a histogram in measure space that records so-called discount values. However, CMA-MAE stagnates in domains with high-dimensional measure spaces because solutions with similar measures fall into the same histogram cell and thus receive identical discount values. To address these limitations, we propose Discount Model Search (DMS), which guides exploration with a model that provides a smooth, continuous representation of discount values. In high-dimensional measure spaces, this model enables DMS to distinguish between solutions with similar measures and thus continue exploration. We show that DMS facilitates new QD applications by introducing two domains where the measure space is the high-dimensional space of images, which enables users to specify their desired measures by providing a dataset of images rather than hand-designing the measure function. Results in these domains and on high-dimensional benchmarks show that DMS outperforms CMA-MAE and other black-box QD algorithms.
Quality-Diversity Generative Sampling for Learning with Synthetic Data
Dec 22, 2023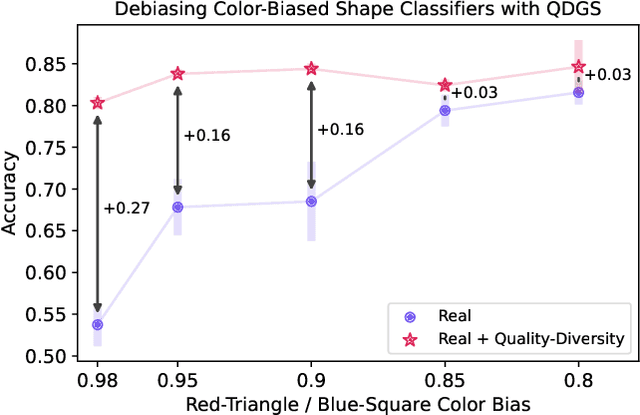
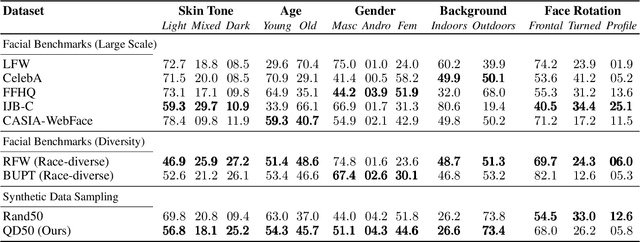


Generative models can serve as surrogates for some real data sources by creating synthetic training datasets, but in doing so they may transfer biases to downstream tasks. We focus on protecting quality and diversity when generating synthetic training datasets. We propose quality-diversity generative sampling (QDGS), a framework for sampling data uniformly across a user-defined measure space, despite the data coming from a biased generator. QDGS is a model-agnostic framework that uses prompt guidance to optimize a quality objective across measures of diversity for synthetically generated data, without fine-tuning the generative model. Using balanced synthetic datasets generated by QDGS, we first debias classifiers trained on color-biased shape datasets as a proof-of-concept. By applying QDGS to facial data synthesis, we prompt for desired semantic concepts, such as skin tone and age, to create an intersectional dataset with a combined blend of visual features. Leveraging this balanced data for training classifiers improves fairness while maintaining accuracy on facial recognition benchmarks. Code available at: https://github.com/Cylumn/qd-generative-sampling
Density Descent for Diversity Optimization
Dec 18, 2023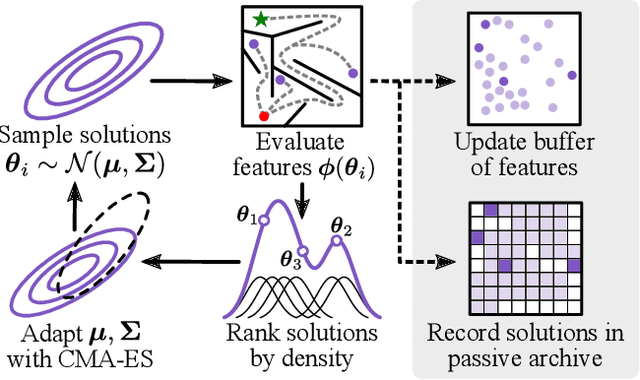
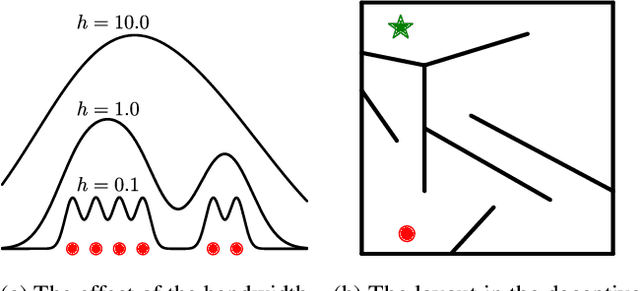
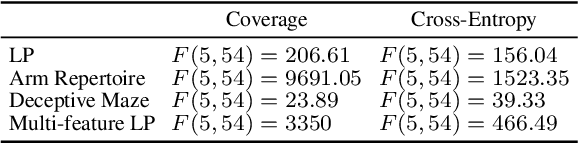
Diversity optimization seeks to discover a set of solutions that elicit diverse features. Prior work has proposed Novelty Search (NS), which, given a current set of solutions, seeks to expand the set by finding points in areas of low density in the feature space. However, to estimate density, NS relies on a heuristic that considers the k-nearest neighbors of the search point in the feature space, which yields a weaker stability guarantee. We propose Density Descent Search (DDS), an algorithm that explores the feature space via gradient descent on a continuous density estimate of the feature space that also provides stronger stability guarantee. We experiment with DDS and two density estimation methods: kernel density estimation (KDE) and continuous normalizing flow (CNF). On several standard diversity optimization benchmarks, DDS outperforms NS, the recently proposed MAP-Annealing algorithm, and other state-of-the-art baselines. Additionally, we prove that DDS with KDE provides stronger stability guarantees than NS, making it more suitable for adaptive optimizers. Furthermore, we prove that NS is a special case of DDS that descends a KDE of the feature space.
Arbitrarily Scalable Environment Generators via Neural Cellular Automata
Oct 28, 2023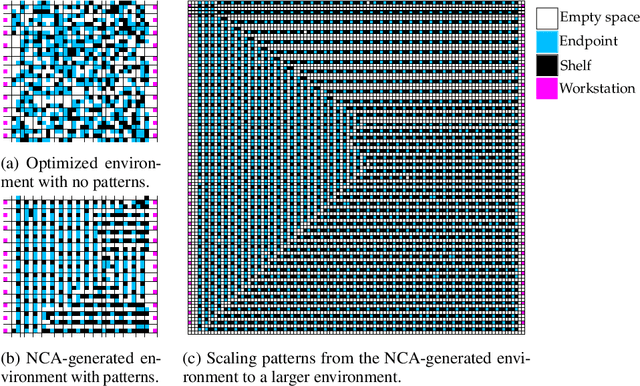

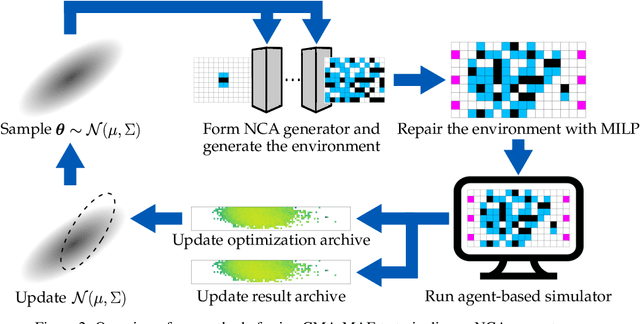
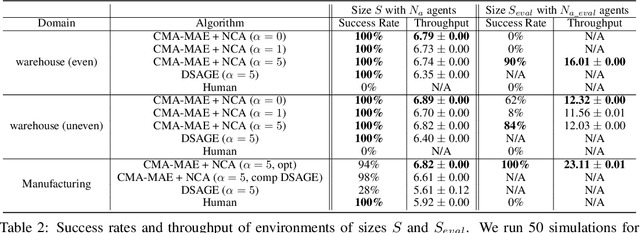
We study the problem of generating arbitrarily large environments to improve the throughput of multi-robot systems. Prior work proposes Quality Diversity (QD) algorithms as an effective method for optimizing the environments of automated warehouses. However, these approaches optimize only relatively small environments, falling short when it comes to replicating real-world warehouse sizes. The challenge arises from the exponential increase in the search space as the environment size increases. Additionally, the previous methods have only been tested with up to 350 robots in simulations, while practical warehouses could host thousands of robots. In this paper, instead of optimizing environments, we propose to optimize Neural Cellular Automata (NCA) environment generators via QD algorithms. We train a collection of NCA generators with QD algorithms in small environments and then generate arbitrarily large environments from the generators at test time. We show that NCA environment generators maintain consistent, regularized patterns regardless of environment size, significantly enhancing the scalability of multi-robot systems in two different domains with up to 2,350 robots. Additionally, we demonstrate that our method scales a single-agent reinforcement learning policy to arbitrarily large environments with similar patterns. We include the source code at \url{https://github.com/lunjohnzhang/warehouse_env_gen_nca_public}.
Proximal Policy Gradient Arborescence for Quality Diversity Reinforcement Learning
May 23, 2023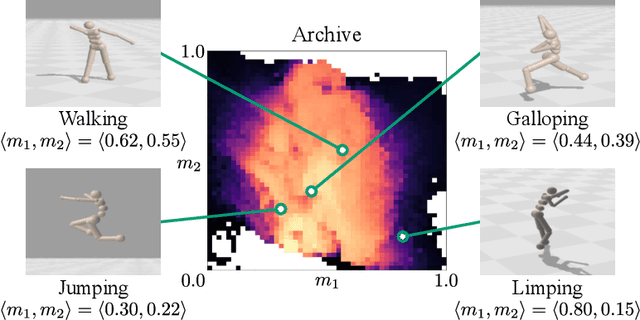
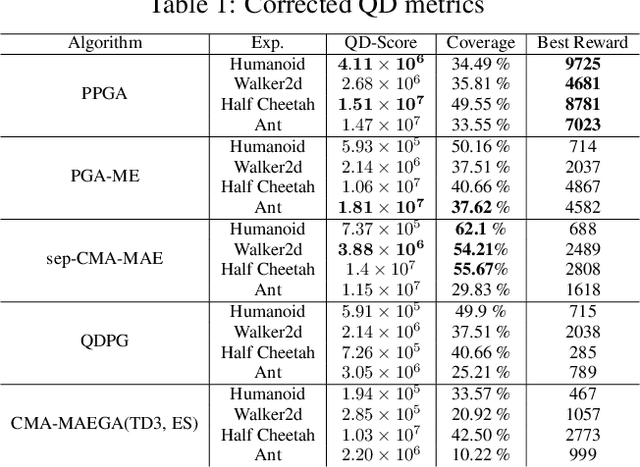
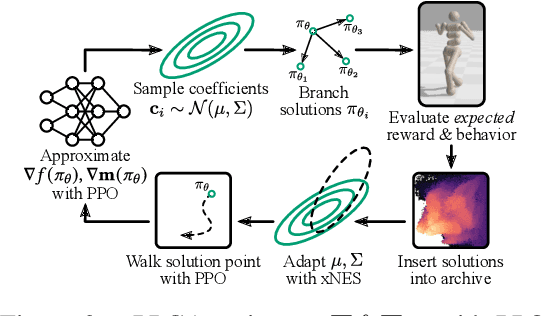
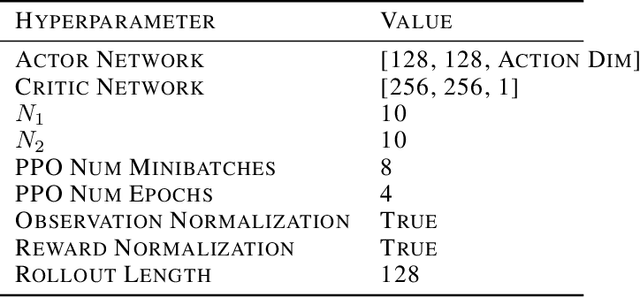
Training generally capable agents that perform well in unseen dynamic environments is a long-term goal of robot learning. Quality Diversity Reinforcement Learning (QD-RL) is an emerging class of reinforcement learning (RL) algorithms that blend insights from Quality Diversity (QD) and RL to produce a collection of high performing and behaviorally diverse policies with respect to a behavioral embedding. Existing QD-RL approaches have thus far taken advantage of sample-efficient off-policy RL algorithms. However, recent advances in high-throughput, massively parallelized robotic simulators have opened the door for algorithms that can take advantage of such parallelism, and it is unclear how to scale existing off-policy QD-RL methods to these new data-rich regimes. In this work, we take the first steps to combine on-policy RL methods, specifically Proximal Policy Optimization (PPO), that can leverage massive parallelism, with QD, and propose a new QD-RL method with these high-throughput simulators and on-policy training in mind. Our proposed Proximal Policy Gradient Arborescence (PPGA) algorithm yields a 4x improvement over baselines on the challenging humanoid domain.
Multi-Robot Coordination and Layout Design for Automated Warehousing
May 12, 2023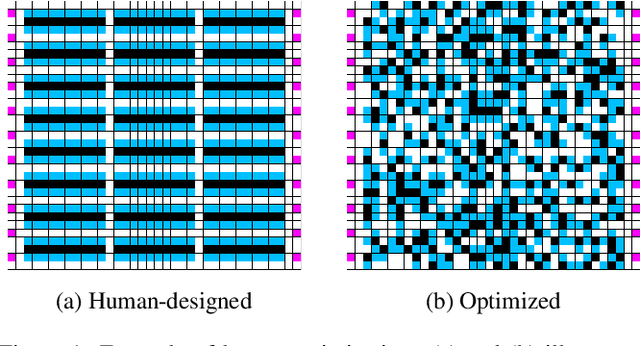

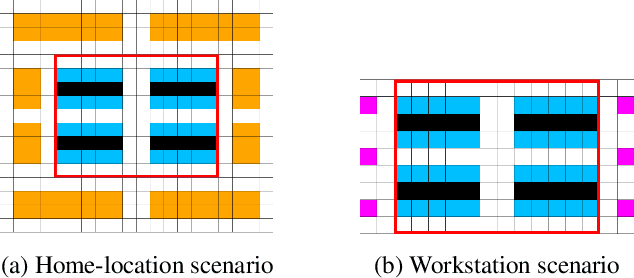
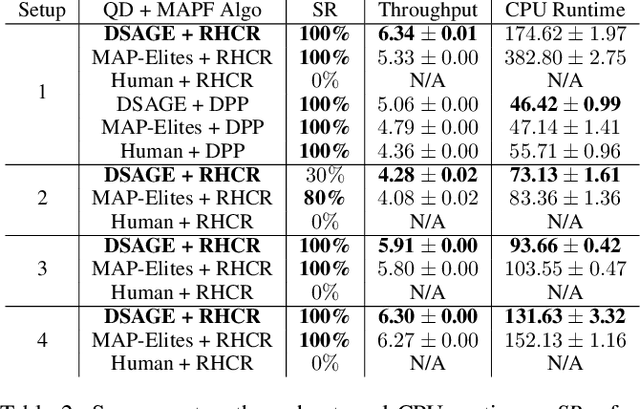
With the rapid progress in Multi-Agent Path Finding (MAPF), researchers have studied how MAPF algorithms can be deployed to coordinate hundreds of robots in large automated warehouses. While most works try to improve the throughput of such warehouses by developing better MAPF algorithms, we focus on improving the throughput by optimizing the warehouse layout. We show that, even with state-of-the-art MAPF algorithms, commonly used human-designed layouts can lead to congestion for warehouses with large numbers of robots and thus have limited scalability. We extend existing automatic scenario generation methods to optimize warehouse layouts. Results show that our optimized warehouse layouts (1) reduce traffic congestion and thus improve throughput, (2) improve the scalability of the automated warehouses by doubling the number of robots in some cases, and (3) are capable of generating layouts with user-specified diversity measures. We include the source code at: https://github.com/lunjohnzhang/warehouse_env_gen_public
Surrogate Assisted Generation of Human-Robot Interaction Scenarios
May 11, 2023



As human-robot interaction (HRI) systems advance, so does the difficulty of evaluating and understanding the strengths and limitations of these systems in different environments and with different users. To this end, previous methods have algorithmically generated diverse scenarios that reveal system failures in a shared control teleoperation task. However, these methods require directly evaluating generated scenarios by simulating robot policies and human actions. The computational cost of these evaluations limits their applicability in more complex domains. Thus, we propose augmenting scenario generation systems with surrogate models that predict both human and robot behaviors. In the shared control teleoperation domain and a more complex shared workspace collaboration task, we show that surrogate assisted scenario generation efficiently synthesizes diverse datasets of challenging scenarios. We demonstrate that these failures are reproducible in real-world interactions.
pyribs: A Bare-Bones Python Library for Quality Diversity Optimization
Mar 01, 2023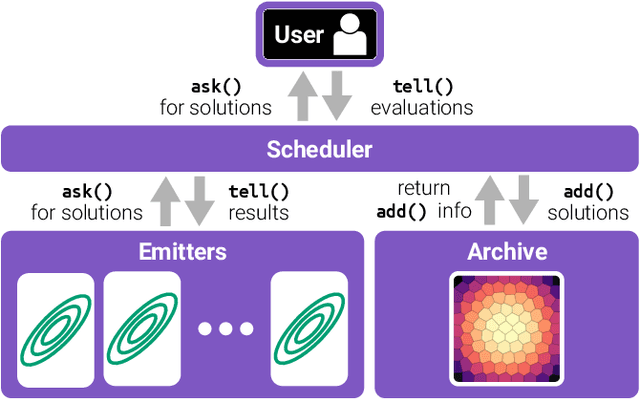
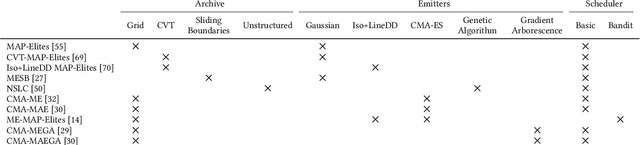
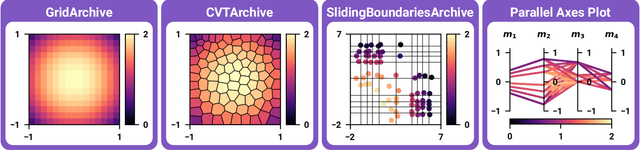
Recent years have seen a rise in the popularity of quality diversity (QD) optimization, a branch of optimization that seeks to find a collection of diverse, high-performing solutions to a given problem. To grow further, we believe the QD community faces two challenges: developing a framework to represent the field's growing array of algorithms, and implementing that framework in software that supports a range of researchers and practitioners. To address these challenges, we have developed pyribs, a library built on a highly modular conceptual QD framework. By replacing components in the conceptual framework, and hence in pyribs, users can compose algorithms from across the QD literature; equally important, they can identify unexplored algorithm variations. Furthermore, pyribs makes this framework simple, flexible, and accessible, with a user-friendly API supported by extensive documentation and tutorials. This paper overviews the creation of pyribs, focusing on the conceptual framework that it implements and the design principles that have guided the library's development.
Training Diverse High-Dimensional Controllers by Scaling Covariance Matrix Adaptation MAP-Annealing
Oct 06, 2022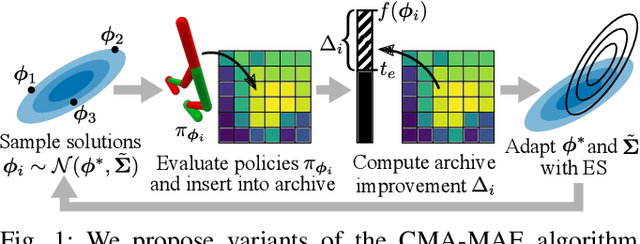

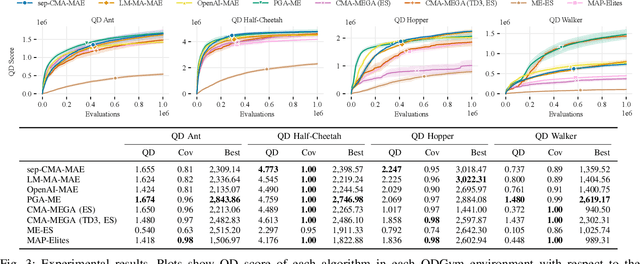
Pre-training a diverse set of robot controllers in simulation has enabled robots to adapt online to damage in robot locomotion tasks. However, finding diverse, high-performing controllers requires specialized hardware and extensive tuning of a large number of hyperparameters. On the other hand, the Covariance Matrix Adaptation MAP-Annealing algorithm, an evolution strategies (ES)-based quality diversity algorithm, does not have these limitations and has been shown to achieve state-of-the-art performance in standard benchmark domains. However, CMA-MAE cannot scale to modern neural network controllers due to its quadratic complexity. We leverage efficient approximation methods in ES to propose three new CMA-MAE variants that scale to very high dimensions. Our experiments show that the variants outperform ES-based baselines in benchmark robotic locomotion tasks, while being comparable with state-of-the-art deep reinforcement learning-based quality diversity algorithms. Source code and videos are available at https://scalingcmamae.github.io
Generating Diverse Indoor Furniture Arrangements
Jun 20, 2022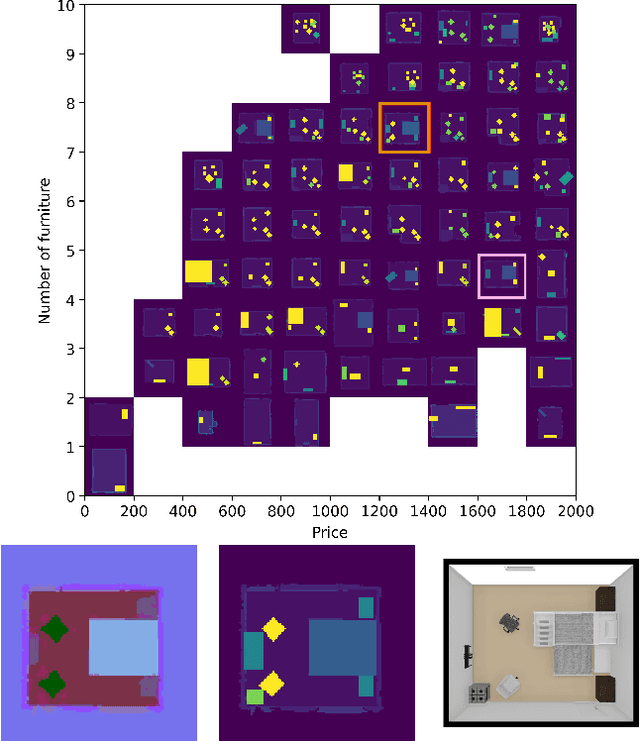

We present a method for generating arrangements of indoor furniture from human-designed furniture layout data. Our method creates arrangements that target specified diversity, such as the total price of all furniture in the room and the number of pieces placed. To generate realistic furniture arrangement, we train a generative adversarial network (GAN) on human-designed layouts. To target specific diversity in the arrangements, we optimize the latent space of the GAN via a quality diversity algorithm to generate a diverse arrangement collection. Experiments show our approach discovers a set of arrangements that are similar to human-designed layouts but varies in price and number of furniture pieces.