 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
OPDAI at SemEval-2024 Task 6: Small LLMs can Accelerate Hallucination Detection with Weakly Supervised Data
Feb 20, 2024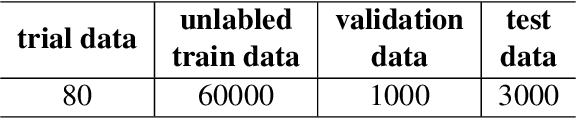
This paper mainly describes a unified system for hallucination detection of LLMs, which wins the second prize in the model-agnostic track of the SemEval-2024 Task 6, and also achieves considerable results in the model-aware track. This task aims to detect hallucination with LLMs for three different text-generation tasks without labeled training data. We utilize prompt engineering and few-shot learning to verify the performance of different LLMs on the validation data. Then we select the LLMs with better performance to generate high-quality weakly supervised training data, which not only satisfies the consistency of different LLMs, but also satisfies the consistency of the optimal LLM with different sampling parameters. Furthermore, we finetune different LLMs by using the constructed training data, and finding that a relatively small LLM can achieve a competitive level of performance in hallucination detection, when compared to the large LLMs and the prompt-based approaches using GPT-4.
Enhancing Model Performance in Multilingual Information Retrieval with Comprehensive Data Engineering Techniques
Feb 14, 2023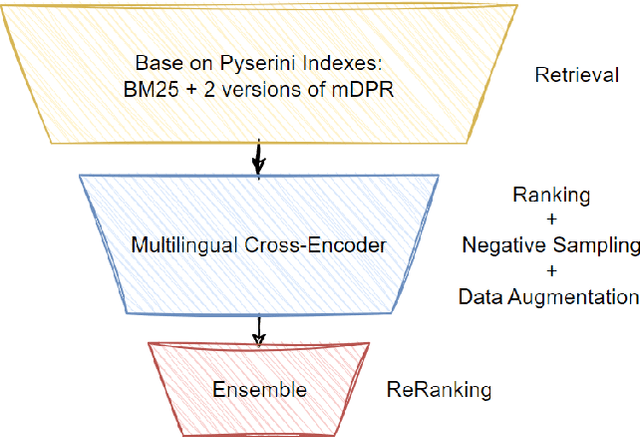
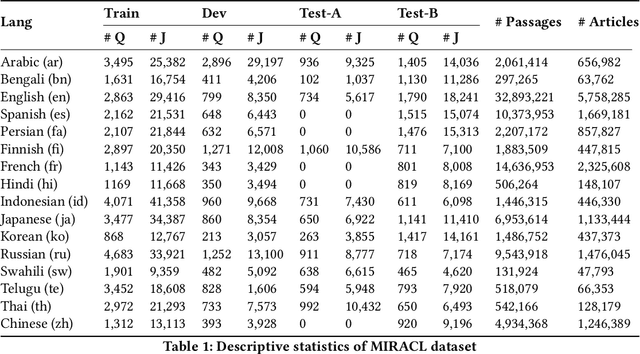


In this paper, we present our solution to the Multilingual Information Retrieval Across a Continuum of Languages (MIRACL) challenge of WSDM CUP 2023\footnote{https://project-miracl.github.io/}. Our solution focuses on enhancing the ranking stage, where we fine-tune pre-trained multilingual transformer-based models with MIRACL dataset. Our model improvement is mainly achieved through diverse data engineering techniques, including the collection of additional relevant training data, data augmentation, and negative sampling. Our fine-tuned model effectively determines the semantic relevance between queries and documents, resulting in a significant improvement in the efficiency of the multilingual information retrieval process. Finally, Our team is pleased to achieve remarkable results in this challenging competition, securing 2nd place in the Surprise-Languages track with a score of 0.835 and 3rd place in the Known-Languages track with an average nDCG@10 score of 0.716 across the 16 known languages on the final leaderboard.
Using Deep Mixture-of-Experts to Detect Word Meaning Shift for TempoWiC
Nov 07, 2022



This paper mainly describes the dma submission to the TempoWiC task, which achieves a macro-F1 score of 77.05% and attains the first place in this task. We first explore the impact of different pre-trained language models. Then we adopt data cleaning, data augmentation, and adversarial training strategies to enhance the model generalization and robustness. For further improvement, we integrate POS information and word semantic representation using a Mixture-of-Experts (MoE) approach. The experimental results show that MoE can overcome the feature overuse issue and combine the context, POS, and word semantic features well. Additionally, we use a model ensemble method for the final prediction, which has been proven effective by many research works.
Image Quality Assessment with Gradient Siamese Network
Aug 08, 2022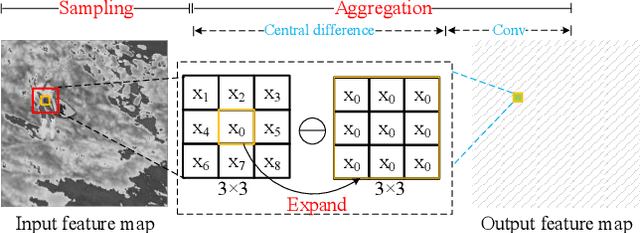
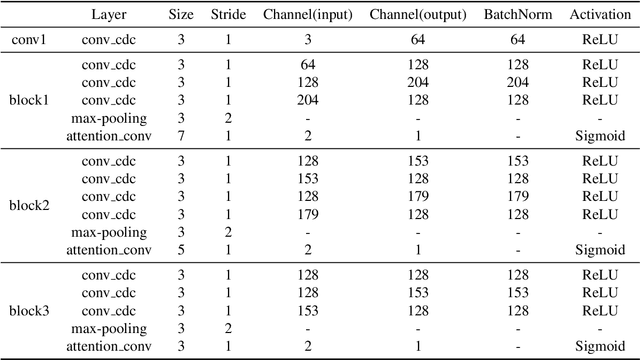
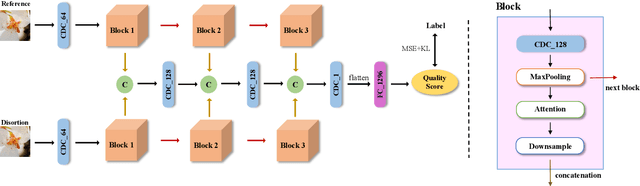
In this work, we introduce Gradient Siamese Network (GSN) for image quality assessment. The proposed method is skilled in capturing the gradient features between distorted images and reference images in full-reference image quality assessment(IQA) task. We utilize Central Differential Convolution to obtain both semantic features and detail difference hidden in image pair. Furthermore, spatial attention guides the network to concentrate on regions related to image detail. For the low-level, mid-level and high-level features extracted by the network, we innovatively design a multi-level fusion method to improve the efficiency of feature utilization. In addition to the common mean square error supervision, we further consider the relative distance among batch samples and successfully apply KL divergence loss to the image quality assessment task. We experimented the proposed algorithm GSN on several publicly available datasets and proved its superior performance. Our network won the second place in NTIRE 2022 Perceptual Image Quality Assessment Challenge track 1 Full-Reference.
* 10 pages, 5 figures, Computer Vision and Pattern Recognition (CVPR) Workshops
Multi-Frames Temporal Abnormal Clues Learning Method for Face Anti-Spoofing
Aug 08, 2022
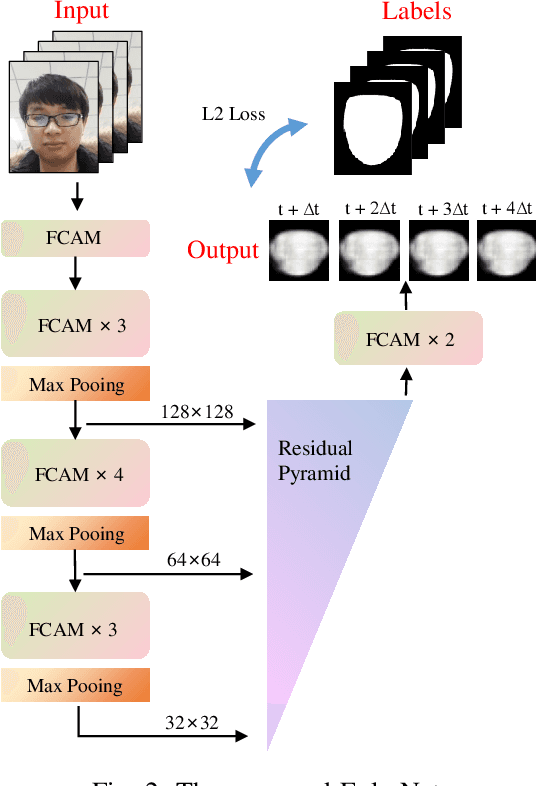
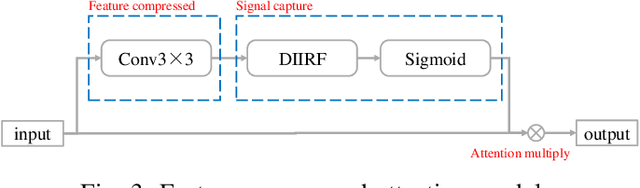
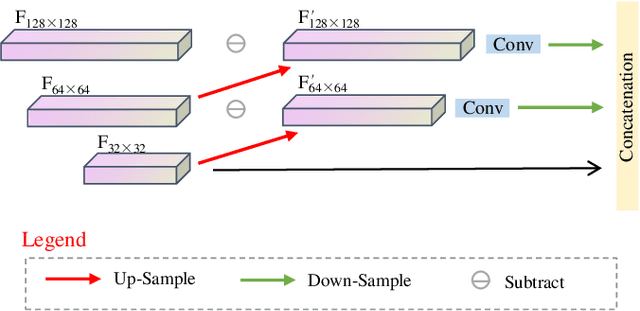
Face anti-spoofing researches are widely used in face recognition and has received more attention from industry and academics. In this paper, we propose the EulerNet, a new temporal feature fusion network in which the differential filter and residual pyramid are used to extract and amplify abnormal clues from continuous frames, respectively. A lightweight sample labeling method based on face landmarks is designed to label large-scale samples at a lower cost and has better results than other methods such as 3D camera. Finally, we collect 30,000 live and spoofing samples using various mobile ends to create a dataset that replicates various forms of attacks in a real-world setting. Extensive experiments on public OULU-NPU show that our algorithm is superior to the state of art and our solution has already been deployed in real-world systems servicing millions of users.
A Semantic Alignment System for Multilingual Query-Product Retrieval
Aug 05, 2022
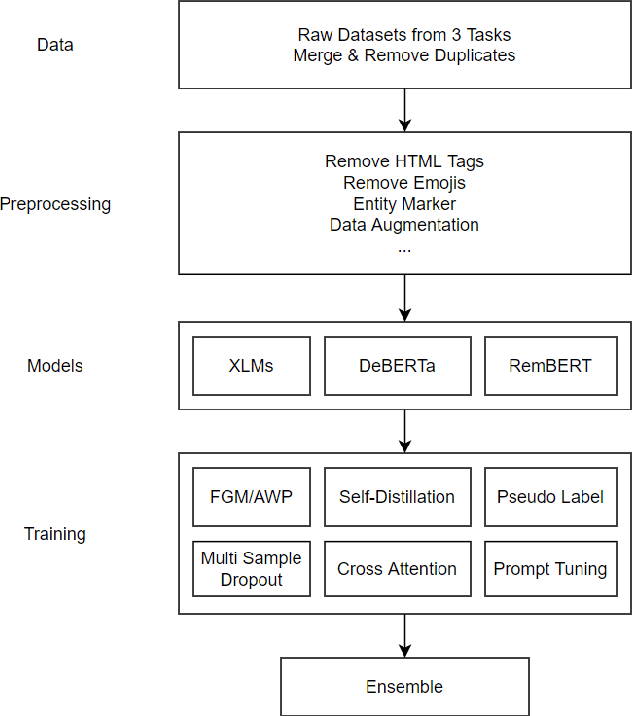
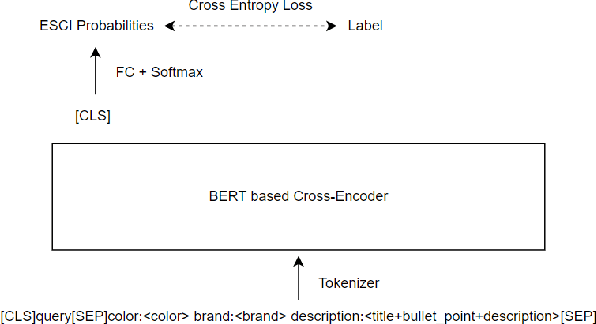
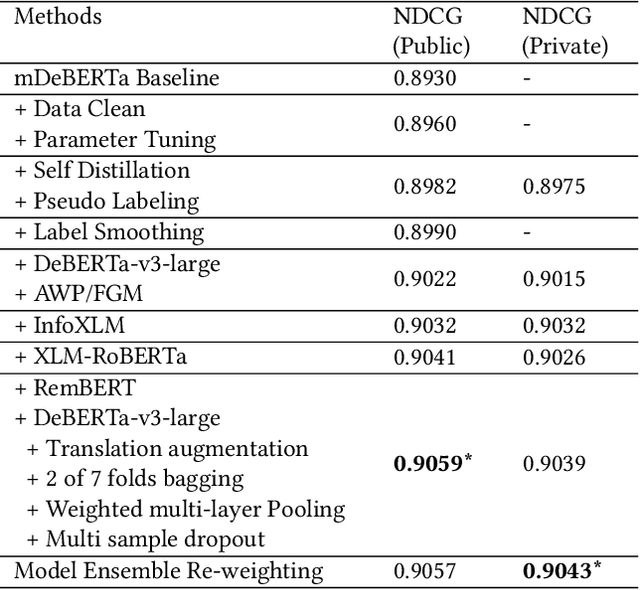
This paper mainly describes our winning solution (team name: www) to Amazon ESCI Challenge of KDD CUP 2022, which achieves a NDCG score of 0.9043 and wins the first place on task 1: the query-product ranking track. In this competition, participants are provided with a real-world large-scale multilingual shopping queries data set and it contains query-product pairs in English, Japanese and Spanish. Three different tasks are proposed in this competition, including ranking the results list as task 1, classifying the query/product pairs into Exact, Substitute, Complement, or Irrelevant (ESCI) categories as task 2 and identifying substitute products for a given query as task 3. We mainly focus on task 1 and propose a semantic alignment system for multilingual query-product retrieval. Pre-trained multilingual language models (LM) are adopted to get the semantic representation of queries and products. Our models are all trained with cross-entropy loss to classify the query-product pairs into ESCI 4 categories at first, and then we use weighted sum with the 4-class probabilities to get the score for ranking. To further boost the model, we also do elaborative data preprocessing, data augmentation by translation, specially handling English texts with English LMs, adversarial training with AWP and FGM, self distillation, pseudo labeling, label smoothing and ensemble. Finally, Our solution outperforms others both on public and private leaderboard.
An Effective Way for Cross-Market Recommendation with Hybrid Pre-Ranking and Ranking Models
Mar 02, 2022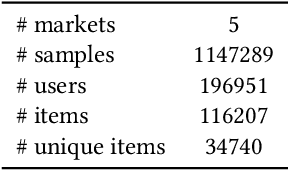
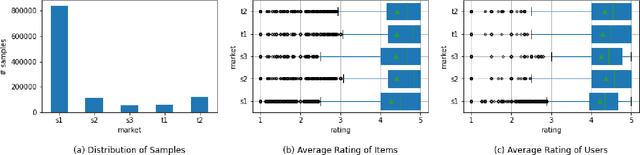
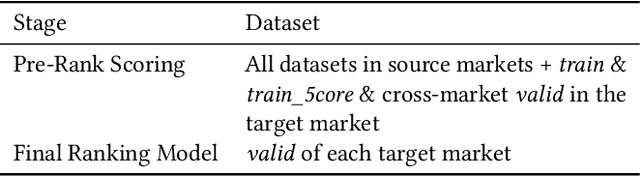
The Cross-Market Recommendation task of WSDM CUP 2022 is about finding solutions to improve individual recommendation systems in resource-scarce target markets by leveraging data from similar high-resource source markets. Finally, our team OPDAI won the first place with NDCG@10 score of 0.6773 on the leaderboard. Our solution to this task will be detailed in this paper. To better transform information from source markets to target markets, we adopt two stages of ranking. In pre-ranking stage, we adopt diverse pre-ranking methods or models to do feature generation. After elaborate feature analysis and feature selection, we train LightGBM with 10-fold bagging to do the final ranking.