 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPDAI at SemEval-2024 Task 6: Small LLMs can Accelerate Hallucination Detection with Weakly Supervised Data
Feb 20, 2024
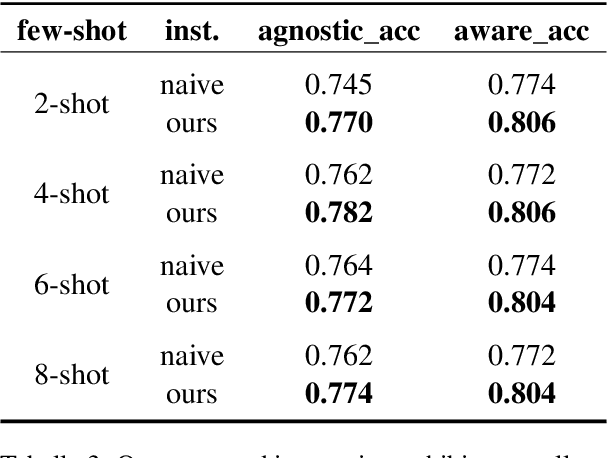
This paper mainly describes a unified system for hallucination detection of LLMs, which wins the second prize in the model-agnostic track of the SemEval-2024 Task 6, and also achieves considerable results in the model-aware track. This task aims to detect hallucination with LLMs for three different text-generation tasks without labeled training data. We utilize prompt engineering and few-shot learning to verify the performance of different LLMs on the validation data. Then we select the LLMs with better performance to generate high-quality weakly supervised training data, which not only satisfies the consistency of different LLMs, but also satisfies the consistency of the optimal LLM with different sampling parameters. Furthermore, we finetune different LLMs by using the constructed training data, and finding that a relatively small LLM can achieve a competitive level of performance in hallucination detection, when compared to the large LLMs and the prompt-based approaches using GPT-4.
Using Deep Mixture-of-Experts to Detect Word Meaning Shift for TempoWiC
Nov 07, 2022



This paper mainly describes the dma submission to the TempoWiC task, which achieves a macro-F1 score of 77.05% and attains the first place in this task. We first explore the impact of different pre-trained language models. Then we adopt data cleaning, data augmentation, and adversarial training strategies to enhance the model generalization and robustness. For further improvement, we integrate POS information and word semantic representation using a Mixture-of-Experts (MoE) approach. The experimental results show that MoE can overcome the feature overuse issue and combine the context, POS, and word semantic features well. Additionally, we use a model ensemble method for the final prediction, which has been proven effective by many research works.