 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Analogical Inference from Boolean to Continuous Domains
Nov 13, 2025Analogical reasoning is a powerful inductive mechanism, widely used in human cognition and increasingly applied in artificial intelligence. Formal frameworks for analogical inference have been developed for Boolean domains, where inference is provably sound for affine functions and approximately correct for functions close to affine. These results have informed the design of analogy-based classifiers. However, they do not extend to regression tasks or continuous domains. In this paper, we revisit analogical inference from a foundational perspective. We first present a counterexample showing that existing generalization bounds fail even in the Boolean setting. We then introduce a unified framework for analogical reasoning in real-valued domains based on parameterized analogies defined via generalized means. This model subsumes both Boolean classification and regression, and supports analogical inference over continuous functions. We characterize the class of analogy-preserving functions in this setting and derive both worst-case and average-case error bounds under smoothness assumptions. Our results offer a general theory of analogical inference across discrete and continuous domains.
High-Quality Data Augmentation for Low-Resource NMT: Combining a Translation Memory, a GAN Generator, and Filtering
Aug 22, 2024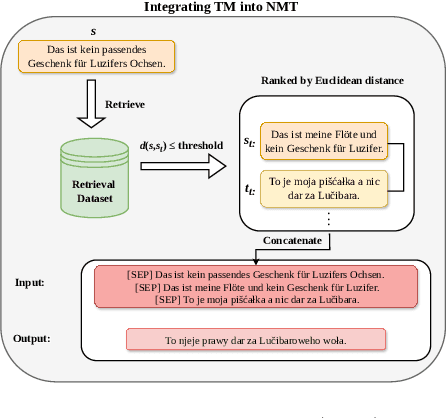
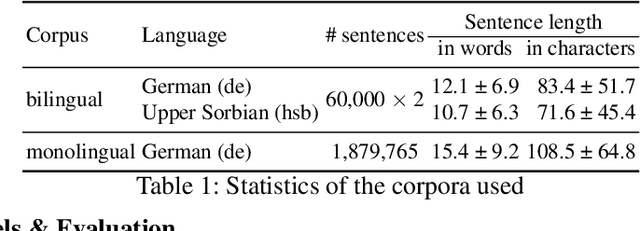
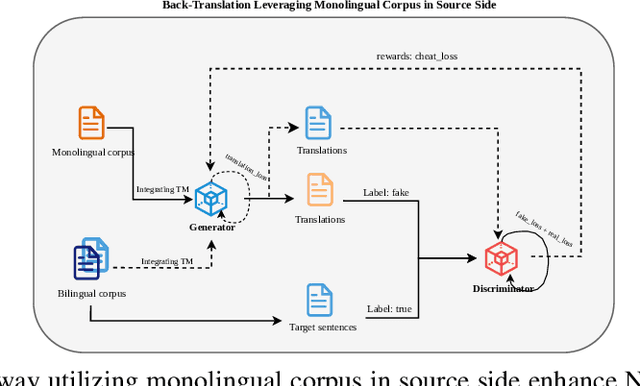
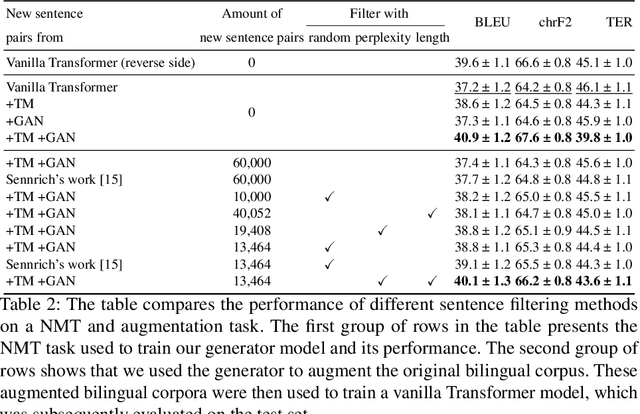
Back translation, as a technique for extending a dataset, is widely used by researchers in low-resource language translation tasks. It typically translates from the target to the source language to ensure high-quality translation results. This paper proposes a novel way of utilizing a monolingual corpus on the source side to assist Neural Machine Translation (NMT) in low-resource settings. We realize this concept by employing a Generative Adversarial Network (GAN), which augments the training data for the discriminator while mitigating the interference of low-quality synthetic monolingual translations with the generator. Additionally, this paper integrates Translation Memory (TM) with NMT, increasing the amount of data available to the generator. Moreover, we propose a novel procedure to filter the synthetic sentence pairs during the augmentation process, ensuring the high quality of the data.
Any four real numbers are on all fours with analogy
Jul 26, 2024



This work presents a formalization of analogy on numbers that relies on generalized means. It is motivated by recent advances in artificial intelligence and applications of machine learning, where the notion of analogy is used to infer results, create data and even as an assessment tool of object representations, or embeddings, that are basically collections of numbers (vectors, matrices, tensors). This extended analogy use asks for mathematical foundations and clear understanding of the notion of analogy between numbers. We propose a unifying view of analogies that relies on generalized means defined in terms of a power parameter. In particular, we show that any four increasing positive real numbers is an analogy in a unique suitable power. In addition, we show that any such analogy can be reduced to an equivalent arithmetic analogy and that any analogical equation has a solution for increasing numbers, which generalizes without restriction to complex numbers. These foundational results provide a better understanding of analogies in areas where representations are numerical.
Fast BTG-Forest-Based Hierarchical Sub-sentential Alignment
Nov 20, 2017

In this paper, we propose a novel BTG-forest-based alignment method. Based on a fast unsupervised initialization of parameters using variational IBM models, we synchronously parse parallel sentences top-down and align hierarchically under the constraint of BTG. Our two-step method can achieve the same run-time and comparable translation performance as fast_align while it yields smaller phrase tables. Final SMT results show that our method even outperforms in the experiment of distantly related languages, e.g., English-Japanese.
An Investigation of the Sampling-Based Alignment Method and Its Contributions
Aug 21, 2013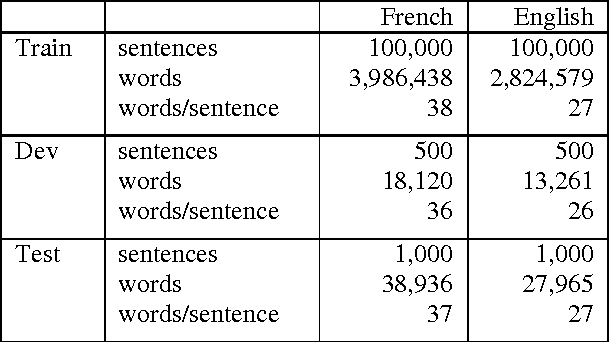
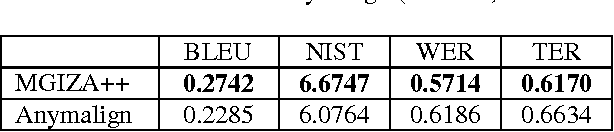

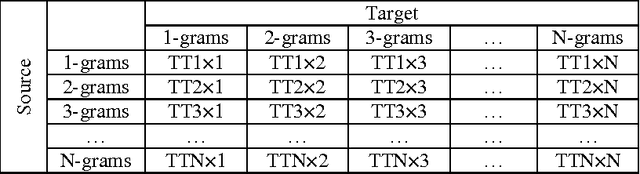
By investigating the distribution of phrase pairs in phrase translation tables, the work in this paper describes an approach to increase the number of n-gram alignments in phrase translation tables output by a sampling-based alignment method. This approach consists in enforcing the alignment of n-grams in distinct translation subtables so as to increase the number of n-grams. Standard normal distribution is used to allot alignment time among translation subtables, which results in adjustment of the distribution of n- grams. This leads to better evaluation results on statistical machine translation tasks than the original sampling-based alignment approach. Furthermore, the translation quality obtained by merging phrase translation tables computed from the sampling-based alignment method and from MGIZA++ is examined.
* 11 pages