 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Model Performance in Multilingual Information Retrieval with Comprehensive Data Engineering Techniques
Paper and Code
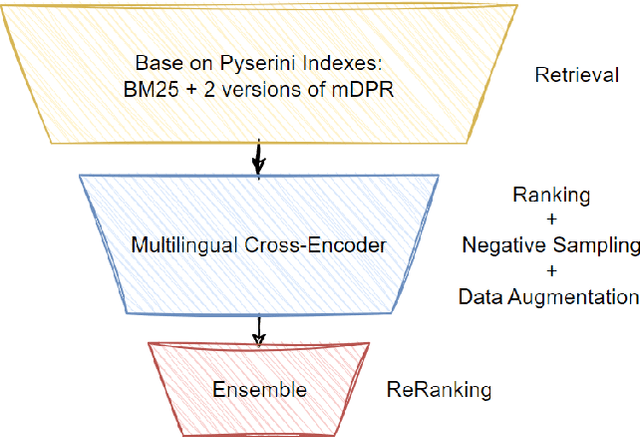
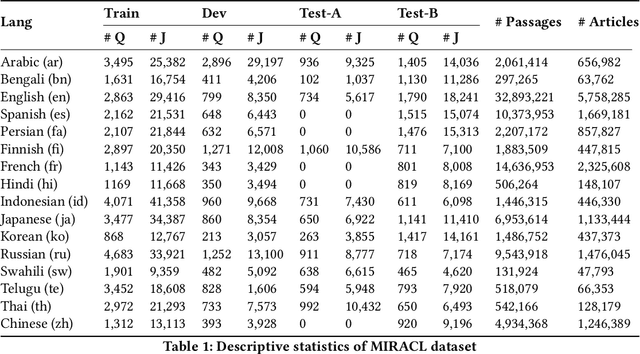


In this paper, we present our solution to the Multilingual Information Retrieval Across a Continuum of Languages (MIRACL) challenge of WSDM CUP 2023\footnote{https://project-miracl.github.io/}. Our solution focuses on enhancing the ranking stage, where we fine-tune pre-trained multilingual transformer-based models with MIRACL dataset. Our model improvement is mainly achieved through diverse data engineering techniques, including the collection of additional relevant training data, data augmentation, and negative sampling. Our fine-tuned model effectively determines the semantic relevance between queries and documents, resulting in a significant improvement in the efficiency of the multilingual information retrieval process. Finally, Our team is pleased to achieve remarkable results in this challenging competition, securing 2nd place in the Surprise-Languages track with a score of 0.835 and 3rd place in the Known-Languages track with an average nDCG@10 score of 0.716 across the 16 known languages on the final leaderboard.