 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
Online Segment Any 3D Thing as Instance Tracking
Dec 08, 2025Online, real-time, and fine-grained 3D segmentation constitutes a fundamental capability for embodied intelligent agents to perceive and comprehend their operational environments. Recent advancements employ predefined object queries to aggregate semantic information from Vision Foundation Models (VFMs) outputs that are lifted into 3D point clouds, facilitating spatial information propagation through inter-query interactions. Nevertheless, perception is an inherently dynamic process, rendering temporal understanding a critical yet overlooked dimension within these prevailing query-based pipelines. Therefore, to further unlock the temporal environmental perception capabilities of embodied agents, our work reconceptualizes online 3D segmentation as an instance tracking problem (AutoSeg3D). Our core strategy involves utilizing object queries for temporal information propagation, where long-term instance association promotes the coherence of features and object identities, while short-term instance update enriches instant observations. Given that viewpoint variations in embodied robotics often lead to partial object visibility across frames, this mechanism aids the model in developing a holistic object understanding beyond incomplete instantaneous views. Furthermore, we introduce spatial consistency learning to mitigate the fragmentation problem inherent in VFMs, yielding more comprehensive instance information for enhancing the efficacy of both long-term and short-term temporal learning. The temporal information exchange and consistency learning facilitated by these sparse object queries not only enhance spatial comprehension but also circumvent the computational burden associated with dense temporal point cloud interactions. Our method establishes a new state-of-the-art, surpassing ESAM by 2.8 AP on ScanNet200 and delivering consistent gains on ScanNet, SceneNN, and 3RScan datasets.
CanonSwap: High-Fidelity and Consistent Video Face Swapping via Canonical Space Modulation
Jul 03, 2025Video face swapping aims to address two primary challenges: effectively transferring the source identity to the target video and accurately preserving the dynamic attributes of the target face, such as head poses, facial expressions, lip-sync, \etc. Existing methods mainly focus on achieving high-quality identity transfer but often fall short in maintaining the dynamic attributes of the target face, leading to inconsistent results. We attribute this issue to the inherent coupling of facial appearance and motion in videos. To address this, we propose CanonSwap, a novel video face-swapping framework that decouples motion information from appearance information. Specifically, CanonSwap first eliminates motion-related information, enabling identity modification within a unified canonical space. Subsequently, the swapped feature is reintegrated into the original video space, ensuring the preservation of the target face's dynamic attributes. To further achieve precise identity transfer with minimal artifacts and enhanced realism, we design a Partial Identity Modulation module that adaptively integrates source identity features using a spatial mask to restrict modifications to facial regions. Additionally, we introduce several fine-grained synchronization metrics to comprehensively evaluate the performance of video face swapping methods. Extensive experiments demonstrate that our method significantly outperforms existing approaches in terms of visual quality, temporal consistency, and identity preservation. Our project page are publicly available at https://luoxyhappy.github.io/CanonSwap/.
Unveiling the Hidden: Movie Genre and User Bias in Spoiler Detection
Apr 28, 2025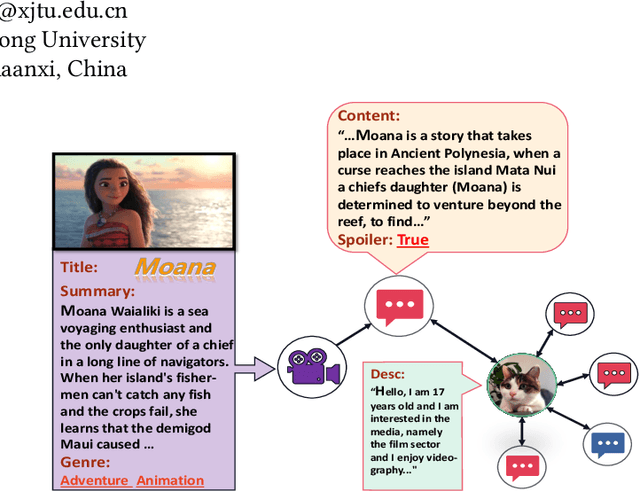
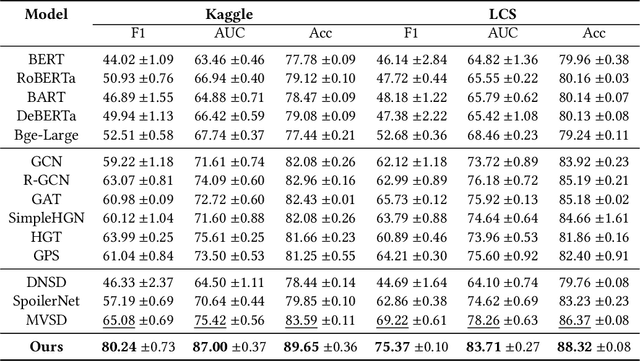
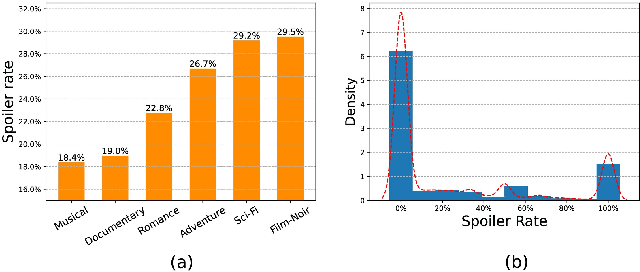
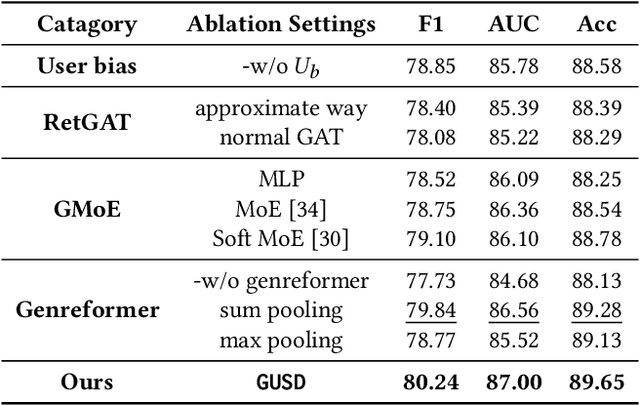
Spoilers in movie reviews are important on platforms like IMDb and Rotten Tomatoes, offering benefits and drawbacks. They can guide some viewers' choices but also affect those who prefer no plot details in advance, making effective spoiler detection essential. Existing spoiler detection methods mainly analyze review text, often overlooking the impact of movie genres and user bias, limiting their effectiveness. To address this, we analyze movie review data, finding genre-specific variations in spoiler rates and identifying that certain users are more likely to post spoilers. Based on these findings, we introduce a new spoiler detection framework called GUSD (The code is available at https://github.com/AI-explorer-123/GUSD) (Genre-aware and User-specific Spoiler Detection), which incorporates genre-specific data and user behavior bias. User bias is calculated through dynamic graph modeling of review history. Additionally, the R2GFormer module combines RetGAT (Retentive Graph Attention Network) for graph information and GenreFormer for genre-specific aggregation. The GMoE (Genre-Aware Mixture of Experts) model further assigns reviews to specialized experts based on genre. Extensive testing on benchmark datasets shows that GUSD achieves state-of-the-art results. This approach advances spoiler detection by addressing genre and user-specific patterns, enhancing user experience on movie review platforms.
GridShow: Omni Visual Generation
Dec 17, 2024In this paper, we introduce GRID, a novel paradigm that reframes a broad range of visual generation tasks as the problem of arranging grids, akin to film strips. At its core, GRID transforms temporal sequences into grid layouts, enabling image generation models to process visual sequences holistically. To achieve both layout consistency and motion coherence, we develop a parallel flow-matching training strategy that combines layout matching and temporal losses, guided by a coarse-to-fine schedule that evolves from basic layouts to precise motion control. Our approach demonstrates remarkable efficiency, achieving up to 35 faster inference speeds while using 1/1000 of the computational resources compared to specialized models. Extensive experiments show that GRID exhibits exceptional versatility across diverse visual generation tasks, from Text-to-Video to 3D Editing, while maintaining its foundational image generation capabilities. This dual strength in both expanded applications and preserved core competencies establishes GRID as an efficient and versatile omni-solution for visual generation.
SSAD: Self-supervised Auxiliary Detection Framework for Panoramic X-ray based Dental Disease Diagnosis
Jun 20, 2024Panoramic X-ray is a simple and effective tool for diagnosing dental diseases in clinical practice. When deep learning models are developed to assist dentist in interpreting panoramic X-rays, most of their performance suffers from the limited annotated data, which requires dentist's expertise and a lot of time cost. Although self-supervised learning (SSL) has been proposed to address this challenge, the two-stage process of pretraining and fine-tuning requires even more training time and computational resources. In this paper, we present a self-supervised auxiliary detection (SSAD) framework, which is plug-and-play and compatible with any detectors. It consists of a reconstruction branch and a detection branch. Both branches are trained simultaneously, sharing the same encoder, without the need for finetuning. The reconstruction branch learns to restore the tooth texture of healthy or diseased teeth, while the detection branch utilizes these learned features for diagnosis. To enhance the encoder's ability to capture fine-grained features, we incorporate the image encoder of SAM to construct a texture consistency (TC) loss, which extracts image embedding from the input and output of reconstruction branch, and then enforces both embedding into the same feature space. Extensive experiments on the public DENTEX dataset through three detection tasks demonstrate that the proposed SSAD framework achieves state-of-the-art performance compared to mainstream object detection methods and SSL methods. The code is available at https://github.com/Dylonsword/SSAD
MMoE: Robust Spoiler Detection with Multi-modal Information and Domain-aware Mixture-of-Experts
Mar 14, 2024



Online movie review websites are valuable for information and discussion about movies. However, the massive spoiler reviews detract from the movie-watching experience, making spoiler detection an important task. Previous methods simply focus on reviews' text content, ignoring the heterogeneity of information in the platform. For instance, the metadata and the corresponding user's information of a review could be helpful. Besides, the spoiler language of movie reviews tends to be genre-specific, thus posing a domain generalization challenge for existing methods. To this end, we propose MMoE, a multi-modal network that utilizes information from multiple modalities to facilitate robust spoiler detection and adopts Mixture-of-Experts to enhance domain generalization. MMoE first extracts graph, text, and meta feature from the user-movie network, the review's textual content, and the review's metadata respectively. To handle genre-specific spoilers, we then adopt Mixture-of-Experts architecture to process information in three modalities to promote robustness. Finally, we use an expert fusion layer to integrate the features from different perspectives and make predictions based on the fused embedding. Experiments demonstrate that MMoE achieves state-of-the-art performance on two widely-used spoiler detection datasets, surpassing previous SOTA methods by 2.56% and 8.41% in terms of accuracy and F1-score. Further experiments also demonstrate MMoE's superiority in robustness and generalization.
LMBot: Distilling Graph Knowledge into Language Model for Graph-less Deployment in Twitter Bot Detection
Jul 03, 2023As malicious actors employ increasingly advanced and widespread bots to disseminate misinformation and manipulate public opinion, the detection of Twitter bots has become a crucial task. Though graph-based Twitter bot detection methods achieve state-of-the-art performance, we find that their inference depends on the neighbor users multi-hop away from the targets, and fetching neighbors is time-consuming and may introduce bias. At the same time, we find that after finetuning on Twitter bot detection, pretrained language models achieve competitive performance and do not require a graph structure during deployment. Inspired by this finding, we propose a novel bot detection framework LMBot that distills the knowledge of graph neural networks (GNNs) into language models (LMs) for graph-less deployment in Twitter bot detection to combat the challenge of data dependency. Moreover, LMBot is compatible with graph-based and graph-less datasets. Specifically, we first represent each user as a textual sequence and feed them into the LM for domain adaptation. For graph-based datasets, the output of LMs provides input features for the GNN, enabling it to optimize for bot detection and distill knowledge back to the LM in an iterative, mutually enhancing process. Armed with the LM, we can perform graph-less inference, which resolves the graph data dependency and sampling bias issues. For datasets without graph structure, we simply replace the GNN with an MLP, which has also shown strong performance. Our experiments demonstrate that LMBot achieves state-of-the-art performance on four Twitter bot detection benchmarks. Extensive studies also show that LMBot is more robust, versatile, and efficient compared to graph-based Twitter bot detection methods.
Enhancing Model Performance in Multilingual Information Retrieval with Comprehensive Data Engineering Techniques
Feb 14, 2023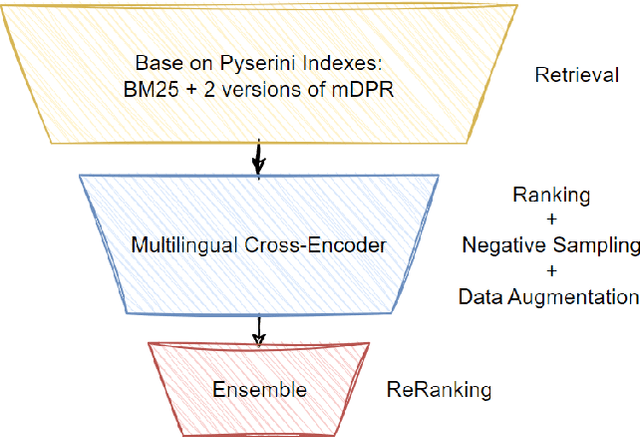


In this paper, we present our solution to the Multilingual Information Retrieval Across a Continuum of Languages (MIRACL) challenge of WSDM CUP 2023\footnote{https://project-miracl.github.io/}. Our solution focuses on enhancing the ranking stage, where we fine-tune pre-trained multilingual transformer-based models with MIRACL dataset. Our model improvement is mainly achieved through diverse data engineering techniques, including the collection of additional relevant training data, data augmentation, and negative sampling. Our fine-tuned model effectively determines the semantic relevance between queries and documents, resulting in a significant improvement in the efficiency of the multilingual information retrieval process. Finally, Our team is pleased to achieve remarkable results in this challenging competition, securing 2nd place in the Surprise-Languages track with a score of 0.835 and 3rd place in the Known-Languages track with an average nDCG@10 score of 0.716 across the 16 known languages on the final leaderboard.
Using Deep Mixture-of-Experts to Detect Word Meaning Shift for TempoWiC
Nov 07, 2022



This paper mainly describes the dma submission to the TempoWiC task, which achieves a macro-F1 score of 77.05% and attains the first place in this task. We first explore the impact of different pre-trained language models. Then we adopt data cleaning, data augmentation, and adversarial training strategies to enhance the model generalization and robustness. For further improvement, we integrate POS information and word semantic representation using a Mixture-of-Experts (MoE) approach. The experimental results show that MoE can overcome the feature overuse issue and combine the context, POS, and word semantic features well. Additionally, we use a model ensemble method for the final prediction, which has been proven effective by many research works.