 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Text-Image Fusion Method with Data Augmentation Capabilities for Referring Medical Image Segmentation
Oct 14, 2025



Deep learning relies heavily on data augmentation to mitigate limited data, especially in medical imaging. Recent multimodal learning integrates text and images for segmentation, known as referring or text-guided image segmentation. However, common augmentations like rotation and flipping disrupt spatial alignment between image and text, weakening performance. To address this, we propose an early fusion framework that combines text and visual features before augmentation, preserving spatial consistency. We also design a lightweight generator that projects text embeddings into visual space, bridging semantic gaps. Visualization of generated pseudo-images shows accurate region localization. Our method is evaluated on three medical imaging tasks and four segmentation frameworks, achieving state-of-the-art results. Code is publicly available on GitHub: https://github.com/11yxk/MedSeg_EarlyFusion.
Object-Level Verbalized Confidence Calibration in Vision-Language Models via Semantic Perturbation
Apr 21, 2025



Vision-language models (VLMs) excel in various multimodal tasks but frequently suffer from poor calibration, resulting in misalignment between their verbalized confidence and response correctness. This miscalibration undermines user trust, especially when models confidently provide incorrect or fabricated information. In this work, we propose a novel Confidence Calibration through Semantic Perturbation (CSP) framework to improve the calibration of verbalized confidence for VLMs in response to object-centric queries. We first introduce a perturbed dataset where Gaussian noise is applied to the key object regions to simulate visual uncertainty at different confidence levels, establishing an explicit mapping between visual ambiguity and confidence levels. We further enhance calibration through a two-stage training process combining supervised fine-tuning on the perturbed dataset with subsequent preference optimization. Extensive experiments on popular benchmarks demonstrate that our method significantly improves the alignment between verbalized confidence and response correctness while maintaining or enhancing overall task performance. These results highlight the potential of semantic perturbation as a practical tool for improving the reliability and interpretability of VLMs.
Enhancing Depression Detection with Chain-of-Thought Prompting: From Emotion to Reasoning Using Large Language Models
Feb 09, 2025Depression is one of the leading causes of disability worldwide, posing a severe burden on individuals, healthcare systems, and society at large. Recent advancements in Large Language Models (LLMs) have shown promise in addressing mental health challenges, including the detection of depression through text-based analysis. However, current LLM-based methods often struggle with nuanced symptom identification and lack a transparent, step-by-step reasoning process, making it difficult to accurately classify and explain mental health conditions. To address these challenges, we propose a Chain-of-Thought Prompting approach that enhances both the performance and interpretability of LLM-based depression detection. Our method breaks down the detection process into four stages: (1) sentiment analysis, (2) binary depression classification, (3) identification of underlying causes, and (4) assessment of severity. By guiding the model through these structured reasoning steps, we improve interpretability and reduce the risk of overlooking subtle clinical indicators. We validate our method on the E-DAIC dataset, where we test multiple state-of-the-art large language models. Experimental results indicate that our Chain-of-Thought Prompting technique yields superior performance in both classification accuracy and the granularity of diagnostic insights, compared to baseline approaches.
High-Quality Data Augmentation for Low-Resource NMT: Combining a Translation Memory, a GAN Generator, and Filtering
Aug 22, 2024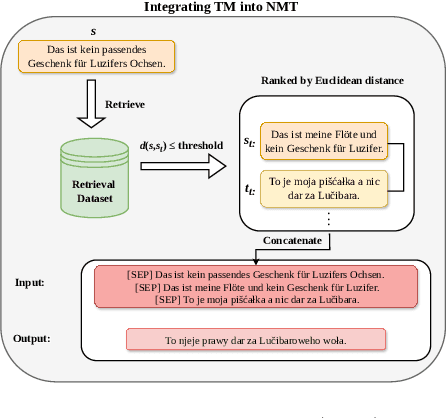
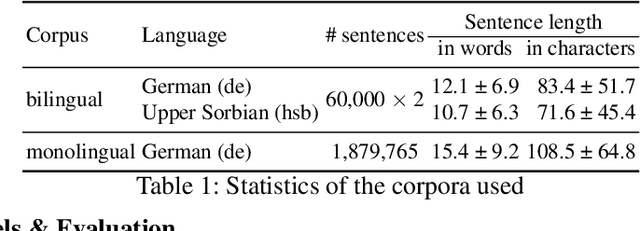
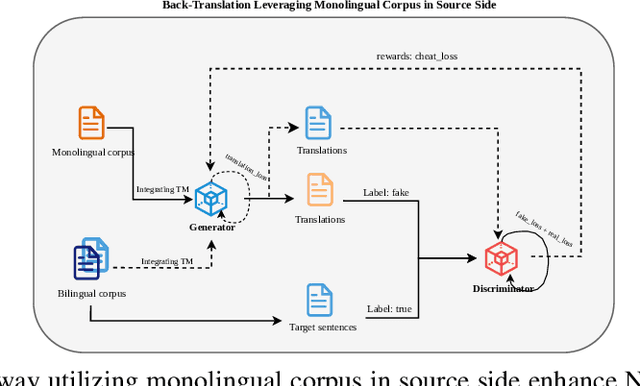
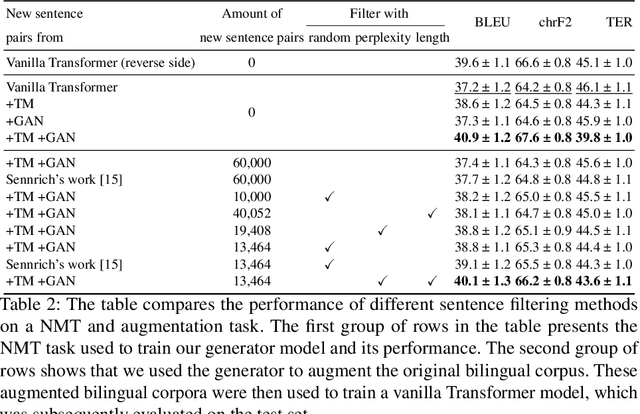
Back translation, as a technique for extending a dataset, is widely used by researchers in low-resource language translation tasks. It typically translates from the target to the source language to ensure high-quality translation results. This paper proposes a novel way of utilizing a monolingual corpus on the source side to assist Neural Machine Translation (NMT) in low-resource settings. We realize this concept by employing a Generative Adversarial Network (GAN), which augments the training data for the discriminator while mitigating the interference of low-quality synthetic monolingual translations with the generator. Additionally, this paper integrates Translation Memory (TM) with NMT, increasing the amount of data available to the generator. Moreover, we propose a novel procedure to filter the synthetic sentence pairs during the augmentation process, ensuring the high quality of the data.
Towards Analyzing and Mitigating Sycophancy in Large Vision-Language Models
Aug 21, 2024



Large Vision-Language Models (LVLMs) have shown significant capability in vision-language understanding. However, one critical issue that persists in these models is sycophancy, which means models are unduly influenced by leading or deceptive prompts, resulting in biased outputs and hallucinations. Despite the progress in LVLMs, evaluating and mitigating sycophancy is yet much under-explored. In this work, we fill this gap by systematically analyzing sycophancy on various VL benchmarks with curated leading queries and further proposing a text contrastive decoding method for mitigation. While the specific sycophantic behavior varies significantly among models, our analysis reveals the severe deficiency of all LVLMs in resilience of sycophancy across various tasks. For improvement, we propose Leading Query Contrastive Decoding (LQCD), a model-agnostic method focusing on calibrating the LVLMs' over-reliance on leading cues by identifying and suppressing the probabilities of sycophancy tokens at the decoding stage. Extensive experiments show that LQCD effectively mitigate sycophancy, outperforming both prompt engineering methods and common methods for hallucination mitigation. We further demonstrate that LQCD does not hurt but even slightly improves LVLMs' responses to neutral queries, suggesting it being a more effective strategy for general-purpose decoding but not limited to sycophancy.
CARES: A Comprehensive Benchmark of Trustworthiness in Medical Vision Language Models
Jun 10, 2024
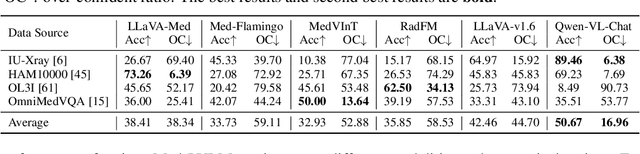
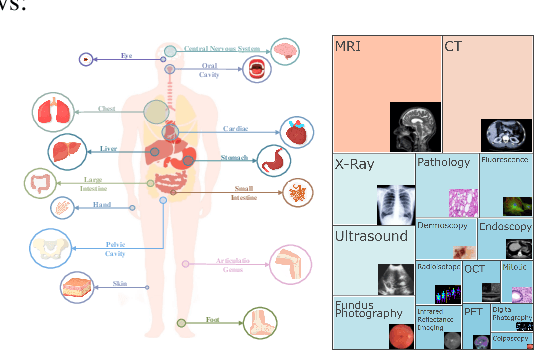
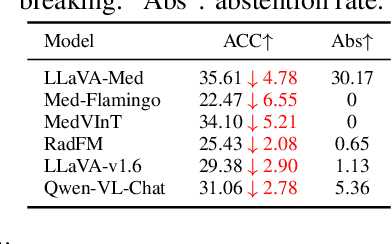
Artificial intelligence has significantly impacted medical applications, particularly with the advent of Medical Large Vision Language Models (Med-LVLMs), sparking optimism for the future of automated and personalized healthcare. However, the trustworthiness of Med-LVLMs remains unverified, posing significant risks for future model deployment. In this paper, we introduce CARES and aim to comprehensively evaluate the Trustworthiness of Med-LVLMs across the medical domain. We assess the trustworthiness of Med-LVLMs across five dimensions, including trustfulness, fairness, safety, privacy, and robustness. CARES comprises about 41K question-answer pairs in both closed and open-ended formats, covering 16 medical image modalities and 27 anatomical regions. Our analysis reveals that the models consistently exhibit concerns regarding trustworthiness, often displaying factual inaccuracies and failing to maintain fairness across different demographic groups. Furthermore, they are vulnerable to attacks and demonstrate a lack of privacy awareness. We publicly release our benchmark and code in https://github.com/richard-peng-xia/CARES.