 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Texture-aware Masking for Self-Supervised Learning in 3D Dental CBCT Analysis
May 03, 2026Cone Beam Computed Tomography (CBCT) is pivotal for 3D diagnostic imaging in dentistry. However, the development of robust AI models for volumetric analysis is often constrained by the scarcity of large, annotated datasets. Self-supervised learning (SSL), particularly Masked Image Modeling (MIM), offers a promising pathway to leverage unlabeled data. A limitation of standard MIM is its reliance on random masking, which fails to prioritize diagnostically critical regions in dental CBCT volumes, such as subtle pathological changes and intricate anatomical boundaries. To address this, we propose ATMask, a novel adaptive masking strategy. Instead of applying random masks or employing computationally intensive attention modules, ATMask computes an inter-slice texture variation map to identify regions with high structural or textural complexity. These high-variation areas are then selectively masked during pre-training, compelling the model to learn richer contextual representations essential for inferring complex 3D morphological transitions. Furthermore, we contribute the first large-scale CBCT dataset, curated from both public and private sources, comprising 6,314 scans, for the dental AI model pretraining. Extensive experiments on three downstream dental CBCT tasks demonstrate that our ATMask enables more data-efficient and powerful representation learning than standard random masking and other advanced SSL baselines. The dataset and code will be released.
SSAD: Self-supervised Auxiliary Detection Framework for Panoramic X-ray based Dental Disease Diagnosis
Jun 20, 2024Panoramic X-ray is a simple and effective tool for diagnosing dental diseases in clinical practice. When deep learning models are developed to assist dentist in interpreting panoramic X-rays, most of their performance suffers from the limited annotated data, which requires dentist's expertise and a lot of time cost. Although self-supervised learning (SSL) has been proposed to address this challenge, the two-stage process of pretraining and fine-tuning requires even more training time and computational resources. In this paper, we present a self-supervised auxiliary detection (SSAD) framework, which is plug-and-play and compatible with any detectors. It consists of a reconstruction branch and a detection branch. Both branches are trained simultaneously, sharing the same encoder, without the need for finetuning. The reconstruction branch learns to restore the tooth texture of healthy or diseased teeth, while the detection branch utilizes these learned features for diagnosis. To enhance the encoder's ability to capture fine-grained features, we incorporate the image encoder of SAM to construct a texture consistency (TC) loss, which extracts image embedding from the input and output of reconstruction branch, and then enforces both embedding into the same feature space. Extensive experiments on the public DENTEX dataset through three detection tasks demonstrate that the proposed SSAD framework achieves state-of-the-art performance compared to mainstream object detection methods and SSL methods. The code is available at https://github.com/Dylonsword/SSAD
Simplify Implant Depth Prediction as Video Grounding: A Texture Perceive Implant Depth Prediction Network
Jun 07, 2024



Surgical guide plate is an important tool for the dental implant surgery. However, the design process heavily relies on the dentist to manually simulate the implant angle and depth. When deep neural networks have been applied to assist the dentist quickly locates the implant position, most of them are not able to determine the implant depth. Inspired by the video grounding task which localizes the starting and ending time of the target video segment, in this paper, we simplify the implant depth prediction as video grounding and develop a Texture Perceive Implant Depth Prediction Network (TPNet), which enables us to directly output the implant depth without complex measurements of oral bone. TPNet consists of an implant region detector (IRD) and an implant depth prediction network (IDPNet). IRD is an object detector designed to crop the candidate implant volume from the CBCT, which greatly saves the computation resource. IDPNet takes the cropped CBCT data to predict the implant depth. A Texture Perceive Loss (TPL) is devised to enable the encoder of IDPNet to perceive the texture variation among slices. Extensive experiments on a large dental implant dataset demonstrated that the proposed TPNet achieves superior performance than the existing methods.
TCSloT: Text Guided 3D Context and Slope Aware Triple Network for Dental Implant Position Prediction
Aug 10, 2023In implant prosthesis treatment, the surgical guide of implant is used to ensure accurate implantation. However, such design heavily relies on the manual location of the implant position. When deep neural network has been proposed to assist the dentist in locating the implant position, most of them take a single slice as input, which do not fully explore 3D contextual information and ignoring the influence of implant slope. In this paper, we design a Text Guided 3D Context and Slope Aware Triple Network (TCSloT) which enables the perception of contextual information from multiple adjacent slices and awareness of variation of implant slopes. A Texture Variation Perception (TVP) module is correspondingly elaborated to process the multiple slices and capture the texture variation among slices and a Slope-Aware Loss (SAL) is proposed to dynamically assign varying weights for the regression head. Additionally, we design a conditional text guidance (CTG) module to integrate the text condition (i.e., left, middle and right) from the CLIP for assisting the implant position prediction. Extensive experiments on a dental implant dataset through five-fold cross-validation demonstrated that the proposed TCSloT achieves superior performance than existing methods.
TCEIP: Text Condition Embedded Regression Network for Dental Implant Position Prediction
Jun 29, 2023When deep neural network has been proposed to assist the dentist in designing the location of dental implant, most of them are targeting simple cases where only one missing tooth is available. As a result, literature works do not work well when there are multiple missing teeth and easily generate false predictions when the teeth are sparsely distributed. In this paper, we are trying to integrate a weak supervision text, the target region, to the implant position regression network, to address above issues. We propose a text condition embedded implant position regression network (TCEIP), to embed the text condition into the encoder-decoder framework for improvement of the regression performance. A cross-modal interaction that consists of cross-modal attention (CMA) and knowledge alignment module (KAM) is proposed to facilitate the interaction between features of images and texts. The CMA module performs a cross-attention between the image feature and the text condition, and the KAM mitigates the knowledge gap between the image feature and the image encoder of the CLIP. Extensive experiments on a dental implant dataset through five-fold cross-validation demonstrated that the proposed TCEIP achieves superior performance than existing methods.
Two-Stream Regression Network for Dental Implant Position Prediction
May 17, 2023



In implant prosthesis treatment, the design of surgical guide requires lots of manual labors and is prone to subjective variations. When deep learning based methods has started to be applied to address this problem, the space between teeth are various and some of them might present similar texture characteristic with the actual implant region. Both problems make a big challenge for the implant position prediction. In this paper, we develop a two-stream implant position regression framework (TSIPR), which consists of an implant region detector (IRD) and a multi-scale patch embedding regression network (MSPENet), to address this issue. For the training of IRD, we extend the original annotation to provide additional supervisory information, which contains much more rich characteristic and do not introduce extra labeling costs. A multi-scale patch embedding module is designed for the MSPENet to adaptively extract features from the images with various tooth spacing. The global-local feature interaction block is designed to build the encoder of MSPENet, which combines the transformer and convolution for enriched feature representation. During inference, the RoI mask extracted from the IRD is used to refine the prediction results of the MSPENet. Extensive experiments on a dental implant dataset through five-fold cross-validation demonstrated that the proposed TSIPR achieves superior performance than existing methods.
ImplantFormer: Vision Transformer based Implant Position Regression Using Dental CBCT Data
Oct 29, 2022Implant prosthesis is the most optimum treatment of dentition defect or dentition loss, which usually involves a surgical guide design process to decide the position of implant. However, such design heavily relies on the subjective experiences of dentist. To relieve this problem, in this paper, a transformer based Implant Position Regression Network, ImplantFormer, is proposed to automatically predict the implant position based on the oral CBCT data. The 3D CBCT data is firstly transformed into a series of 2D transverse plane slice views. ImplantFormer is then proposed to predict the position of implant based on the 2D slices of crown images. Convolutional stem and decoder are designed to coarsely extract image feature before the operation of patch embedding and integrate multi-levels feature map for robust prediction. The predictions of our network at tooth crown area are finally projected back to the positions at tooth root. As both long-range relationship and local features are involved, our approach can better represent global information and achieves better location performance than the state-of-the-art detectors. Experimental results on a dataset of 128 patients, collected from Shenzhen University General Hospital, show that our ImplantFormer achieves superior performance than benchmarks.
IPS300+: a Challenging Multimodal Dataset for Intersection Perception System
Jun 05, 2021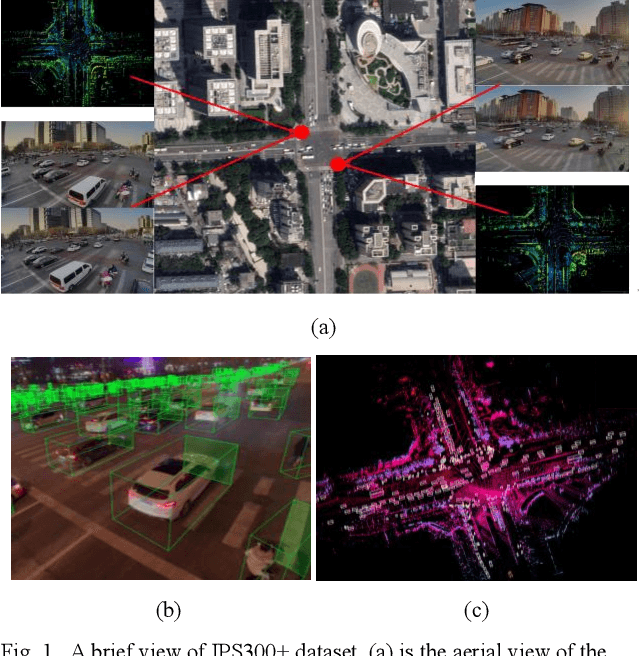
Due to the high complexity and occlusion, insufficient perception in the crowded urban intersection can be a serious safety risk for both human drivers and autonomous algorithms, whereas CVIS (Cooperative Vehicle Infrastructure System) is a proposed solution for full-participants perception in this scenario. However, the research on roadside multimodal perception is still in its infancy, and there is no open-source dataset for such scenario. Accordingly, this paper fills the gap. Through an IPS (Intersection Perception System) installed at the diagonal of the intersection, this paper proposes a high-quality multimodal dataset for the intersection perception task. The center of the experimental intersection covers an area of 3000m2, and the extended distance reaches 300m, which is typical for CVIS. The first batch of open-source data includes 14198 frames, and each frame has an average of 319.84 labels, which is 9.6 times larger than the most crowded dataset (H3D dataset in 2019) by now. In order to facilitate further study, this dataset tries to keep the label documents consistent with the KITTI dataset, and a standardized benchmark is created for algorithm evaluation. Our dataset is available at: http://www.openmpd.com/column/other_datasets.