 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Symbolic Learning for Long-Horizon Task Planning Under Complex Logical Constraints
Jun 05, 2026Task planning often suffers from severe efficiency bottlenecks when robots must reason over long-horizon action sequences under complex logical constraints, including object affordances, spatial relationships, and sequential action dependencies. Recent neuro-symbolic methods improve planning efficiency by learning object-importance scores to prune task-irrelevant objects, but they typically rely on fixed offline supervision generated from full search spaces. This creates a train-test mismatch: at deployment, the planner operates in pruned search spaces induced by the model's own imperfect predictions, leading to exposure bias and degraded planning performance. To address this challenge, we formulate object-importance learning for task planning as an imperative learning-based bilevel optimization problem. The upper level optimizes a neural scorer, while the lower level solves a symbolic planning problem in the score-pruned search space. To stabilize this learning process, we introduce a 3R strategy into the lower-level planning, using parallel Repair, Restart, and Rollback recovery to provide reliable and adaptive feedback for upper-level learning. Experiments on three challenging benchmarks demonstrate state-of-the-art performance, including an 80.04% reduction in failure rate and a 57.14% reduction in planning time. We further validate the framework on a quadruped-based mobile manipulator in simulation and the real world, demonstrating its potential for efficient and deployable neuro-symbolic task planning.
Planning over MAPF Agent Dependencies via Multi-Dependency PIBT
Mar 24, 2026Modern Multi-Agent Path Finding (MAPF) algorithms must plan for hundreds to thousands of agents in congested environments within a second, requiring highly efficient algorithms. Priority Inheritance with Backtracking (PIBT) is a popular algorithm capable of effectively planning in such situations. However, PIBT is constrained by its rule-based planning procedure and lacks generality because it restricts its search to paths that conflict with at most one other agent. This limitation also applies to Enhanced PIBT (EPIBT), a recent extension of PIBT. In this paper, we describe a new perspective on solving MAPF by planning over agent dependencies. Taking inspiration from PIBT's priority inheritance logic, we define the concept of agent dependencies and propose Multi-Dependency PIBT (MD-PIBT) that searches over agent dependencies. MD-PIBT is a general framework where specific parameterizations can reproduce PIBT and EPIBT. At the same time, alternative configurations yield novel planning strategies that are not expressible by PIBT or EPIBT. Our experiments demonstrate that MD-PIBT effectively plans for as many as 10,000 homogeneous agents under various kinodynamic constraints, including pebble motion, rotation motion, and differential drive robots with speed and acceleration limits. We perform thorough evaluations on different variants of MAPF and find that MD-PIBT is particularly effective in MAPF with large agents.
DaPT: A Dual-Path Framework for Multilingual Multi-hop Question Answering
Mar 19, 2026Retrieval-augmented generation (RAG) systems have made significant progress in solving complex multi-hop question answering (QA) tasks in the English scenario. However, RAG systems inevitably face the application scenario of retrieving across multilingual corpora and queries, leaving several open challenges. The first one involves the absence of benchmarks that assess RAG systems' capabilities under the multilingual multi-hop (MM-hop) QA setting. The second centers on the overreliance on LLMs' strong semantic understanding in English, which diminishes effectiveness in multilingual scenarios. To address these challenges, we first construct multilingual multi-hop QA benchmarks by translating English-only benchmarks into five languages, and then we propose DaPT, a novel multilingual RAG framework. DaPT generates sub-question graphs in parallel for both the source-language query and its English translation counterpart, then merges them before employing a bilingual retrieval-and-answer strategy to sequentially solve sub-questions. Our experimental results demonstrate that advanced RAG systems suffer from a significant performance imbalance in multilingual scenarios. Furthermore, our proposed method consistently yields more accurate and concise answers compared to the baselines, significantly enhancing RAG performance on this task. For instance, on the most challenging MuSiQue benchmark, DaPT achieves a relative improvement of 18.3\% in average EM score over the strongest baseline.
Autonomous Integration and Improvement of Robotic Assembly using Skill Graph Representations
Mar 13, 2026Robotic assembly systems traditionally require substantial manual engineering effort to integrate new tasks, adapt to new environments, and improve performance over time. This paper presents a framework for autonomous integration and continuous improvement of robotic assembly systems based on Skill Graph representations. A Skill Graph organizes robot capabilities as verb-based skills, explicitly linking semantic descriptions (verbs and nouns) with executable policies, pre-conditions, post-conditions, and evaluators. We show how Skill Graphs enable rapid system integration by supporting semantic-level planning over skills, while simultaneously grounding execution through well-defined interfaces to robot controllers and perception modules. After initial deployment, the same Skill Graph structure supports systematic data collection and closed-loop performance improvement, enabling iterative refinement of skills and their composition. We demonstrate how this approach unifies system configuration, execution, evaluation, and learning within a single representation, providing a scalable pathway toward adaptive and reusable robotic assembly systems. The code is at https://github.com/intelligent-control-lab/AIDF.
Lifelong Scalable Multi-Agent Realistic Testbed and A Comprehensive Study on Design Choices in Lifelong AGV Fleet Management Systems
Feb 17, 2026We present Lifelong Scalable Multi-Agent Realistic Testbed (LSMART), an open-source simulator to evaluate any Multi-Agent Path Finding (MAPF) algorithm in a Fleet Management System (FMS) with Automated Guided Vehicles (AGVs). MAPF aims to move a group of agents from their corresponding starting locations to their goals. Lifelong MAPF (LMAPF) is a variant of MAPF that continuously assigns new goals for agents to reach. LMAPF applications, such as autonomous warehouses, often require a centralized, lifelong system to coordinate the movement of a fleet of robots, typically AGVs. However, existing works on MAPF and LMAPF often assume simplified kinodynamic models, such as pebble motion, as well as perfect execution and communication for AGVs. Prior work has presented SMART, a software capable of evaluating any MAPF algorithms while considering agent kinodynamics, communication delays, and execution uncertainties. However, SMART is designed for MAPF, not LMAPF. Generalizing SMART to an FMS requires many more design choices. First, an FMS parallelizes planning and execution, raising the question of when to plan. Second, given planners with varying optimality and differing agent-model assumptions, one must decide how to plan. Third, when the planner fails to return valid solutions, the system must determine how to recover. In this paper, we first present LSMART, an open-source simulator that incorporates all these considerations to evaluate any MAPF algorithms in an FMS. We then provide experiment results based on state-of-the-art methods for each design choice, offering guidance on how to effectively design centralized lifelong AGV Fleet Management Systems. LSMART is available at https://smart-mapf.github.io/lifelong-smart.
Analyzing Planner Design Trade-offs for MAPF under Realistic Simulation
Dec 10, 2025Multi-Agent Path Finding (MAPF) algorithms are increasingly deployed in industrial warehouses and automated manufacturing facilities, where robots must operate reliably under real-world physical constraints. However, existing MAPF evaluation frameworks typically rely on simplified robot models, leaving a substantial gap between algorithmic benchmarks and practical performance. Recent frameworks such as SMART, incorporate kinodynamic modeling and offer the MAPF community a platform for large-scale, realistic evaluation. Building on this capability, this work investigates how key planner design choices influence performance under realistic execution settings. We systematically study three fundamental factors: (1) the relationship between solution optimality and execution performance, (2) the sensitivity of system performance to inaccuracies in kinodynamic modeling, and (3) the interaction between model accuracy and plan optimality. Empirically, we examine these factors to understand how these design choices affect performance in realistic scenarios. We highlight open challenges and research directions to steer the community toward practical, real-world deployment.
Collaborative Multi-Robot Non-Prehensile Manipulation via Flow-Matching Co-Generation
Nov 14, 2025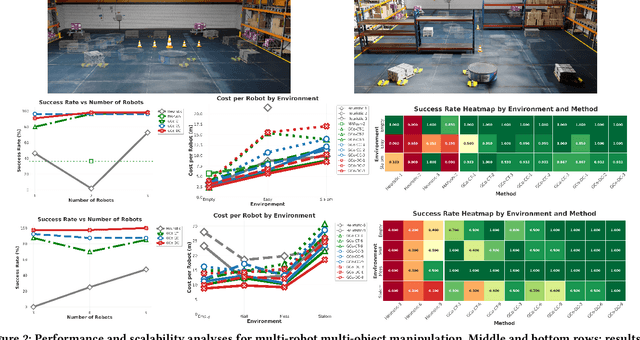
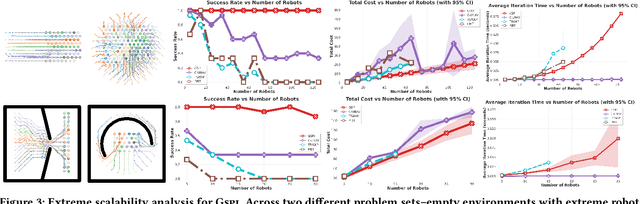


Coordinating a team of robots to reposition multiple objects in cluttered environments requires reasoning jointly about where robots should establish contact, how to manipulate objects once contact is made, and how to navigate safely and efficiently at scale. Prior approaches typically fall into two extremes -- either learning the entire task or relying on privileged information and hand-designed planners -- both of which struggle to handle diverse objects in long-horizon tasks. To address these challenges, we present a unified framework for collaborative multi-robot, multi-object non-prehensile manipulation that integrates flow-matching co-generation with anonymous multi-robot motion planning. Within this framework, a generative model co-generates contact formations and manipulation trajectories from visual observations, while a novel motion planner conveys robots at scale. Crucially, the same planner also supports coordination at the object level, assigning manipulated objects to larger target structures and thereby unifying robot- and object-level reasoning within a single algorithmic framework. Experiments in challenging simulated environments demonstrate that our approach outperforms baselines in both motion planning and manipulation tasks, highlighting the benefits of generative co-design and integrated planning for scaling collaborative manipulation to complex multi-agent, multi-object settings. Visit gco-paper.github.io for code and demonstrations.
SUBQRAG: sub-question driven dynamic graph rag
Oct 09, 2025Graph Retrieval-Augmented Generation (Graph RAG) effectively builds a knowledge graph (KG) to connect disparate facts across a large document corpus. However, this broad-view approach often lacks the deep structured reasoning needed for complex multi-hop question answering (QA), leading to incomplete evidence and error accumulation. To address these limitations, we propose SubQRAG, a sub-question-driven framework that enhances reasoning depth. SubQRAG decomposes a complex question into an ordered chain of verifiable sub-questions. For each sub-question, it retrieves relevant triples from the graph. When the existing graph is insufficient, the system dynamically expands it by extracting new triples from source documents in real time. All triples used in the reasoning process are aggregated into a "graph memory," forming a structured and traceable evidence path for final answer generation. Experiments on three multi-hop QA benchmarks demonstrate that SubQRAG achieves consistent and significant improvements, especially in Exact Match scores.
Prompt-to-Product: Generative Assembly via Bimanual Manipulation
Aug 28, 2025

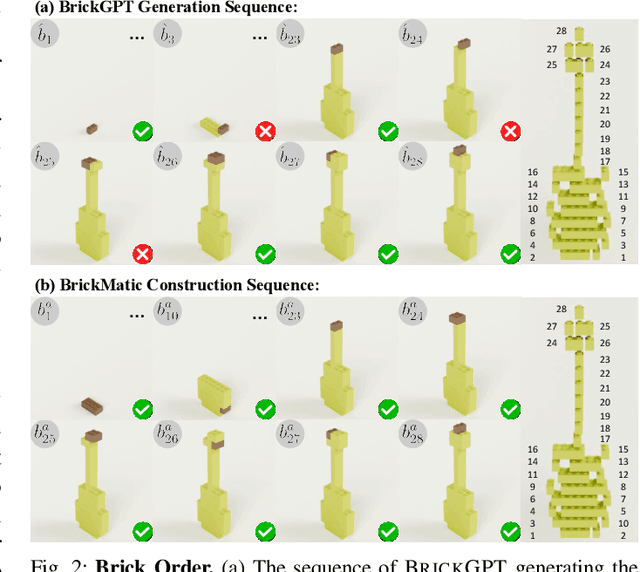
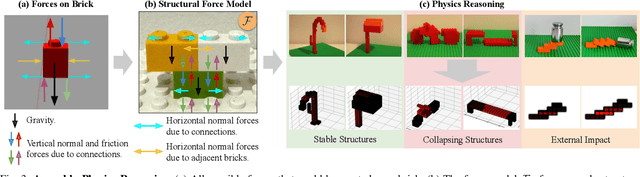
Creating assembly products demands significant manual effort and expert knowledge in 1) designing the assembly and 2) constructing the product. This paper introduces Prompt-to-Product, an automated pipeline that generates real-world assembly products from natural language prompts. Specifically, we leverage LEGO bricks as the assembly platform and automate the process of creating brick assembly structures. Given the user design requirements, Prompt-to-Product generates physically buildable brick designs, and then leverages a bimanual robotic system to construct the real assembly products, bringing user imaginations into the real world. We conduct a comprehensive user study, and the results demonstrate that Prompt-to-Product significantly lowers the barrier and reduces manual effort in creating assembly products from imaginative ideas.
Benchmarking Shortcutting Techniques for Multi-Robot-Arm Motion Planning
Aug 07, 2025Generating high-quality motion plans for multiple robot arms is challenging due to the high dimensionality of the system and the potential for inter-arm collisions. Traditional motion planning methods often produce motions that are suboptimal in terms of smoothness and execution time for multi-arm systems. Post-processing via shortcutting is a common approach to improve motion quality for efficient and smooth execution. However, in multi-arm scenarios, optimizing one arm's motion must not introduce collisions with other arms. Although existing multi-arm planning works often use some form of shortcutting techniques, their exact methodology and impact on performance are often vaguely described. In this work, we present a comprehensive study quantitatively comparing existing shortcutting methods for multi-arm trajectories across diverse simulated scenarios. We carefully analyze the pros and cons of each shortcutting method and propose two simple strategies for combining these methods to achieve the best performance-runtime tradeoff. Video, code, and dataset are available at https://philip-huang.github.io/mr-shortcut/.