 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegFreeNet: A Registration-Free Network for CBCT-based 3D Dental Implant Planning
Jan 21, 2026As the commercial surgical guide design software usually does not support the export of implant position for pre-implantation data, existing methods have to scan the post-implantation data and map the implant to pre-implantation space to get the label of implant position for training. Such a process is time-consuming and heavily relies on the accuracy of registration algorithm. Moreover, not all hospitals have paired CBCT data, limitting the construction of multi-center dataset. Inspired by the way dentists determine the implant position based on the neighboring tooth texture, we found that even if the implant area is masked, it will not affect the determination of the implant position. Therefore, we propose to mask the implants in the post-implantation data so that any CBCT containing the implants can be used as training data. This paradigm enables us to discard the registration process and makes it possible to construct a large-scale multi-center implant dataset. On this basis, we proposes ImplantFairy, a comprehensive, publicly accessible dental implant dataset with voxel-level 3D annotations of 1622 CBCT data. Furthermore, according to the area variation characteristics of the tooth's spatial structure and the slope information of the implant, we designed a slope-aware implant position prediction network. Specifically, a neighboring distance perception (NDP) module is designed to adaptively extract tooth area variation features, and an implant slope prediction branch assists the network in learning more robust features through additional implant supervision information. Extensive experiments conducted on ImplantFairy and two public dataset demonstrate that the proposed RegFreeNet achieves the state-of-the-art performance.
X-ray Insights Unleashed: Pioneering the Enhancement of Multi-Label Long-Tail Data
Dec 24, 2025Long-tailed pulmonary anomalies in chest radiography present formidable diagnostic challenges. Despite the recent strides in diffusion-based methods for enhancing the representation of tailed lesions, the paucity of rare lesion exemplars curtails the generative capabilities of these approaches, thereby leaving the diagnostic precision less than optimal. In this paper, we propose a novel data synthesis pipeline designed to augment tail lesions utilizing a copious supply of conventional normal X-rays. Specifically, a sufficient quantity of normal samples is amassed to train a diffusion model capable of generating normal X-ray images. This pre-trained diffusion model is subsequently utilized to inpaint the head lesions present in the diseased X-rays, thereby preserving the tail classes as augmented training data. Additionally, we propose the integration of a Large Language Model Knowledge Guidance (LKG) module alongside a Progressive Incremental Learning (PIL) strategy to stabilize the inpainting fine-tuning process. Comprehensive evaluations conducted on the public lung datasets MIMIC and CheXpert demonstrate that the proposed method sets a new benchmark in performance.
SSA3D: Text-Conditioned Assisted Self-Supervised Framework for Automatic Dental Abutment Design
Dec 12, 2025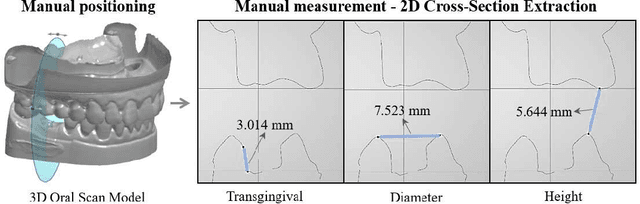
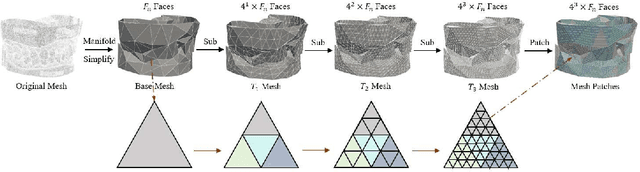
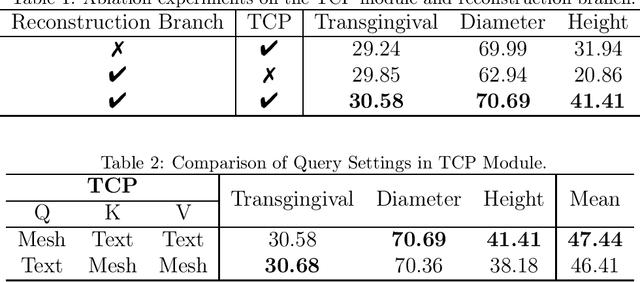
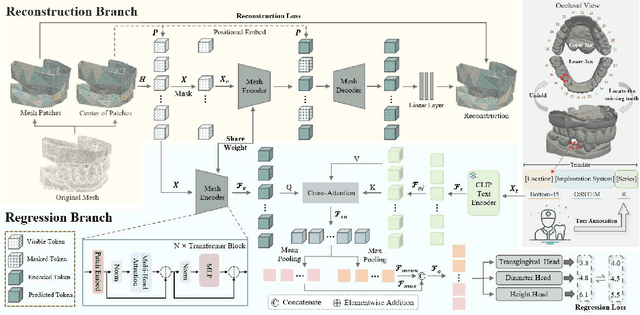
Abutment design is a critical step in dental implant restoration. However, manual design involves tedious measurement and fitting, and research on automating this process with AI is limited, due to the unavailability of large annotated datasets. Although self-supervised learning (SSL) can alleviate data scarcity, its need for pre-training and fine-tuning results in high computational costs and long training times. In this paper, we propose a Self-supervised assisted automatic abutment design framework (SS$A^3$D), which employs a dual-branch architecture with a reconstruction branch and a regression branch. The reconstruction branch learns to restore masked intraoral scan data and transfers the learned structural information to the regression branch. The regression branch then predicts the abutment parameters under supervised learning, which eliminates the separate pre-training and fine-tuning process. We also design a Text-Conditioned Prompt (TCP) module to incorporate clinical information (such as implant location, system, and series) into SS$A^3$D. This guides the network to focus on relevant regions and constrains the parameter predictions. Extensive experiments on a collected dataset show that SS$A^3$D saves half of the training time and achieves higher accuracy than traditional SSL methods. It also achieves state-of-the-art performance compared to other methods, significantly improving the accuracy and efficiency of automated abutment design.
Technical Report for Soccernet 2023 -- Dense Video Captioning
Oct 31, 2024


In the task of dense video captioning of Soccernet dataset, we propose to generate a video caption of each soccer action and locate the timestamp of the caption. Firstly, we apply Blip as our video caption framework to generate video captions. Then we locate the timestamp by using (1) multi-size sliding windows (2) temporal proposal generation and (3) proposal classification.
SSAD: Self-supervised Auxiliary Detection Framework for Panoramic X-ray based Dental Disease Diagnosis
Jun 20, 2024Panoramic X-ray is a simple and effective tool for diagnosing dental diseases in clinical practice. When deep learning models are developed to assist dentist in interpreting panoramic X-rays, most of their performance suffers from the limited annotated data, which requires dentist's expertise and a lot of time cost. Although self-supervised learning (SSL) has been proposed to address this challenge, the two-stage process of pretraining and fine-tuning requires even more training time and computational resources. In this paper, we present a self-supervised auxiliary detection (SSAD) framework, which is plug-and-play and compatible with any detectors. It consists of a reconstruction branch and a detection branch. Both branches are trained simultaneously, sharing the same encoder, without the need for finetuning. The reconstruction branch learns to restore the tooth texture of healthy or diseased teeth, while the detection branch utilizes these learned features for diagnosis. To enhance the encoder's ability to capture fine-grained features, we incorporate the image encoder of SAM to construct a texture consistency (TC) loss, which extracts image embedding from the input and output of reconstruction branch, and then enforces both embedding into the same feature space. Extensive experiments on the public DENTEX dataset through three detection tasks demonstrate that the proposed SSAD framework achieves state-of-the-art performance compared to mainstream object detection methods and SSL methods. The code is available at https://github.com/Dylonsword/SSAD
Simplify Implant Depth Prediction as Video Grounding: A Texture Perceive Implant Depth Prediction Network
Jun 07, 2024



Surgical guide plate is an important tool for the dental implant surgery. However, the design process heavily relies on the dentist to manually simulate the implant angle and depth. When deep neural networks have been applied to assist the dentist quickly locates the implant position, most of them are not able to determine the implant depth. Inspired by the video grounding task which localizes the starting and ending time of the target video segment, in this paper, we simplify the implant depth prediction as video grounding and develop a Texture Perceive Implant Depth Prediction Network (TPNet), which enables us to directly output the implant depth without complex measurements of oral bone. TPNet consists of an implant region detector (IRD) and an implant depth prediction network (IDPNet). IRD is an object detector designed to crop the candidate implant volume from the CBCT, which greatly saves the computation resource. IDPNet takes the cropped CBCT data to predict the implant depth. A Texture Perceive Loss (TPL) is devised to enable the encoder of IDPNet to perceive the texture variation among slices. Extensive experiments on a large dental implant dataset demonstrated that the proposed TPNet achieves superior performance than the existing methods.
SCPMan: Shape Context and Prior Constrained Multi-scale Attention Network for Pancreatic Segmentation
Dec 26, 2023Due to the poor prognosis of Pancreatic cancer, accurate early detection and segmentation are critical for improving treatment outcomes. However, pancreatic segmentation is challenged by blurred boundaries, high shape variability, and class imbalance. To tackle these problems, we propose a multiscale attention network with shape context and prior constraint for robust pancreas segmentation. Specifically, we proposed a Multi-scale Feature Extraction Module (MFE) and a Mixed-scale Attention Integration Module (MAI) to address unclear pancreas boundaries. Furthermore, a Shape Context Memory (SCM) module is introduced to jointly model semantics across scales and pancreatic shape. Active Shape Model (ASM) is further used to model the shape priors. Experiments on NIH and MSD datasets demonstrate the efficacy of our model, which improves the state-of-the-art Dice Score for 1.01% and 1.03% respectively. Our architecture provides robust segmentation performance, against the blurry boundaries, and variations in scale and shape of pancreas.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
TCSloT: Text Guided 3D Context and Slope Aware Triple Network for Dental Implant Position Prediction
Aug 10, 2023In implant prosthesis treatment, the surgical guide of implant is used to ensure accurate implantation. However, such design heavily relies on the manual location of the implant position. When deep neural network has been proposed to assist the dentist in locating the implant position, most of them take a single slice as input, which do not fully explore 3D contextual information and ignoring the influence of implant slope. In this paper, we design a Text Guided 3D Context and Slope Aware Triple Network (TCSloT) which enables the perception of contextual information from multiple adjacent slices and awareness of variation of implant slopes. A Texture Variation Perception (TVP) module is correspondingly elaborated to process the multiple slices and capture the texture variation among slices and a Slope-Aware Loss (SAL) is proposed to dynamically assign varying weights for the regression head. Additionally, we design a conditional text guidance (CTG) module to integrate the text condition (i.e., left, middle and right) from the CLIP for assisting the implant position prediction. Extensive experiments on a dental implant dataset through five-fold cross-validation demonstrated that the proposed TCSloT achieves superior performance than existing methods.
TCEIP: Text Condition Embedded Regression Network for Dental Implant Position Prediction
Jun 29, 2023When deep neural network has been proposed to assist the dentist in designing the location of dental implant, most of them are targeting simple cases where only one missing tooth is available. As a result, literature works do not work well when there are multiple missing teeth and easily generate false predictions when the teeth are sparsely distributed. In this paper, we are trying to integrate a weak supervision text, the target region, to the implant position regression network, to address above issues. We propose a text condition embedded implant position regression network (TCEIP), to embed the text condition into the encoder-decoder framework for improvement of the regression performance. A cross-modal interaction that consists of cross-modal attention (CMA) and knowledge alignment module (KAM) is proposed to facilitate the interaction between features of images and texts. The CMA module performs a cross-attention between the image feature and the text condition, and the KAM mitigates the knowledge gap between the image feature and the image encoder of the CLIP. Extensive experiments on a dental implant dataset through five-fold cross-validation demonstrated that the proposed TCEIP achieves superior performance than existing methods.