 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoryArena: Benchmarking Agent Memory in Interdependent Multi-Session Agentic Tasks
Feb 18, 2026Existing evaluations of agents with memory typically assess memorization and action in isolation. One class of benchmarks evaluates memorization by testing recall of past conversations or text but fails to capture how memory is used to guide future decisions. Another class focuses on agents acting in single-session tasks without the need for long-term memory. However, in realistic settings, memorization and action are tightly coupled: agents acquire memory while interacting with the environment, and subsequently rely on that memory to solve future tasks. To capture this setting, we introduce MemoryArena, a unified evaluation gym for benchmarking agent memory in multi-session Memory-Agent-Environment loops. The benchmark consists of human-crafted agentic tasks with explicitly interdependent subtasks, where agents must learn from earlier actions and feedback by distilling experiences into memory, and subsequently use that memory to guide later actions to solve the overall task. MemoryArena supports evaluation across web navigation, preference-constrained planning, progressive information search, and sequential formal reasoning, and reveals that agents with near-saturated performance on existing long-context memory benchmarks like LoCoMo perform poorly in our agentic setting, exposing a gap in current evaluations for agents with memory.
DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
Taylor expansion-based Kolmogorov-Arnold network for blind image quality assessment
May 27, 2025
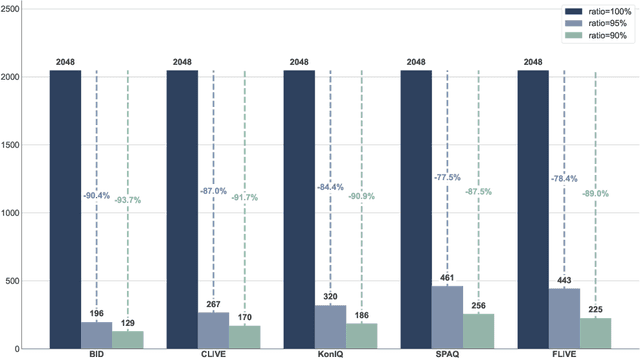
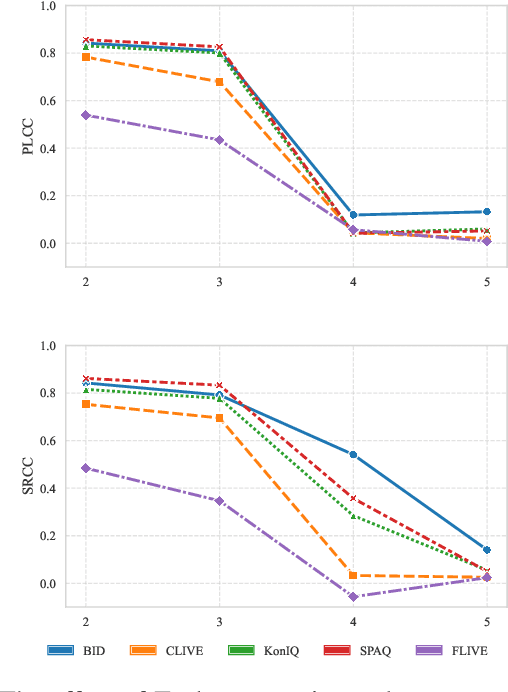

Kolmogorov-Arnold Network (KAN) has attracted growing interest for its strong function approximation capability. In our previous work, KAN and its variants were explored in score regression for blind image quality assessment (BIQA). However, these models encounter challenges when processing high-dimensional features, leading to limited performance gains and increased computational cost. To address these issues, we propose TaylorKAN that leverages the Taylor expansions as learnable activation functions to enhance local approximation capability. To improve the computational efficiency, network depth reduction and feature dimensionality compression are integrated into the TaylorKAN-based score regression pipeline. On five databases (BID, CLIVE, KonIQ, SPAQ, and FLIVE) with authentic distortions, extensive experiments demonstrate that TaylorKAN consistently outperforms the other KAN-related models, indicating that the local approximation via Taylor expansions is more effective than global approximation using orthogonal functions. Its generalization capacity is validated through inter-database experiments. The findings highlight the potential of TaylorKAN as an efficient and robust model for high-dimensional score regression.
ROUTE: Robust Multitask Tuning and Collaboration for Text-to-SQL
Dec 13, 2024



Despite the significant advancements in Text-to-SQL (Text2SQL) facilitated by large language models (LLMs), the latest state-of-the-art techniques are still trapped in the in-context learning of closed-source LLMs (e.g., GPT-4), which limits their applicability in open scenarios. To address this challenge, we propose a novel RObust mUltitask Tuning and collaboration mEthod (ROUTE) to improve the comprehensive capabilities of open-source LLMs for Text2SQL, thereby providing a more practical solution. Our approach begins with multi-task supervised fine-tuning (SFT) using various synthetic training data related to SQL generation. Unlike existing SFT-based Text2SQL methods, we introduced several additional SFT tasks, including schema linking, noise correction, and continuation writing. Engaging in a variety of SQL generation tasks enhances the model's understanding of SQL syntax and improves its ability to generate high-quality SQL queries. Additionally, inspired by the collaborative modes of LLM agents, we introduce a Multitask Collaboration Prompting (MCP) strategy. This strategy leverages collaboration across several SQL-related tasks to reduce hallucinations during SQL generation, thereby maximizing the potential of enhancing Text2SQL performance through explicit multitask capabilities. Extensive experiments and in-depth analyses have been performed on eight open-source LLMs and five widely-used benchmarks. The results demonstrate that our proposal outperforms the latest Text2SQL methods and yields leading performance.
Class Balance Matters to Active Class-Incremental Learning
Dec 09, 2024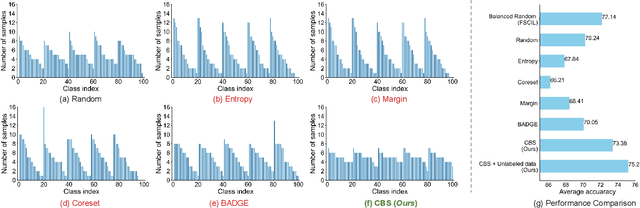
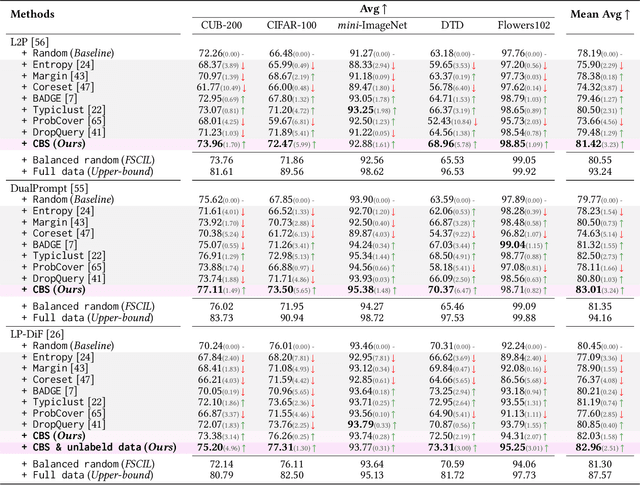

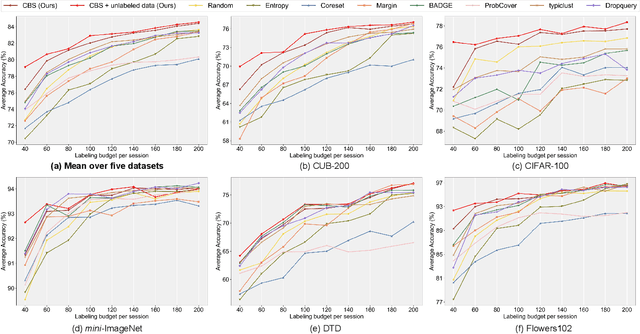
Few-Shot Class-Incremental Learning has shown remarkable efficacy in efficient learning new concepts with limited annotations. Nevertheless, the heuristic few-shot annotations may not always cover the most informative samples, which largely restricts the capability of incremental learner. We aim to start from a pool of large-scale unlabeled data and then annotate the most informative samples for incremental learning. Based on this premise, this paper introduces the Active Class-Incremental Learning (ACIL). The objective of ACIL is to select the most informative samples from the unlabeled pool to effectively train an incremental learner, aiming to maximize the performance of the resulting model. Note that vanilla active learning algorithms suffer from class-imbalanced distribution among annotated samples, which restricts the ability of incremental learning. To achieve both class balance and informativeness in chosen samples, we propose Class-Balanced Selection (CBS) strategy. Specifically, we first cluster the features of all unlabeled images into multiple groups. Then for each cluster, we employ greedy selection strategy to ensure that the Gaussian distribution of the sampled features closely matches the Gaussian distribution of all unlabeled features within the cluster. Our CBS can be plugged and played into those CIL methods which are based on pretrained models with prompts tunning technique. Extensive experiments under ACIL protocol across five diverse datasets demonstrate that CBS outperforms both random selection and other SOTA active learning approaches. Code is publicly available at https://github.com/1170300714/CBS.
Exploring Kolmogorov-Arnold networks for realistic image sharpness assessment
Sep 12, 2024
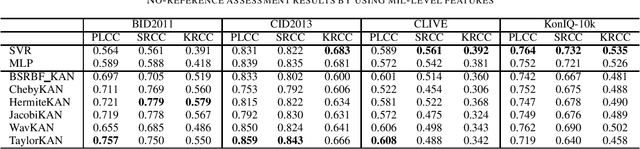
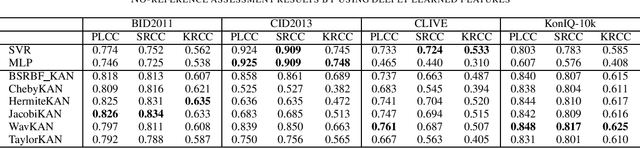
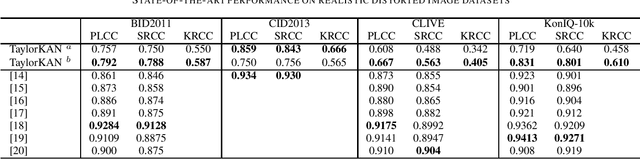
Score prediction is crucial in realistic image sharpness assessment after informative features are collected. Recently, Kolmogorov-Arnold networks (KANs) have been developed and witnessed remarkable success in data fitting. This study presents Taylor series based KAN (TaylorKAN). Then, different KANs are explored on four realistic image databases (BID2011, CID2013, CLIVE, and KonIQ-10k) for score prediction by using 15 mid-level features and 2048 high-level features. When setting support vector regression as the baseline, experimental results indicate KANs are generally better or competitive, TaylorKAN is the best on three databases using mid-level feature input, while KANs are inferior on CLIVE when high-level features are used. This is the first study that explores KANs for image quality assessment. It sheds lights on how to select and improve KANs on related tasks.
Category-Extensible Out-of-Distribution Detection via Hierarchical Context Descriptions
Jul 23, 2024The key to OOD detection has two aspects: generalized feature representation and precise category description. Recently, vision-language models such as CLIP provide significant advances in both two issues, but constructing precise category descriptions is still in its infancy due to the absence of unseen categories. This work introduces two hierarchical contexts, namely perceptual context and spurious context, to carefully describe the precise category boundary through automatic prompt tuning. Specifically, perceptual contexts perceive the inter-category difference (e.g., cats vs apples) for current classification tasks, while spurious contexts further identify spurious (similar but exactly not) OOD samples for every single category (e.g., cats vs panthers, apples vs peaches). The two contexts hierarchically construct the precise description for a certain category, which is, first roughly classifying a sample to the predicted category and then delicately identifying whether it is truly an ID sample or actually OOD. Moreover, the precise descriptions for those categories within the vision-language framework present a novel application: CATegory-EXtensible OOD detection (CATEX). One can efficiently extend the set of recognizable categories by simply merging the hierarchical contexts learned under different sub-task settings. And extensive experiments are conducted to demonstrate CATEX's effectiveness, robustness, and category-extensibility. For instance, CATEX consistently surpasses the rivals by a large margin with several protocols on the challenging ImageNet-1K dataset. In addition, we offer new insights on how to efficiently scale up the prompt engineering in vision-language models to recognize thousands of object categories, as well as how to incorporate large language models (like GPT-3) to boost zero-shot applications. Code will be made public soon.
Rethinking Out-of-Distribution Detection on Imbalanced Data Distribution
Jul 23, 2024Detecting and rejecting unknown out-of-distribution (OOD) samples is critical for deployed neural networks to void unreliable predictions. In real-world scenarios, however, the efficacy of existing OOD detection methods is often impeded by the inherent imbalance of in-distribution (ID) data, which causes significant performance decline. Through statistical observations, we have identified two common challenges faced by different OOD detectors: misidentifying tail class ID samples as OOD, while erroneously predicting OOD samples as head class from ID. To explain this phenomenon, we introduce a generalized statistical framework, termed ImOOD, to formulate the OOD detection problem on imbalanced data distribution. Consequently, the theoretical analysis reveals that there exists a class-aware bias item between balanced and imbalanced OOD detection, which contributes to the performance gap. Building upon this finding, we present a unified training-time regularization technique to mitigate the bias and boost imbalanced OOD detectors across architecture designs. Our theoretically grounded method translates into consistent improvements on the representative CIFAR10-LT, CIFAR100-LT, and ImageNet-LT benchmarks against several state-of-the-art OOD detection approaches. Code will be made public soon.
ESOD: Efficient Small Object Detection on High-Resolution Images
Jul 23, 2024



Enlarging input images is a straightforward and effective approach to promote small object detection. However, simple image enlargement is significantly expensive on both computations and GPU memory. In fact, small objects are usually sparsely distributed and locally clustered. Therefore, massive feature extraction computations are wasted on the non-target background area of images. Recent works have tried to pick out target-containing regions using an extra network and perform conventional object detection, but the newly introduced computation limits their final performance. In this paper, we propose to reuse the detector's backbone to conduct feature-level object-seeking and patch-slicing, which can avoid redundant feature extraction and reduce the computation cost. Incorporating a sparse detection head, we are able to detect small objects on high-resolution inputs (e.g., 1080P or larger) for superior performance. The resulting Efficient Small Object Detection (ESOD) approach is a generic framework, which can be applied to both CNN- and ViT-based detectors to save the computation and GPU memory costs. Extensive experiments demonstrate the efficacy and efficiency of our method. In particular, our method consistently surpasses the SOTA detectors by a large margin (e.g., 8% gains on AP) on the representative VisDrone, UAVDT, and TinyPerson datasets. Code will be made public soon.
Educating LLMs like Human Students: Structure-aware Injection of Domain Knowledge
Jul 23, 2024



This paper presents a pioneering methodology, termed StructTuning, to efficiently transform foundation Large Language Models (LLMs) into domain specialists. It significantly minimizes the training corpus requirement to a mere 0.3% while achieving an impressive 50% of traditional knowledge injection performance. Our method is inspired by the educational processes for human students, particularly how structured domain knowledge from textbooks is absorbed and then applied to tackle real-world challenges through specific exercises. Based on this, we propose a novel two-stage knowledge injection strategy: Structure-aware Continual Pre-Training (SCPT) and Structure-aware Supervised Fine-Tuning (SSFT). In the SCPT phase, we organize the training data into an auto-generated taxonomy of domain knowledge, enabling LLMs to effectively memorize textual segments linked to specific expertise within the taxonomy's architecture. Subsequently, in the SSFT phase, we explicitly prompt models to reveal the underlying knowledge structure in their outputs, leveraging this structured domain insight to address practical problems adeptly. Our ultimate method has undergone extensive evaluations across model architectures and scales, using closed-book question-answering tasks on LongBench and MMedBench datasets. Remarkably, our method matches 50% of the improvement displayed by the state-of-the-art MMedLM2 on MMedBench, but with only 0.3% quantity of the training corpus. This breakthrough showcases the potential to scale up our StructTuning for stronger domain-specific LLMs. Code will be made public soon.