 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Indistinguishability: Measuring Extraction Risk in LLM APIs
Apr 20, 2026Indistinguishability properties such as differential privacy bounds or low empirically measured membership inference are widely treated as proxies to show a model is sufficiently protected against broader memorization risks. However, we show that indistinguishability properties are neither sufficient nor necessary for preventing data extraction in LLM APIs. We formalize a privacy-game separation between extraction and indistinguishability-based privacy, showing that indistinguishability and inextractability are incomparable: upper-bounding distinguishability does not upper-bound extractability. To address this gap, we introduce $(l, b)$-inextractability as a definition that requires at least $2^b$ expected queries for any black-box adversary to induce the LLM API to emit a protected $l$-gram substring. We instantiate this via a worst-case extraction game and derive a rank-based extraction risk upper bound for targeted exact extraction, as well as extensions to cover untargeted and approximate extraction. The resulting estimator captures the extraction risk over multiple attack trials and prefix adaptations. We show that it can provide a tight and efficient estimation for standard greedy extraction and an upper bound on the probabilistic extraction risk given any decoding configuration. We empirically evaluate extractability across different models, clarifying its connection to distinguishability, demonstrating its advantage over existing extraction risk estimators, and providing actionable mitigation guidelines across model training, API access, and decoding configurations in LLM API deployment. Our code is publicly available at: https://github.com/Emory-AIMS/Inextractability.
BrickSim: A Physics-Based Simulator for Manipulating Interlocking Brick Assemblies
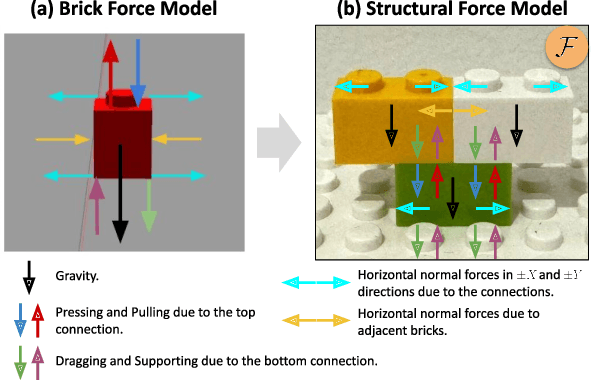
Mar 17, 2026Interlocking brick assemblies provide a standardized yet challenging testbed for contact-rich and long-horizon robotic manipulation, but existing rigid-body simulators do not faithfully capture snap-fit mechanics. We present BrickSim, the first real-time physics-based simulator for interlocking brick assemblies. BrickSim introduces a compact force-based mechanics model for snap-fit connections and solves the resulting internal force distribution using a structured convex quadratic program. Combined with a hybrid architecture that delegates rigid-body dynamics to the underlying physics engine while handling snap-fit mechanics separately, BrickSim enables real-time, high-fidelity simulation of assembly, disassembly, and structural collapse. On 150 real-world assemblies, BrickSim achieves 100% accuracy in static stability prediction with an average solve time of 5 ms. In dynamic drop tests, it also faithfully reproduces real-world structural collapse, precisely mirroring both the occurrence of breakage and the specific breakage locations. Built on Isaac Sim, BrickSim further supports seamless integration with a wide variety of robots and existing pipelines. We demonstrate robotic construction of brick assemblies using BrickSim, highlighting its potential as a foundation for research in dexterous, long-horizon robotic manipulation. BrickSim is open-source, and the code is available at https://github.com/intelligent-control-lab/BrickSim.
RoCo Challenge at AAAI 2026: Benchmarking Robotic Collaborative Manipulation for Assembly Towards Industrial Automation
Mar 16, 2026Embodied Artificial Intelligence (EAI) is rapidly developing, gradually subverting previous autonomous systems' paradigms from isolated perception to integrated, continuous action. This transition is highly significant for industrial robotic manipulation, promising to free human workers from repetitive, dangerous daily labor. To benchmark and advance this capability, we introduce the Robotic Collaborative Assembly Assistance (RoCo) Challenge with a dataset towards simulation and real-world assembly manipulation. Set against the backdrop of human-centered manufacturing, this challenge focuses on a high-precision planetary gearbox assembly task, a demanding yet highly representative operation in modern industry. Built upon a self-developed data collection, training, and evaluation system in Isaac Sim, and utilizing a dual-arm robot for real-world deployment, the challenge operates in two phases. The Simulation Round defines fine-grained task phases for step-wise scoring to handle the long-horizon nature of the assembly. The Real-World Round mirrors this evaluation with physical gearbox components and high-quality teleoperated datasets. The core tasks require assembling an epicyclic gearbox from scratch, including mounting three planet gears, a sun gear, and a ring gear. Attracting over 60 teams and 170+ participants from more than 10 countries, the challenge yielded highly effective solutions, most notably ARC-VLA and RoboCola. Results demonstrate that a dual-model framework for long-horizon multi-task learning is highly effective, and the strategic utilization of recovery-from-failure curriculum data is a critical insight for successful deployment. This report outlines the competition setup, evaluation approach, key findings, and future directions for industrial EAI. Our dataset, CAD files, code, and evaluation results can be found at: https://rocochallenge.github.io/RoCo2026/.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Debiased Bayesian Inference for High-dimensional Regression Models
Dec 10, 2025There has been significant progress in Bayesian inference based on sparsity-inducing (e.g., spike-and-slab and horseshoe-type) priors for high-dimensional regression models. The resulting posteriors, however, in general do not possess desirable frequentist properties, and the credible sets thus cannot serve as valid confidence sets even asymptotically. We introduce a novel debiasing approach that corrects the bias for the entire Bayesian posterior distribution. We establish a new Bernstein-von Mises theorem that guarantees the frequentist validity of the debiased posterior. We demonstrate the practical performance of our proposal through Monte Carlo simulations and two empirical applications in economics.
FusionDP: Foundation Model-Assisted Differentially Private Learning for Partially Sensitive Features
Nov 05, 2025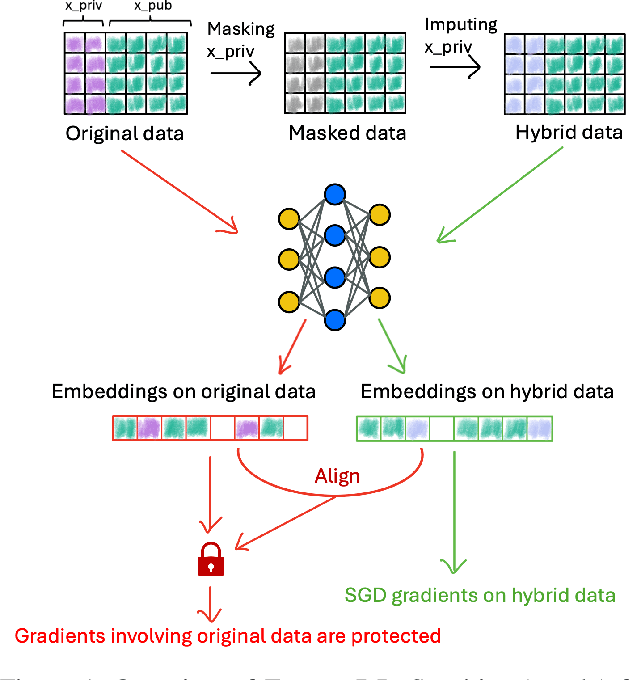
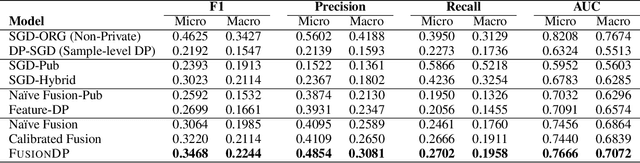
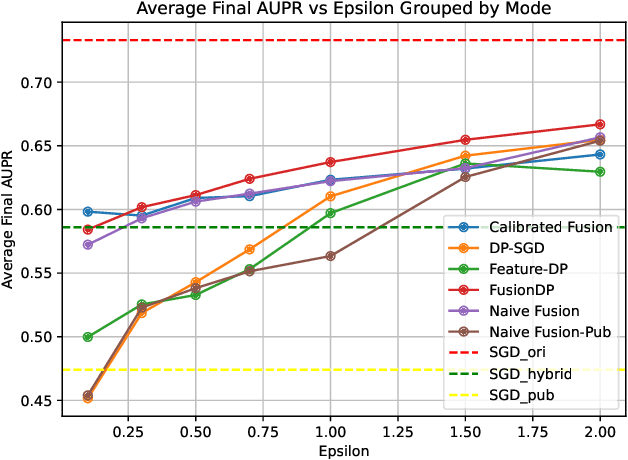
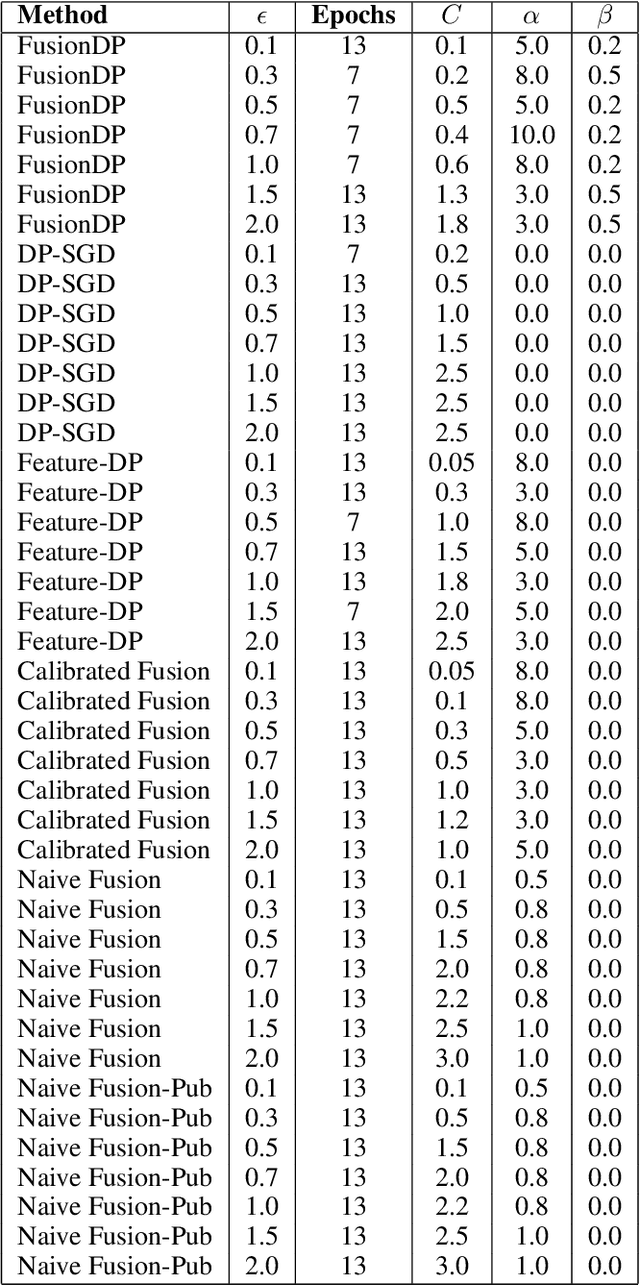
Ensuring the privacy of sensitive training data is crucial in privacy-preserving machine learning. However, in practical scenarios, privacy protection may be required for only a subset of features. For instance, in ICU data, demographic attributes like age and gender pose higher privacy risks due to their re-identification potential, whereas raw lab results are generally less sensitive. Traditional DP-SGD enforces privacy protection on all features in one sample, leading to excessive noise injection and significant utility degradation. We propose FusionDP, a two-step framework that enhances model utility under feature-level differential privacy. First, FusionDP leverages large foundation models to impute sensitive features given non-sensitive features, treating them as external priors that provide high-quality estimates of sensitive attributes without accessing the true values during model training. Second, we introduce a modified DP-SGD algorithm that trains models on both original and imputed features while formally preserving the privacy of the original sensitive features. We evaluate FusionDP on two modalities: a sepsis prediction task on tabular data from PhysioNet and a clinical note classification task from MIMIC-III. By comparing against privacy-preserving baselines, our results show that FusionDP significantly improves model performance while maintaining rigorous feature-level privacy, demonstrating the potential of foundation model-driven imputation to enhance the privacy-utility trade-off for various modalities.
Prompt-to-Product: Generative Assembly via Bimanual Manipulation
Aug 28, 2025

Creating assembly products demands significant manual effort and expert knowledge in 1) designing the assembly and 2) constructing the product. This paper introduces Prompt-to-Product, an automated pipeline that generates real-world assembly products from natural language prompts. Specifically, we leverage LEGO bricks as the assembly platform and automate the process of creating brick assembly structures. Given the user design requirements, Prompt-to-Product generates physically buildable brick designs, and then leverages a bimanual robotic system to construct the real assembly products, bringing user imaginations into the real world. We conduct a comprehensive user study, and the results demonstrate that Prompt-to-Product significantly lowers the barrier and reduces manual effort in creating assembly products from imaginative ideas.
NeSyPack: A Neuro-Symbolic Framework for Bimanual Logistics Packing
Jun 06, 2025This paper presents NeSyPack, a neuro-symbolic framework for bimanual logistics packing. NeSyPack combines data-driven models and symbolic reasoning to build an explainable hierarchical system that is generalizable, data-efficient, and reliable. It decomposes a task into subtasks via hierarchical reasoning, and further into atomic skills managed by a symbolic skill graph. The graph selects skill parameters, robot configurations, and task-specific control strategies for execution. This modular design enables robustness, adaptability, and efficient reuse - outperforming end-to-end models that require large-scale retraining. Using NeSyPack, our team won the First Prize in the What Bimanuals Can Do (WBCD) competition at the 2025 IEEE International Conference on Robotics and Automation.
Generating Physically Stable and Buildable LEGO Designs from Text
May 08, 2025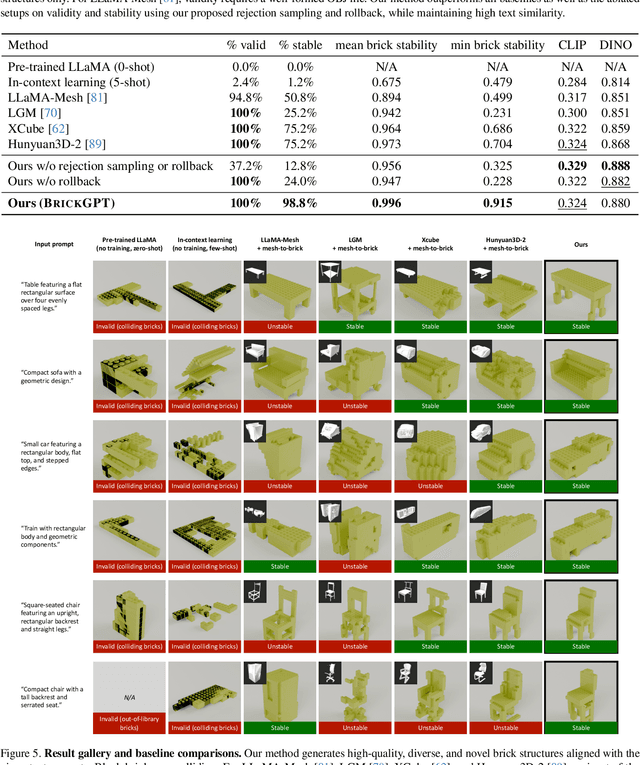
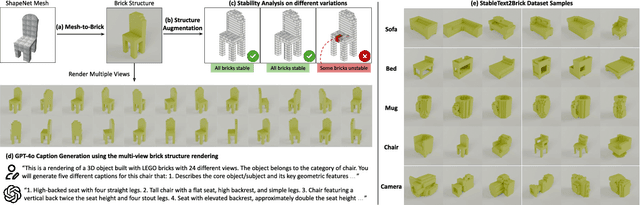
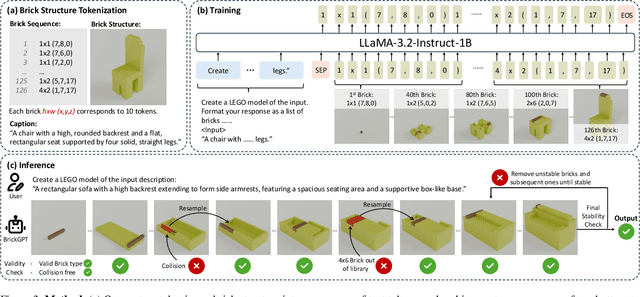
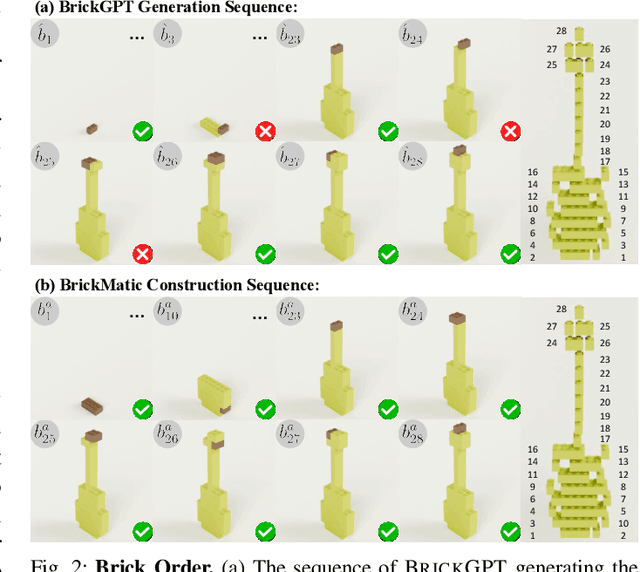
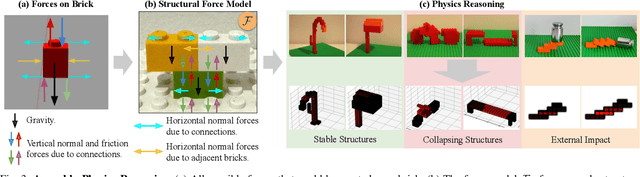
We introduce LegoGPT, the first approach for generating physically stable LEGO brick models from text prompts. To achieve this, we construct a large-scale, physically stable dataset of LEGO designs, along with their associated captions, and train an autoregressive large language model to predict the next brick to add via next-token prediction. To improve the stability of the resulting designs, we employ an efficient validity check and physics-aware rollback during autoregressive inference, which prunes infeasible token predictions using physics laws and assembly constraints. Our experiments show that LegoGPT produces stable, diverse, and aesthetically pleasing LEGO designs that align closely with the input text prompts. We also develop a text-based LEGO texturing method to generate colored and textured designs. We show that our designs can be assembled manually by humans and automatically by robotic arms. We also release our new dataset, StableText2Lego, containing over 47,000 LEGO structures of over 28,000 unique 3D objects accompanied by detailed captions, along with our code and models at the project website: https://avalovelace1.github.io/LegoGPT/.
APEX-MR: Multi-Robot Asynchronous Planning and Execution for Cooperative Assembly
Mar 20, 2025Compared to a single-robot workstation, a multi-robot system offers several advantages: 1) it expands the system's workspace, 2) improves task efficiency, and more importantly, 3) enables robots to achieve significantly more complex and dexterous tasks, such as cooperative assembly. However, coordinating the tasks and motions of multiple robots is challenging due to issues, e.g. system uncertainty, task efficiency, algorithm scalability, and safety concerns. To address these challenges, this paper studies multi-robot coordination and proposes APEX-MR, an asynchronous planning and execution framework designed to safely and efficiently coordinate multiple robots to achieve cooperative assembly, e.g. LEGO assembly. In particular, APEX-MR provides a systematic approach to post-process multi-robot tasks and motion plans to enable robust asynchronous execution under uncertainty. Experimental results demonstrate that APEX-MR can significantly speed up the execution time of many long-horizon LEGO assembly tasks by 48% compared to sequential planning and 36% compared to synchronous planning on average. To further demonstrate the performance, we deploy APEX-MR to a dual-arm system to perform physical LEGO assembly. To our knowledge, this is the first robotic system capable of performing customized LEGO assembly using commercial LEGO bricks. The experiment results demonstrate that the dual-arm system, with APEX-MR, can safely coordinate robot motions, efficiently collaborate, and construct complex LEGO structures. Our project website is available at https://intelligent-control-lab.github.io/APEX-MR/