 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence-Level Relation Extraction via Contrastive Learning with Descriptive Relation Prompts
Apr 11, 2023



Sentence-level relation extraction aims to identify the relation between two entities for a given sentence. The existing works mostly focus on obtaining a better entity representation and adopting a multi-label classifier for relation extraction. A major limitation of these works is that they ignore background relational knowledge and the interrelation between entity types and candidate relations. In this work, we propose a new paradigm, Contrastive Learning with Descriptive Relation Prompts(CTL-DRP), to jointly consider entity information, relational knowledge and entity type restrictions. In particular, we introduce an improved entity marker and descriptive relation prompts when generating contextual embedding, and utilize contrastive learning to rank the restricted candidate relations. The CTL-DRP obtains a competitive F1-score of 76.7% on TACRED. Furthermore, the new presented paradigm achieves F1-scores of 85.8% and 91.6% on TACREV and Re-TACRED respectively, which are both the state-of-the-art performance.
Enhancing Model Performance in Multilingual Information Retrieval with Comprehensive Data Engineering Techniques
Feb 14, 2023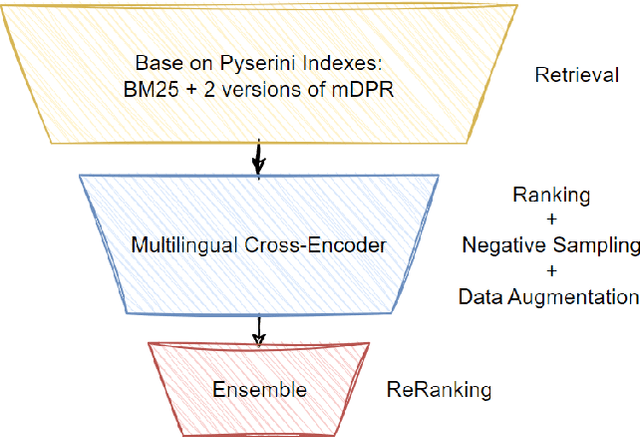
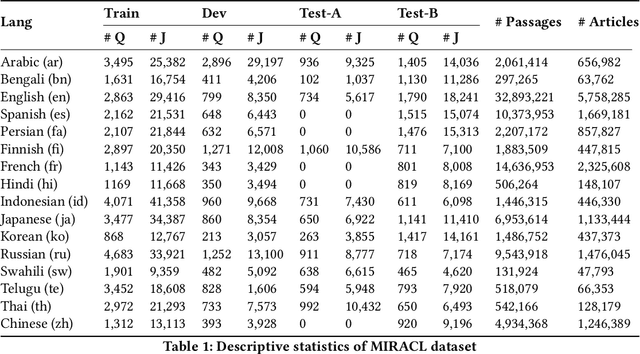


In this paper, we present our solution to the Multilingual Information Retrieval Across a Continuum of Languages (MIRACL) challenge of WSDM CUP 2023\footnote{https://project-miracl.github.io/}. Our solution focuses on enhancing the ranking stage, where we fine-tune pre-trained multilingual transformer-based models with MIRACL dataset. Our model improvement is mainly achieved through diverse data engineering techniques, including the collection of additional relevant training data, data augmentation, and negative sampling. Our fine-tuned model effectively determines the semantic relevance between queries and documents, resulting in a significant improvement in the efficiency of the multilingual information retrieval process. Finally, Our team is pleased to achieve remarkable results in this challenging competition, securing 2nd place in the Surprise-Languages track with a score of 0.835 and 3rd place in the Known-Languages track with an average nDCG@10 score of 0.716 across the 16 known languages on the final leaderboard.
OPD@NL4Opt: An ensemble approach for the NER task of the optimization problem
Jan 06, 2023In this paper, we present an ensemble approach for the NL4Opt competition subtask 1(NER task). For this task, we first fine tune the pretrained language models based on the competition dataset. Then we adopt differential learning rates and adversarial training strategies to enhance the model generalization and robustness. Additionally, we use a model ensemble method for the final prediction, which achieves a micro-averaged F1 score of 93.3% and attains the second prize in the NER task.
Using Deep Mixture-of-Experts to Detect Word Meaning Shift for TempoWiC
Nov 07, 2022



This paper mainly describes the dma submission to the TempoWiC task, which achieves a macro-F1 score of 77.05% and attains the first place in this task. We first explore the impact of different pre-trained language models. Then we adopt data cleaning, data augmentation, and adversarial training strategies to enhance the model generalization and robustness. For further improvement, we integrate POS information and word semantic representation using a Mixture-of-Experts (MoE) approach. The experimental results show that MoE can overcome the feature overuse issue and combine the context, POS, and word semantic features well. Additionally, we use a model ensemble method for the final prediction, which has been proven effective by many research works.
A Semantic Alignment System for Multilingual Query-Product Retrieval
Aug 05, 2022
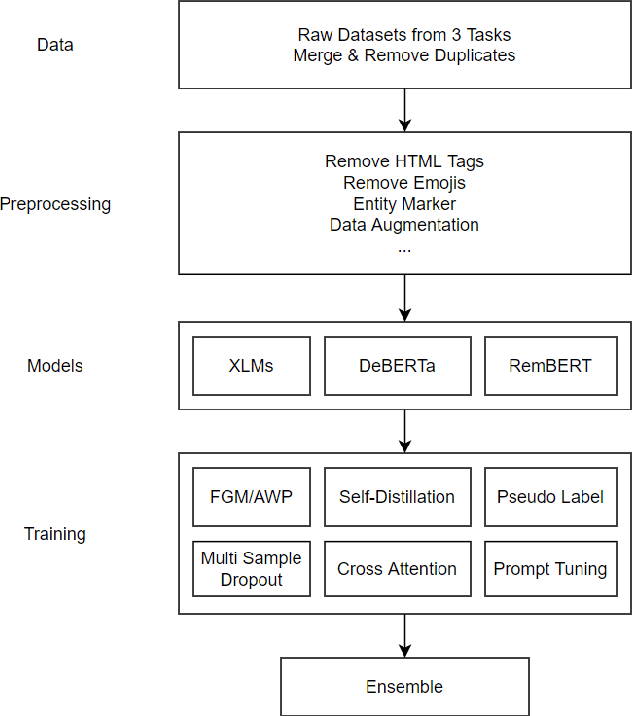
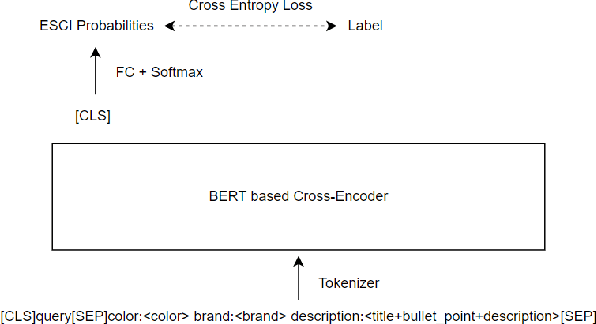
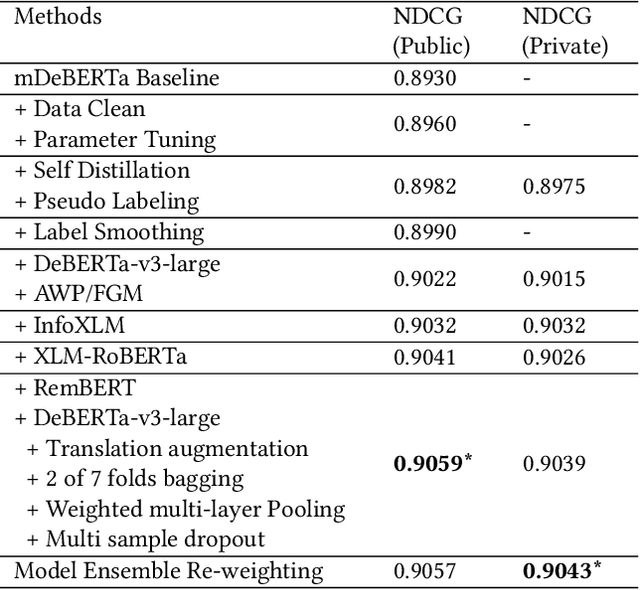
This paper mainly describes our winning solution (team name: www) to Amazon ESCI Challenge of KDD CUP 2022, which achieves a NDCG score of 0.9043 and wins the first place on task 1: the query-product ranking track. In this competition, participants are provided with a real-world large-scale multilingual shopping queries data set and it contains query-product pairs in English, Japanese and Spanish. Three different tasks are proposed in this competition, including ranking the results list as task 1, classifying the query/product pairs into Exact, Substitute, Complement, or Irrelevant (ESCI) categories as task 2 and identifying substitute products for a given query as task 3. We mainly focus on task 1 and propose a semantic alignment system for multilingual query-product retrieval. Pre-trained multilingual language models (LM) are adopted to get the semantic representation of queries and products. Our models are all trained with cross-entropy loss to classify the query-product pairs into ESCI 4 categories at first, and then we use weighted sum with the 4-class probabilities to get the score for ranking. To further boost the model, we also do elaborative data preprocessing, data augmentation by translation, specially handling English texts with English LMs, adversarial training with AWP and FGM, self distillation, pseudo labeling, label smoothing and ensemble. Finally, Our solution outperforms others both on public and private leaderboard.
Applying Feature Underspecified Lexicon Phonological Features in Multilingual Text-to-Speech
Apr 14, 2022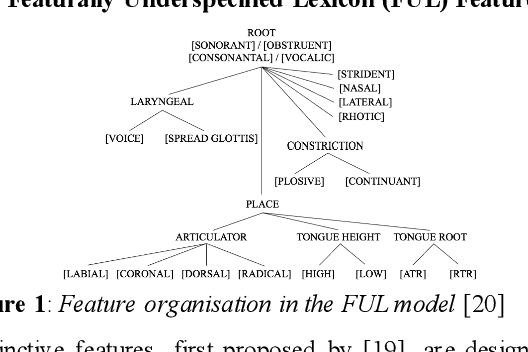
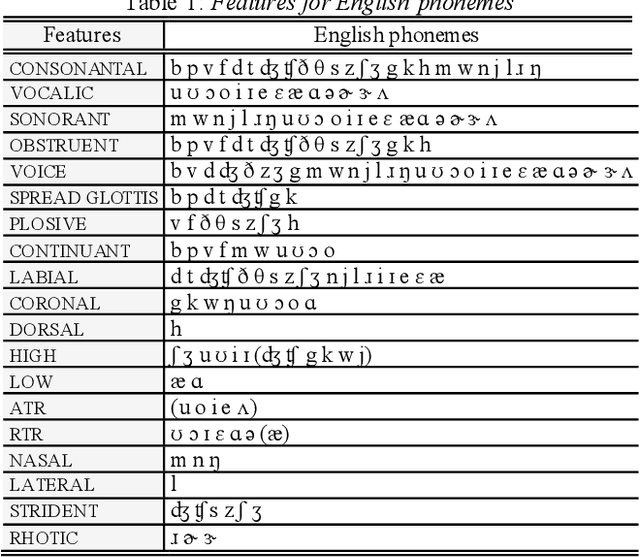

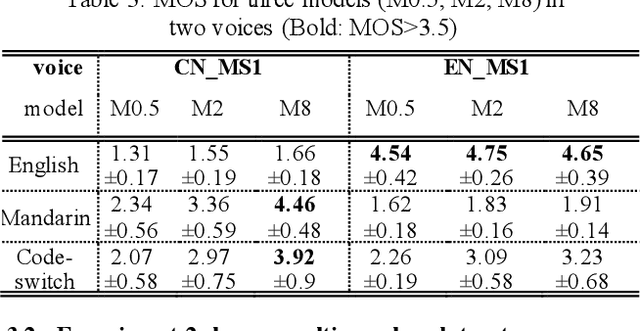
This study investigates whether the phonological features derived from the Featurally Underspecified Lexicon model can be applied in text-to-speech systems to generate native and non-native speech in English and Mandarin. We present a mapping of ARPABET/pinyin to SAMPA/SAMPA-SC and then to phonological features. This mapping was tested for whether it could lead to the successful generation of native, non-native, and code-switched speech in the two languages. We ran two experiments, one with a small dataset and one with a larger dataset. The results supported that phonological features could be used as a feasible input system for languages in or not in the train data, although further investigation is needed to improve model performance. The results lend support to FUL by presenting successfully synthesised output, and by having the output carrying a source-language accent when synthesising a language not in the training data. The TTS process stimulated human second language acquisition process and thus also confirm FUL's ability to account for acquisition.
Applying Phonological Features in Multilingual Text-To-Speech
Oct 10, 2021
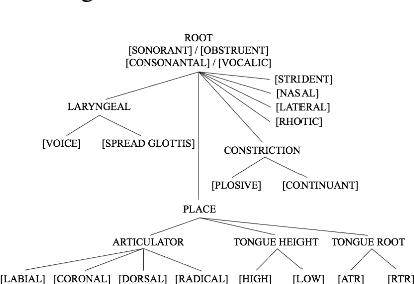

This study investigates whether phonological features can be applied in text-to-speech systems to generate native and non-native speech in English and Mandarin. We present a mapping of ARPABET/pinyin to SAMPA/SAMPA-SC and then to phonological features. We tested whether this mapping could lead to the successful generation of native, non-native, and code-switched speech in the two languages. We ran two experiments, one with a small dataset and one with a larger dataset. The results proved that phonological features could be used as a feasible input system, although further investigation is needed to improve model performance. The accented output generated by the TTS models also helps with understanding human second language acquisition processes.